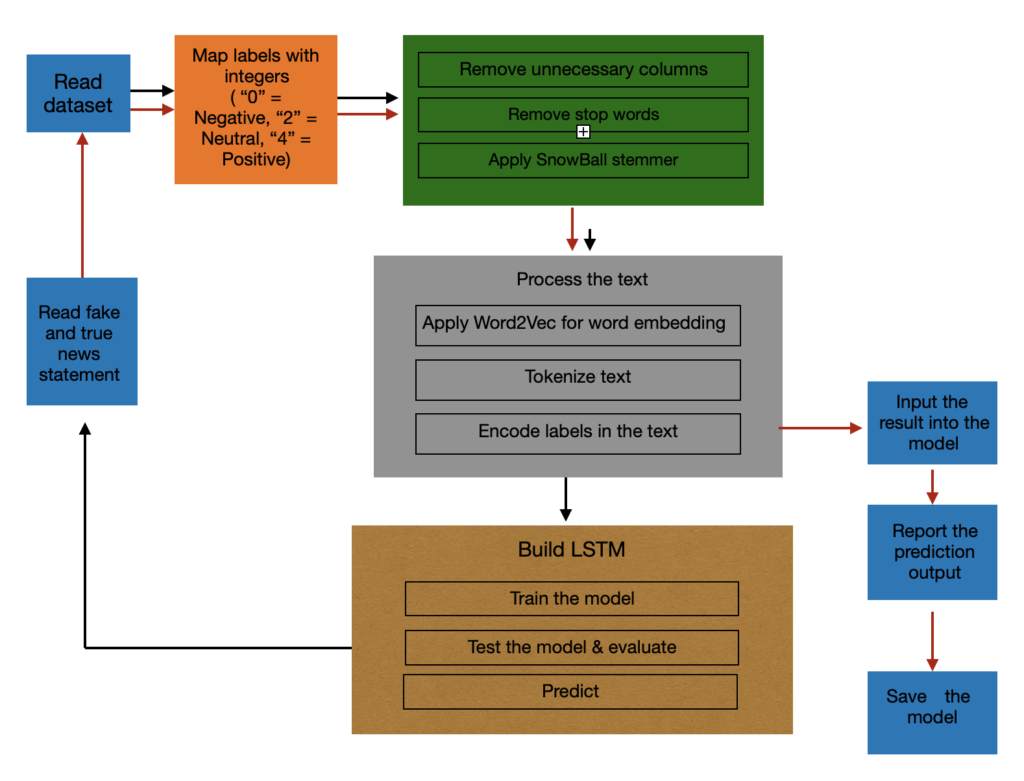
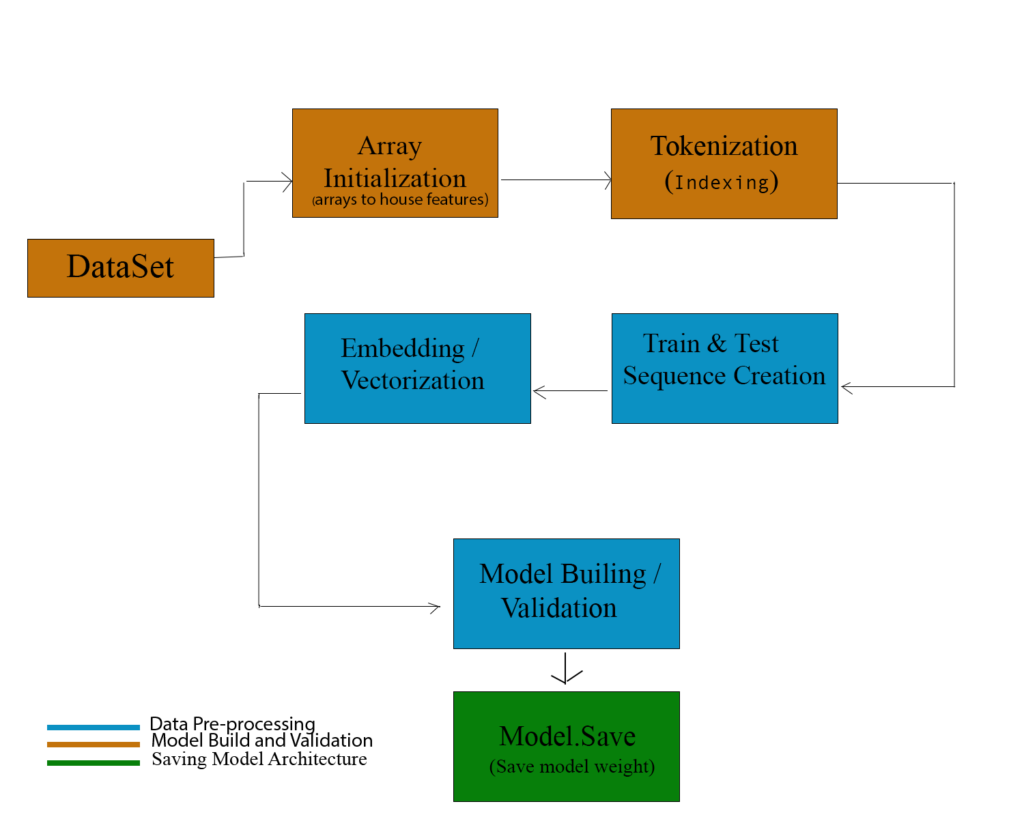
Artificial Neural Networks in Image Processing for Early Detection of Breast Cancer
MEHDY, M. M., P. Y. NG, E. F. SHAIR, N. I. SALEH, CHANDIMA GOMES.2017. Artificial neural networks in image processing for early detection of breast cancer. Computational and mathematical methods in medicine.
The paper examines four different approaches to breast cancer in medicine ( MRI, IR< Mammography and ultrasound). For the classification, the paper looks at three different techniques: Support Vector Machine, Method based on rule ( decision tree and rough sets), Artificial Neural Network. The paper also divided the types of data that need to be classified: calcification and non calcification, benign and malignant, dense and normal breast, tumorous and non tumorous. The paper addressed different types of Neural networks that exist and have been used in related works in Breast Cancer Detection : Feed-forward backpropagation, Convolution Neural Networks.
NOTES:
- The paper looks/reviews into four different applications of medical imaging: MRI, IR, mammography and ultrasound for the cause of identifying breast cancer early
- It addresses the use of hybrid Neural Networks in breast cancer detection
- Investigates artificial neural networks in the processing of images
- Reviews three types of classification decisions for image feature selection and focuses on one (ANN- artificial neural network):Support Vector Machine, method based on rule ( decision tree and rough sets), artificial neural network
