By: Oluwademilade Bolatimi
Abstract:
This paper aims to test the effectiveness of applying different machine learning models to accurately detect a person’s ethnicity based on their facial image. This is important due to the lack of research that has been done on that specific biometric with other biometrics such as age and gender being given greater attention. There will also be a study of age and gender performance with the models on similar data to see how ethnicity compares with them. The models selected for comparison will be a support vector machine, a convolutional neural network in ResNet50, and the light Gradient Boosting algorithm. The model with the highest scores of accuracy, precision, f1, and recall overall will be selected to be used to test facial images not involved in the building of the model to see the effectiveness of the model.
Introduction
This research aims to use different machine learning models for comparison purposes to see if we can reach a high enough accuracy in detecting an individual’s ethnicity based on an image of them. Similar works around this topic, such as Owusu et al and Kremic et al, show a baseline good accuracy score should be around 95%. There will also be classifications of other biometrics such as age and gender to see the ease of classifying ethnicity as compared to the other biometrics. This research is being done because there has recently been significant progress in classifying different biometrics such as age and gender, but “the recognition of ethnicity has not received the same attention from the scientific community” (Greco). This is concerning because of the racial bias of facial recognition given to specific races more than others. An example of this is seen in Marcos et al. They “noticed important biases, thus leading to higher error rates when images were taken from black people” (Ferreira) and how there is a “risk of deploying computational software that might affect minority groups that are historically neglected” (Ferreira). If we are able to determine the ethnicity of a person we can make accommodations for the current biases against those minorities with the aim of improving the overall facial recognition software. The paper will first give details about the dataset used and how it will be manipulated for my research. It will then move on to the different models to be used. The idea of the various models suitable for this sort of classification comes from past research such as Chen et al. They use the k-nearest Neighbor algorithm, a Support Vector Machine (SVM), a two-layer neural network, and a convolutional neural network (CNN) for comparison. After this is done we will then use confusion matrix diagrams to see how accurately the models performed and choose our best model with the highest metrics as measurement.
Link to Gitlab:
https://code.cs.earlham.edu/dpbolat19/cs488/-/tree/main/
Link to Paper:
https://drive.google.com/file/d/1VgNjHnovc3njJp3GLryAo7uOlf3I2nxB/view?usp=sharing
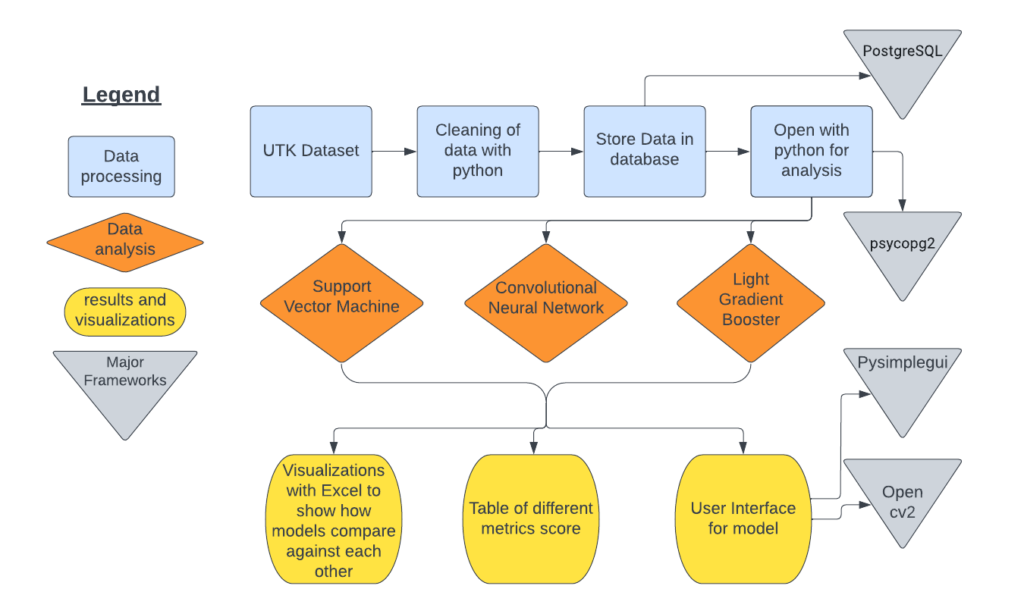
Software Architecture Diagram
Poster:

link to poster
https://drive.google.com/file/d/14HiMgupFCenqcPFkfxlJiEmRnlsK51cL/view?usp=sharing
Software Demonstration Video:
Interface of Model (CNN)
