By: Oluwademilade Bolatimi
Introduction:
Learning a language can be one of the most difficult challenges that a person can do. It can involve learning new alphabets, characters, conjugations, and pronunciations. Another big issue that arises with learning new languages is in fact that people do not know what these languages are. These types of scenarios occur in a number of different languages but a specific study and focus on African languages shows just how neglected some of them are in literature and academics. As the literature on the next page will show there is a strong point for these languages to be given more recognition because not only are they respectable languages on their own, but they are also very useful tools that can be used in knowledge and literacy. Some of these languages even have their own specific ways of expression that if the rest of the world were able to see and use would make an improvement in global literacy levels. The first step in reaching this goal can be done through the identification of these specific languages. This will be done by training different Machine learning models using text data for each of these languages. After training these different models we will use the model which scores the highest metrics as our option. The main metrics used will be accuracy, precision, f-1, and recall score.
Abstract:
This project will use a machine learning model to be able to identify specific African languages through data reading and continuous training until a high enough accuracy is reached. This will help in determining whether the correct African language can be identified. This will be a start to helping people identify movies or series spoken in these specific languages which can be used for further comprehension and learning of them. The project further focuses on how some African languages are neglected and not given enough research in the current world. There will be a comparison of different models to test out how their metrics compare with each other. This will help in choosing the final model that will be used in the language classification. After the best metrics are distinguished with the best model then a model is used for further research to improve the software aspects of African language classification.
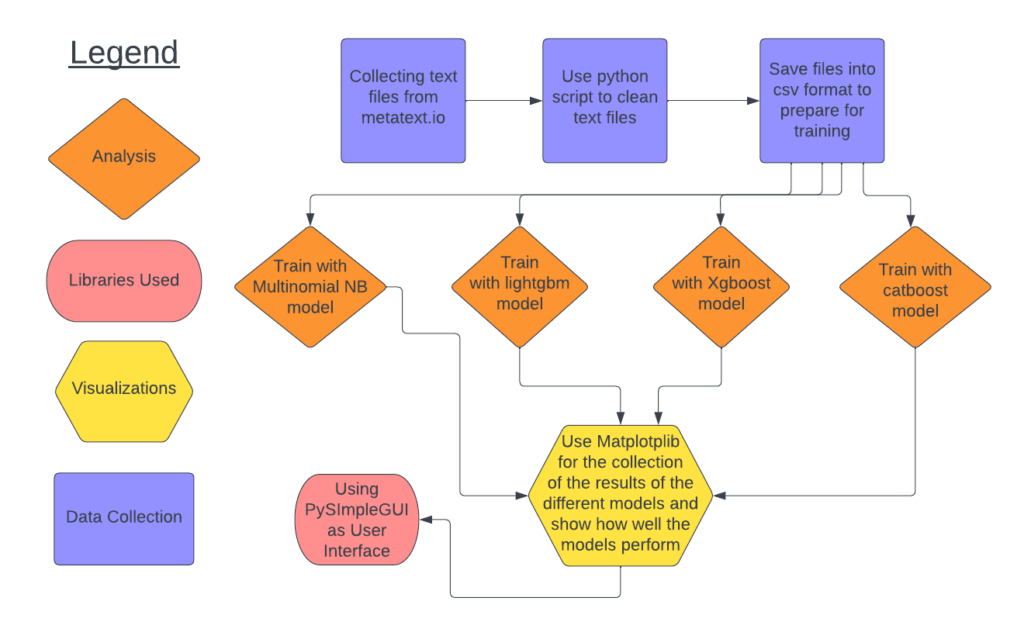
Software Architecture Diagram:
Gitlab:
https://code.cs.earlham.edu/dpbolat19/data-science-capstone/-/tree/main/
Demonstration Video:
Poster:

Link to Paper:
https://drive.google.com/file/d/1CPoOJWBfP4mrXvUQZ_nC5iG76i6ECQgu/view?usp=sharing
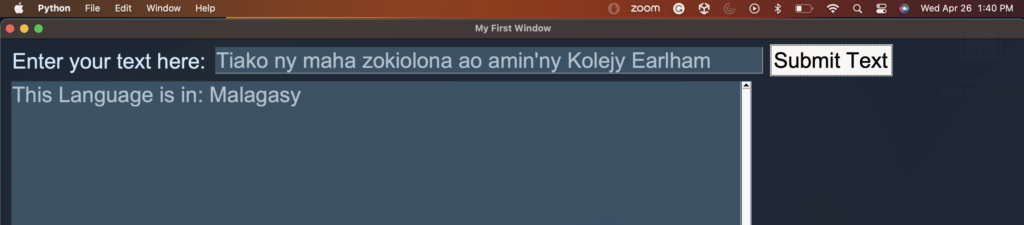
Interface of Model (Multinomial NB):