- Subtle appearances and ambiguous margins are the obstacles for differentiating abnormalities if present in breast cancer using mammogram
- Artificial Neural network is used in CAD(computer-aided diagnosis) allowing to overcome difficulties of image processing by radiologists. ANN has two applications in CAD: direct application of classifier at the image data region of interest (ROI) and using preprocessed image signals analyzing the extracted features of an image
- Look into Dhawan et al.: used 3-layer neural network and backpropagation algorithm for image structure feature identification
- Image processing includes various techniques and one of them is the image segmentation. It detects small, local and bright spots on a raw image.
- Image segmentation reaches high accuracy by relying on a set of labeled test images( true positives(TP), false positives(FP)).
- The technique used in this paper for pattern classification is called on cascade correlation (CC)
- Look into: Sinin and Vijai – Grey-Level Co Occurrence Matrix(GLCM)
- Ultrasound – creating three-dimensional ultrasound imaging giving in debt information on breast lesion
- MRI imaging – recommended way of soft tissue recognition.
- The types of data that is needed to classify in this paper is of these types: calcification and non calcification, benign and malignant, dense and normal breast, tumorous and non tumorous.
Breast Cancer detection using deep convolutional neural networks and support vector machines
RAGAB, DINA A., MAHA SHARKAS, STEPHEN MARSHALL, JINCHANG REN.2019.Breast cancer detection using deep convolutional neural networks and support vector machines. PeerJ ,7(e6201).
