Abstract
Writer identification based on handwriting plays an important role in forensic analysis of the documents. Convolutional Neural Networks have been successfully applied to this problem throughout the last decade. Most of the research that has been done in this area has concentrated on extracting local features from handwriting samples and then combining them into global descriptors for writer retrieval. Extracting local features from small patches of handwriting samples is a reasonable choice considering the lack of big training datasets. However, the methods for aggregating local features are not perfect and do not take into account the spatial relationship between small patches of handwriting. This research aims to train a CNN with triplet loss function to extract global feature vectors from images of handwritten text directly, eliminating the intermediate step involving local features. Extracting global features from handwriting samples is not a novel idea, but this approach has never been combined with triplet architecture. A data augmentation method is employed because training a CNN to learn the global descriptors requires a large amount of training data. The model is trained and tested on CVL handwriting dataset, using leave-one-out cross-validation method to test the soft top-N, hard top-N performance.
Software Architecture
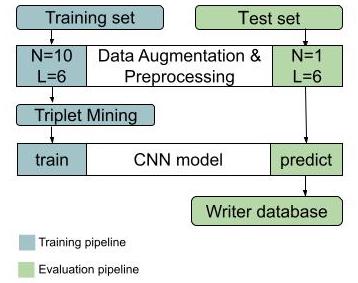
I’m using CVL writer database to train the model. All handwriting samples go through the data augmentation and pre-processing step to standardize the input for CNN. The samples in the training set get augmented, whereas only one page is produced per sample for the test set. The triplets of samples are chosen from each batch to train the CNN. The output of the CNN is a 256D vector. In order to evaluate the model, we build a writer database for samples in the test set.

Each handwriting sample goes through the same set of steps:
1. Original handwriting sample.
2. Sample is segmented into words.
3. The words from a single sample are randomly permuted into a line of handwriting. The words are centered vertically.
4. Step 2 is repeated L times to get L lines of handwriting. These lines are concatenated vertically to produce a page.
5. A page is then broken up into non-overlapping square patches. The remainder of the page is discarded. The resulting patches are resized to 224×224 pixels.
6. Steps (4) and (5) are repeated N times.
7. Finally we apply binarization. The patches are thresholded using adaptive Gaussian Thresholding with 37×37 kernel.
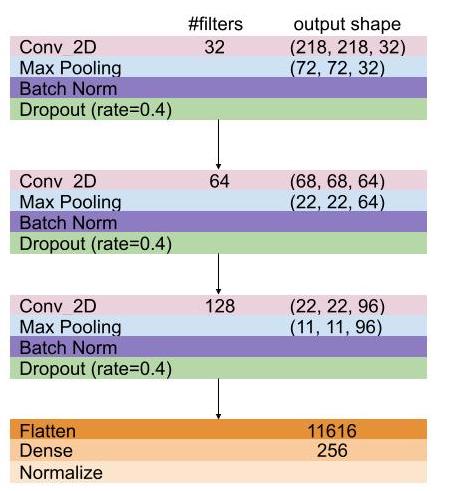
The CNN model consists of 3 convolutional blocks followed by a single fully connected layer. Each convolutional block includes a 2D convolutional, batch normalization, max pooling and dropout layers. The final final 256D output vector is normalized. I implemented this CNN framework in keras with tensorflow backend.
The model was trained for 15 epochs with batch gradient descend and Adam optimizer, with an initial learning rate of 3e-4. 10 epochs of training with semi-hard negative triplet mining was followed by 5 epochs of hard negative triplet mining.