Introduction
Hello! I’m Darab Qasimi, a senior double majoring in Computer Science and Data Science. Data analysis is the skill that can give one the ability to give meaning to data and let it speak for itself. The following content explains my project about credit card fraud detection using data analysis and Random Forest Decision Tree (RFDT), which is a machine learning algorithm. The motivation behind the project is my curiosity for data analysis and wanting to use data to tell a story and prevent fraud.
Abstract
This project of detecting fraudulent activities in credit cards aims to classify transactions as authentic or non-authentic. The project is mainly focused on detecting fraudulent activities. Credit card fraud often happens due to theft, fake copy, identity theft, and other forms. Credit card fraud predictor variables are time, cash amount, transaction class, location, etc. In the real world, if any of the predictor variables are not typical such as location or amount, then there is a red flag raised by the fraud detection algorithms. Some American credit card companies require customers to inform the bank about their travel plans to prevent customers’ transactions from getting red-flagged by fraud detection algorithms. Another example of a red flag to credit card fraud detection algorithms is the amount involved in transactions. Most bank institutions have daily spending limits on credit cards. Suppose a transaction goes beyond the limit, which may be unlikely. In that case, that’s most likely a sign of fraud because customers are informed about their spending limit by their bank institutions when their account is opened, so if there is an excess, there is a chance it’s unauthentic. Although there are cases where a customer might not know their spending limit and go over, in that case, they will have to confirm the big transaction with their financial institution. One of the behaviors of detecting fraudulent activities in this project is looking at cases such as the above examples.
For this project, the aim of using RFDT is to maximize the re- results of detecting fraud in credit cards by outputting a more robust decision from so many decision trees. In the context of this project, after providing the dataset to the program, the RFDT algorithm will divide the data recursively among many decision trees. In the decision-making process, each tree will come up with a decision, and in the end, only the one with the most votes will produce a result. So, the RFDT algorithm is the step to processing data and recursively making decisions until it arrives at the best decision and decides if a credit card activity is fraudulent. This project is about credit card fraud detection, and machine learning methods such as the RFDT algorithm and bagging methods are used to analyze a dataset.
Project Implementation on GitHub: https://github.com/daqasimi18/Data-Science-Capstone-Project.git
Project Analysis: https://drive.google.com/drive/folders/1WDrZCnWJoTnNs2qwNse_Ylia066wSzH-?usp=sharing
Data Architecture
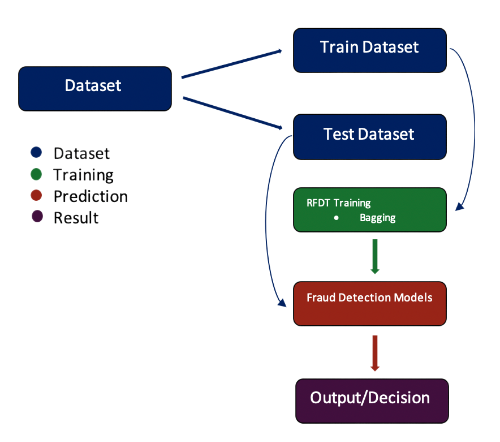
The figure on the left demonstrates the Data Architecture for the credit card fraud detection project. The training dataset contains 284,807 transactions of European credit card holders from which 492 are fraud. As shown in the figure on the left, the main dataset is divided in two parts where 70% of the dataset is used to train the RFDT model, and the rest of the 30% is used to check the model’s accuracy.
Demonstration Video
Poster
The following poster demonstrates how credit card fraud is detected. The Random Forest and Implementation sections contain information about how this fraud detection project uses RFDT to conclude a result. Training with the current dataset, the program has about 99% accuracy in detecting fraud from credit card transactions.