This paper, for breast cancer detection, is using CAD (Computer Aided Detection) classifier to differentiate benign and malignant mass tumors in breast mammography. It touches upon two techniques used in CAD – manual determination of the region of interest and technique of threshold based on the region. For the feature extract, the paper is using DCNN (Deep Convolutional Neural Network), allowing accuracy of 71.01%. Look up AlexNet for more reference and background on DCNN. Another classifier that the paper explores includes Support Vector Machine(which appears to be very useful in fake news detection as well and is very common in cancer detection techniques). This paper, in contrast to other papers in this field, focuses on getting a better image segmentation by increasing the contrast, suppressing noise to reach higher accuracy of breast cancer detection. Look up other image enhancement techniques that are referenced in this paper (E.g. Adaptive COntrast Enhancement, Contrast-limited Adaptive Histogram Equalization).
NOTES:
- Uses CAD (computer aided detection system to classify benign and malignant mass tumors in breast mammography images
- As the other , this paper as well touches upon the two techniques of CAD system – manual determination of the region of interest while the second approach is different: technique of threshold and region based
- The types of neural network that this paper is looking at is DCNN – deep convolutional neural network to extract features.
- Look AlexNet for DCNN
- Touches upon support vector machine (SVM) classifier for higher accuracy
- Using datasets: (1) the digital database for screening mammography (DDSM); and (2) the Curated Breast Imaging Subset of DDSM (CBIS-DDSM)
- Uses data augmentation to get bigger input data taht is based on the original data – uses rotation type of data augmentation
- The accuracy of this approach DCNN is 71.01%
- The process of CAD systems consists of steps: image enhancement, image segmentation, feature extraction, feature classification, evaluation for the classifier
- This paper, in contrast to the one previously mentioned, touches upon getting a better image for segmentation – it enhances images by increasing the contrast, suppressing noise for a better and accurate breast cancer determination
- Look these image enhancement techniques: adaptive contrast enhancement, contrast -limited adaptive histogram equalization – type of an AHE used to improve the contrast in images
- There are few methods for image segmentation that the author review: edge, fuzzy theory, partial differential equation, artificial neural network, threshold and region-based segmentation
Detection of breast cancer on digital histopathology images: Present status and future possibilities
ASWATHY, M. A., M. JAGANNATH. 2017.Detection of breast cancer on digital histopathology images: Present status and future possibilities. Informatics in Medicine Unlocked, 8 : 74-79.
For the breast cancer detection idea, this paper references Spanhol et al. as the source of the data (over 7000 images) used in the training of the algorithm. The steps of the image processing from histopathology are: preprocessing of the images, then segmentation, extraction of the feature and classification. The paper is reviewing convolutional neural networks as an image processing method. Compared to the previous paper, this paper is focusing on the importance of biopsy methods of cancer detection as well as reviews other methods that are common in cancer detection. For future development, the paper is suggesting to explore spectral imaging as well as create more powerful tools to achieve higher image resolution.
Notes:
Look up: Spanhol et al. for the data – used over 7000 images
The steps involved in the algorithm for histopathology image processing include preprocessing of the images, then segmentation, extraction of the feature and classification.
The paper is observing the convolution neural network as an architecture for image analysis
This paper, compared to the previous one, is mainly focusing on the importance of biopsy in cancer detection, as well as reviews other methods that have been used in the sphere of cancer detection.
The paper has also suggestions for the future possibilities such as exploring spectral imaging. Another issue that the article mentions that can be solved is the creation of more powerful tools for the image resolution for digital pathology
Prediction Crime Using Spatial Features
BAPPEE, FATEHA KHANAM, AMILCAR SOARES JUNIOR, STAN MATWIN. 2018.Predicting crime using spatial features.In Canadian Conference on Artificial Intelligence,367-373. Springer, Cham.
This paper approaches crime detection from the perspective of geospatial features and shortest distance to a hotpoint. The end product of this paper is the creation of OSM (Open Street Map). The search of crime hotspots and spatial distance feature is done with the help of hierarchical density-based spatial clustering of Application with Noise (HDBSCAN). For crime patterns of alcohol-related crime the paper references Bromley and Nelson. Some other related works are also using KDE (Kernel Density Estimation) for hospoint prediction. The crime data is categorized into four groups: alcohol-related, assault, property damage and motor vehicle . The type of classifiers that the paper is using are: Logistic Regression, Support Vector Machine (SVM), and Random FOrest . Future improvement is suggested in the sphere of data discrimination.
NOTES:
- Focuses on crime prediction based on geospatial features from a crime data and shortest distance to a hotpoint
- The data is used to create OSM( open street map)
- Using hierarchical density-based spatial clustering of Application with Noise (HDBSCAN) to find crime hotspots and spatial distance feature is retrieved from these hotspots
- Look up Bromley and Nelson into crime patterns of alcohol-related crime
- Kernel Density Estimation (KDE) is used in other related works for hotspot prediction
- Some other related work used KDE with the combination of other features ( Temporal features) for crime hotspot analysis.
- The paper groups the crime into four different classes: alcohol-related, assault, property damage and motor vehicle
- The paper uses Logistic Regression, Support Vector Machine (SVM), and Random FOrest as classifiers
- Paper discusses the issues of possible data discrimination – as a future work to be improved
Big Data Analytics and Mining for Effective visualization and Trends forecasting of crime data
FENG, MINGCHEN, JIANGBIN ZHENG, JINCHANG REN, AMIR HUSSAIN, XIUXIU LIM YUE XI, AND QIAOYUAN LIU.. 2019. Big data analytics and mining for effective visualization and trends forecasting of crime data. IEEE Access, 7: 106111-106123.
This paper is implementing data mining with the help of various algorithms: Prophet model, Keras stateful LSTM, neural network models. After using these models for prediction, the results are compared. For further data mining algorithms and application, we can look up Wu et al. and Vineeth et al. as these were references in the paper. Three datasets were used from three different cities: San-Francisco, Chicago and Philadelphia. The data from the following countries included the following features: Incident number, dates, category, description, day of the week, Police department District ID, Resolution, address, location ( longitude and latitude), coordinates, weather the crime id was domestic or not, and weather there was an arrest or no. For data visualization, Interactive Google Map was used in this paper. Market cluster algorithm was used with the aim of managing multiple markets for spatial scales and resolution.
NOTES:
- The paper reviews various algorithms for data mining : Prophet model, Keras stateful LSTM, – neural network models
- Look up Wu et al. and Vineeth et al. for data mining algorithms and application
- Uses three crime datasets from 3 cities:San-francisco, Chicago and Philadephia
- The data included the following features: Incident number, dates, category, description, day of the week, Police department Distrcit ID, Resolution, address, location ( longitude adn latitude), coordinates, weather the crime id was domestic or not, and weather there was an arrest or no
- Interactive Google map was used for data visualization
- Marker cluster algorithm was used to manage multiple markets for spatial scales adn resolution
- Prediction models used: prophet model, Neural network model and LSTM model and compares the results
Crime prediction using decision tree classification algorithm
IVAN NIYONZIMA, EMMANUEL AHISHAKIYE, ELISHA OPIYO OMULO, AND DANISON TAREMWA.2017. Crime Prediction Using Decision Tree (J48) Classification Algorithm.
This paper approaches crime detection with decision tree and data mining algorithms. This paper, compared to the previous one, gives context on predictability of crimes. The algorithms used in classification that the paper references to are: Decision Tree Classifier, Multilayered Perception (MLP), Naive Bayes Classifiers, Support Vector Machines (SVM). For the system specification, design and implementation a spiral model was used. The training dataset was taken from UCI Machine Learning Repository. For the training purposes Waikato Environment for Knowledge analysis Tool Kit was used.
NOTES:
-uses decision tree and data mining
– Touches upon the context behind the predictability of crimes
– uses classification algorithm – Decision Tree Classifier (DT),Multilayered Perception (MLP) , Naive Bayes Classifiers, Support Vector Machines,
The paper performs analysis on these algorithms based on their performance on crime prediction
-Spiral Model was used to specify the system, design it and implement it
– the dataset was taken from UCI machine learning repository
Waikato Environment for Knowledge analysis Tool Kit was used for the training of crime dataset
Beyond News Contents: the role of Social Context for Fake News Detection
SHU, KAI, SUHANG WANG, AND HUAN LIU.2019. Beyond news contents: The role of social context for fake news detection. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, 312-320.
This paper proposes a tri-relationship framework for fake news detection that analyzes publisher-news relations as well as user-news interactions. The algorithm behind news content embedding is based on nonnegative matrix factorization that projects the news-word matrix to the semantics factor. The evaluation of reported performance is the average of three training processes of TriFN (tri-relationship framework) performances. This paper, in addition, also checks if there is an existing relationship between the delay time of the news and detection of fake news. It also analyzes the importance of social engagement on the performance of fake news detection.
NOTES:
- Proposes Tri-relationship framerfork (TriFN) – for publisher-news relations modeling and user-news interactions
- Uses nonnegative matrix factorization algorithm for projecting news-word matrix to the semantics factor space ( NEWS CONTENTS EMBEDDING)
- Evaluates the performance of TriFn by generating the training process three times and the average performance is reported.
- The paper also checks what’s the correlation between the delay time and detection performance – social engagement as a helping factor for fake news detection
- Related works : references to previous work that has been done in linguistic -based and visual-based
Fake News Detection on Social Media Using Geometric Deep Learning
MONTI, FEDERICO, FABRIZIO FRASCA, DAVIDE EYNARD, DAMON MANNION, AND MICHAEL M. BRONSTEIN. 2019. Fake news detection on social media using geometric deep learning.arXiv preprint arXiv:1902.06673.
This paper uses geometric deep learning for fake news detection on social media. The paper hsa a main focus of data extraction adn testing on Twitter platform. The paper discusses convolution neural networks as a classification method. This paper questions the correlation between the time of the news’ spread and the level of performance of the implemented detection method. The paper also mentions the use of non-profit organizations in the process of data collection, specifically the following journalist fact-checking organizations: Snopes, PolitiFact and Buzzfeed. It is also important to look up pioneering work of Vosoughi et al., as that work is referenced in this paper of great importance in data collection in the fake news detection sphere. All of the features that news were classified into were four: User profile, User activity, network and spreading, and content. It is important to note that this paper mentions that the advantage of deep learning is that it can learn task-specific features given data.
NOTES:
- Uses geometric deep learning for fake news detection
- Like some of my other ideas and the papers that were discussing the classification methods, here as well it touches upon convolutional neural networks
- The paper is discussing and using the model to train and test stories and data from and on Twitter
- This paper, like the one before, also analysis the correlation between the time of the news’ spread and the accuracy and performance of the fake news detection
- Uses Snopes, PolitiFact and Buzzfeed non-profit organizations for journalist fact-checking
- Data collection was based on the pioneering work of Vosoughi et al.
- Human annotators were employed
- Following categories were made out of all the features: user profile , user activity, network and spreading and content.
- Deep learning, compared to other methods, has the advantage to learn task-specific features given the data.
FAKEDETECTOR: Effective Fake News Detection with Deep Diffusive Neural Network
ZHANG, JIAWEI, BOWEN DONG, S. YU PHILIP. 2020. Fakedetector: Effective fake news detection with deep diffusive neural networks. In 2020 IEEE 36th International Conference on Data Engineering (ICDE), 1826-1829.
This paper focuses on a novel model for fake detection – Deep Diffusive Model called GDU that can simultaneously accept multiple inputs from various sources. The paper compares deep diffusive network’s performance with already existing other methods. As a baseline for the fact checking, the paper is using PolitiFact – seems to be a common and reliable source for fact checking. The two main components of deep diffusive network models are: representation feature learning and credibility label inference. For related works need to check Rubin et al. that focuses on unique features of fake news, as well as Singh et al. that focuses on text analysis. In addition Tacchini et al. proposes various classification methods for fake news detection
NOTES:
- Uses deep diffusive network model (GDU) )for training – accepts multiple inputs from different sources at the same time
- Compared FAKE DETECTOR algorithm with deep diffusive network model with already existent other models
- Used data includes tweets posted by POlitiFact
- This is using a similar for fact checking baseline as the paper we mentioned earlier
- Deep diffusive network model consists of two main components: representation feature learning and credibility label inference
- Deep diffusive networks use output state vectors of news articles, news creators and news subjects for the learning process.
- For related works need to check Rubin et al. that focuses on unique features of fake news, as well as Singh et al. that focuses on text analysis. In addition Tacchini et al. proposes various classification methods for fake news detection
“Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection
WANG, WILLIAM YANG, 2017. Liar, liar pants on fire: A new benchmark dataset for fake news detection. arXiv preprint arXiv:1705.00648.
This paper uses a dataset of 12.8K that was manually labeled from PolitiFact.com. The dataset is used as a benchmark for fake checking. This paper is focusing on surface-level linguistic patterns for fake news detection purposes. For this it uses a hybrid convolutional neural network for metadata integration. This paper has a different approach to the fake news detection problem: its viewing the news from a 6-way multiclass text classification frame and combines meta-data with text to get a better fake news detection.
NOTES:
- Uses 12.8K manually labeled short statements in differentes contexts from PolitiFact.com
- Uses this dataset for fact checking
- Surface-level linguistic patterns are the focus of the fake detection
- Uses hybrid convolutional neural network for metadata integration purposes
- Look up: Ott et al., 2011; Perez- Rosas and Mihalcea, 2015 for datasets
- Approaches the problem of fake detection through 6-way multiclass text classification frame
- Lookup Kim, 2014 for CNN models
- Combines meta-data with text and get Better fake news detection
EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
WANG, YAQING, FENGLONG MA, ZHIWEI JIN, YE YUAN,GUANGXU XUN, KINSHLAY JHA, LU SU, JING GAO.2018. Eann: Event adversarial neural networks for multi-modal fake news detection. In Proceedings of the 24th acm sigkdd international conference on knowledge discovery & data mining, 849-857.
This paper is the basis of a fake news detection algorithm in three component-consisted Event Adversarial Neural Network framework: multi-modal feature extractor, fake news detector and event discriminator. For textual feature extraction, the paper is using convolutional neural networks (CNN), while for twitter dataset content evaluation, the paper is using MediaEval Verifying Multimedia. The paper also eliminates those tweets that do not have media attached to the tweets. To detect fake news, the paper is also using Weibo Dataset.
NOTES: Derives event invariant features (extractor) ~
- Uses three components to build the Event Adversarial Neural Network framework: multi-modal feature extractor, fake news detector and event discriminator
- CNN (convolutional neural network) is the core of the textual feature extractor
- The paper is using MediaEval Verifying Multimedia Use benchmark for twitter dataset content evaluation; the dataset is used for both training and testing
- This paper focuses on Tweets that have attached media
- For fake news detection Weibo dataset is used; news is being collected from authoritative news sources and debunked by Weibo.
Fake News Detection via NLP is Vulnerable to Adversarial Attacks
ZHIXUAN ZHOU,HUANKANG GUAN, MEGHANA MOORTHY BHAT, JUSTIN HSU.2019. Fake news detection via NLP is vulnerable to adversarial attacks. arXiv preprint arXiv:1901.09657.
This paper approaches the fake news detection from the linguist classification point of view and targets the weakness of this method. The paper uses Fakebox for experimenting reasons. It uses McIntire’s Fake-real-news-dataset which is open source. The paper focuses on the text content of these dataset (which are in, approximately, 1:1 proportion label fake and real). The paper also brings up a possible solution to the weakness of the linguist classification of datasets: adoption in conjunction with linguistic characteristics.
NOTES: Paper approaches to the issues if linguistic classification of news
- Uses Fakebox as a fake news detector for experimenting
- Suggests a different approach to fake news detection: adoption in conjunction with linguistic characteristics
- Uses McIntire’s Fake-real-news-dataset which is open source
- The paper focuses on the text content of these dataset (which are in, approximately, 1:1 proportion label fake and real0
- Fakebox, the algorithm discussed in this paper, focuses on the following features of the text/news: title/headline (checks for clickbait), content, domain
- Look up Rubin et al. : separates fake news by their type – serious fabrications, large-scale hoaxes and humorous fakes
Breast Cancer detection using image processing techniques
CAHOON, TOBIAS CHRISTIAN, MELANIE A. SUTTON, JAMES C. BEZDEK.2000. Breast cancer detection using image processing techniques.In Ninth IEEE International Conference on Fuzzy Systems. FUZZ-IEEE 2000 (Cat. No. 00CH37063), vol. 2, 973-976.
This paper uses K-nearest neighbor classification method for cancer detection. This paper focuses on image processing from the Mammography screenings taken from Digital Database for Screening Mammography. To get better accuracy in image segmentation, the paper adds window means and standard deviation. This paper, when compared to related work in this field, does not review further related methods and techniques used in related works and does not compare results with other authors’ results.
NOTES: The paper uses k-nearest neighbor classification technique
- Database of images is from the Digital Database for Screening Mammography
- Uses fuzzy c-means method – unsupervised method
- Adds window means and standard deviation to get better image segmentation final product
- The paper, compared to the other related work, does not go as deep to related works, to comparing other methods tried by other authors
Detection of Breast Cancer using MRI: A Pictorial Essay of the Image Processing Techniques
JAGLAN, POONAM, RAJESHWAR DASS, MANOJ DUHAN. 2019.Detection of breast cancer using MRI: a pictorial essay of the image processing techniques. Int J Comput Eng Res Trends (IJCERT) 6, no. 1, 238-245.
This paper is unique with its discussion of the weaknesses of MRI images. Those are: poor image quality, contrast and blurriness. The paper reviews techniques of enhancing image quality. The paper compared various image enhancement filters(Median filter, Average filter, Wiener Filter, Gaussian filter) and compared the results of noise reduction and image quality. The paper uses various statistical parameters for the final performance evaluation: PSNR(Peak signal to noise ratio), Mean Square Error (MSE), Root MEan Square Error (RMSE), MEan Absolute Error (MAE). The paper also reviews the most common noises present in MRI images: Acoustic Noise and Visual NOise
NOTES: touches upon weaknesses of MRi images – suffer poor quality of image, contrast, blurry
- Touches upon ways of enhancing images – compares various image enhancement filters: Median filter, Average filter, Wiener Filter, Gaussian filter and compares the results of noise reduction and image quality
- The paper uses various statistical parameters for the final performance evaluation: PSNR(Peak signal to noise ratio), Mean Square Error( MSE), Root MEan Square Error ( RMSE), MEan Absolute Error (MAE).
- The paper also reviews the most common noises present in MRI images: Acoustic Noise and Visual NOise
Role of image thermography in early breast cancer detection- Past, present and future
DEEPIKA SINGH, ASHUTOSH KUMAR SINGH. 2020. Role of image thermography in early breast cancer detection-Past, present and future. Computer methods and programs in biomedicine 183. 105074.
The paper presents a survey that took into consideration the following cancer detection systems:Image acquisition protocols, segmentation techniques, feature extraction and classification methods. This paper highlights the importance of thermography in breast cancer detection as well as the need to improve the performance of thermographic techniques. The databases used in this paper are: PROENG (from University Hospital at the UFPE), Biotechnology-Tripura University-Jadavpur University database. The paper reviews the role of quality of image segmentation in the reduction of false positive and false negative values in thermography.
NOTES:
- presentation of a survey that took into consideration the following detection systems: Image acquisition protocols, segmentation techniques, feature extraction and classification methods
- Highlights the importance of thermography in breast cancer detection
- The paper highlights the need to improve the performance of thermographic techniques
- The databases of the images used are: PROENG (from University Hospital at the UFPE), Biotechnology-Tripura University-Jadavpur University database
- Reviews the role of image segmentation in the reduction of false positive and false negative values in thermography
DeepCrime: Attentive Hierarchical Recurrent Networks for Crime Prediction
HUANG CHAO, JUNBO ZHANG, YU ZHENG, NITESH V. CHAWLA. 2018. DeepCrime: attentive hierarchical recurrent networks for crime prediction. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, 1423-1432.
This paper uses deep neural network architecture as a classification method. The paper uses DeepCrime algorithm to find the relevance between the time period and crime occurrence. It addresses the main technical challenges when working on crime prediction: temporal Dynamics of crime patterns, complex category dependencies, Inherent interrelations with Ubiquitous data, and unknown temporal relevance. The paper uses the New York City Open Data portal for the crime dataset. Related works view crime detection in different methods. For example, Wang et al. uses the points of interest information for the crime prediction while Zgao et al. approaches crime prediction from the spatial-temporal correlation point of view.
NOTES: Uses deep neural network architecture
- DeepCrime can find relevance between the time period and crime occurrence
- Addresses the main technical challenged when working on crime prediction: temporal Dynamics of crime patterns, complex category dependencies, Inherent interrelations with Ubiquitous data, unknown temporal relevance,
- Uses New York City Open Data portal for the crime dataset
- Related work: look up Lian et al. – “studies restaurant survival prediction based on geographical information, user mobilities” ; Wang et al. related taxi trajectories work
- Something to consider is how to get hotspots – Wang et al uses the points of interest information for the crime prediction purposes while Yu et al.’s approach was based on boosting-based clustering algorithm
- Gerber et al. look up – used Twitter data to predict crimes, while Zhao et al. approaches crime prediction from the spatial-temporal correlation point of view
Predicting Incidents of Crime through LSTM Neural Networks in Smart City
ULISES M. RAMIREZ-ALCOCER, EDGAR TELLO-LEAL, JONATHAN A. MATA-TORRES. 2019. Predicting Incidents of Crime through LSTM Neural Networks in Smart City. in The Eighth International Conference on Smart Cities, Systems, Devices and Technologies.
This paper uses a long short-term memory neural network for the prediction algorithms. This neural network allows the network to choose among the data which ones to remember and which ones to forget. The process of these methods follows these steps: data pre-processing, categorization and construction of the predictive model. The neural network of this method consists of three layers: input layer, hidden layer and output layer. This paper also references toe Catlet et al. and highlights the correlation of the future crime rate to the previous week’s trend set. For the further spatial analysis and auto-regressive models the paper references Catlet et al.
NOTES: Uses Long Short-term memory neural network for the prediction algorithms
- This neural network allows the network to choose among the data which ones to remember and which ones to forget
- The process of this methods follows these steps: data pre-processing, categorization and construction of the predictive model
- The neural network is design of three layers – input, hidden and output layers
- Look up Catlett et al. for spatial analysis and auto-regressive models – will be useful for high-risk crime region detection
- The paper also reference to the Catlett et al. and the correlation of the future crime rate and the previous week’s trend set
Deep Convolutional Neural Networks for Spatiotemporal Crime Prediction
LIAN DUAN, TAO HU, EN CHENG, JIANFENG ZHUM CHAO GAO. 2017. Deep convolutional neural networks for spatiotemporal crime prediction. In Proceedings of the International Conference on Information and Knowledge Engineering (IKE), 61-67.
Tihs paper proposes a Spatiotemporal Crime Network using convolutional Neural Network. The paper uses New York City (2010 -2015) datasets. The paper compares the following models: Rolling Weight average, Support Vector Machines, Random Forests, Shallow fully connected neural networks. The paper uses TensorFlow1.01 and CUDA8.0 with the aim of building STCN and SFCNN. A limitation of this paper is that it does not take into account various data types for better prediction performance, accuracy.
NOTES:
- Proposes a Spatiotemporal Crime Network – uses convolutional Neural networks
- Uses New York City (2010-2015) datasets
- Compares the proposed method with four other models: Rolling Weight average, Support Vector Machines, Random Forests, Shallow fully connected neural networks
- Uses TensorFlow1.01 and CUDA8.0 with the aim of building STCN and SFCNN
- Limitation of this paper is that it does not take into account various data types for better prediction performance, accuracy