Stock Price Prediction using Online Sentiment
Stock Price Prediction using Online Sentiment
Muskan Uprety Department of Computer Science Earlham College Richmond, Indiana, 47374 muprety17@earlham.edu
KEYWORDS
Stock prediction, sentiment analysis, price direction prediction
.
1 ABSTRACT
Due to the current pandemic of the COVID-19, all the current mod- els for investment strategies that were used to predict prices could become obsolete as the market is in a new territory that has not been observed before. It is essential to have some predictive and analytical ability even in times of a global pandemic as smart invest- ments are crucial for securing the existence of savings for people. Due to the recent nature of this crisis, there is limited research in tapping predictive power of various sectors in these unique times. This proposal aims to use texts from online media sources and analyze of these texts hold any predictive powers within them. The proposed research would gather the population sentiment from the online textual data during this pandemic and use the data gathered to train a price prediction model for various stocks. The goal of this research is to check if the prediction model can help make investment strategies that outperforms the market.
2 INTRODUCTION
The unpredictability of stock prices has been a challenge in the Finance industry for as long as stocks have been traded. The goal of beating the market by stockbrokers and experts of the industry have not been materialized, however, the availability of technological resources has certainly opened a lot of doors to experimenting different approaches to try and fully understand the drivers of stock prices. One of the approaches that have been used extensively to try and predict price movements is Sentiment Analysis. The use of this tool is predicated on the fact that stakeholder’s opinion is a major driving force and an indicator for future prices of stock prices. Indicators can be of two types: those derived from textual data (news articles, tweets etc.), and those derived from numerical data (stock prices) [5].
Our research would focus on the textual data derived from sources like Twitter and online news media outlet to analyze if the sentiments in those texts can be used to make price movement predictions in short or long term. It is very important to have some analytical capabilities, specially during and after the COVID-19 pandemic as the outbreak has caused the entire world to be in a shutdown closing businesses indefinitely and burning through peo- ple’s savings. Some panic among consumers and firms has distorted
,,
© 2021
usual consumption patterns and created market anomalies. Global financial markets have also been responsive to the changes and global stock indices have plunged [10].The effect of this disease has created a lot of shifts in the financial industry, along with in- crease in volatility and uncertainty. Due to the pandemic being so recent and ongoing, there is a lack of research on what factors are responsible for the high level of variance and fluctuations in the stock market. While there are papers that analyzes sentiment in text to predict price movements, the applicability of those models in context of a global pandemic is untested. It is vital to be able to have some predictive ability in the stock market as succumbing solely to speculation and fear could result in devastating loss of wealth for individual consumers and investors. The goal of this research is to :
• be able to predict human sentiment from social media posts, • use sentiment to predict changes in price in the stock market • recommend investors to buy, sell, or hold stocks based on
our model
• beat a traditional buy and hold investment strategy.
This paper will first discuss some of the related work that was analyzed in making decisions for algorithms and data to use. After brief discussions about the models to be used in the research, the paper discusses the entire framework of the paper in detail and also discusses the costs associated with conducting this research if any. Finally, the paper proposes a timeline in which the research will be conducted and ends with the references used for this proposal.
3 RELATED WORK
The entire process of using sentiment to predict stock price move- ment is divided into two parts. The first is to to extract the sentiment from the text source using various algorithms, and the second step is to use this information as an input variable to predict the move- ment and direction of the different stocks’ price. various researchers have used different algorithms and models for each of this process. The difference in model is based on the overall goal of the research, the type of text data used for analysis, input parameters used for classifier, and the type of classification problem considered.
3.1 Sentiment analysis
The process of conducting sentiment analysis requires some form of text data that is to be analyzed, and some labels associated with these textual data that allows the model to distinguish if a collection of text is positive or negative in nature. It is quite difficult to find a data set that has been labelled by a human to train the model to make future predictions. Various researchers have used different measures to label their text data in order to train a model to predict
, ,
Muskan Uprety
whether an article or tweet is positive or negative (or neutral but this is not very relevant).
There are a few approaches used by researchers to train their sentiment analysis model. Connor et al. uses a pre-determined bag of words approach to classify their texts [12]. They use a word list which consists of hundreds of words that are determined positive or negative. If any word in the positive word list exists in the text, the text is considered as positive and if any word in the negative word list exists in the text, it is considered negative sentiment. In this approach, an article or tweet can be considered both positive and negative sentiment.
Gelbukh also uses a similar approach of using a bag of words to analyze sentiment [4]. Instead of having pre-determined set of positive and negative word list, they look at the linguistic makeup of sentences like the position of opinion or aspect words in the sentence, part of speech of opinions and aspects and so on to deduce sentiment of the text article.
In the absence of a bag of words for comparison, Antweiler and Frank manually labelled a small subset of tweets into a positive (buy), negative (sell), or neutral (hold classification [1]. Using this as reference, they trained their model to predict the sentiment of each tweet they had into one of these three categories. The researchers also noted that the messages and articles posted in various messaging boards were notably coming from day traders. So although the market price of stocks may reflect the sentiment from entire market participants, the messaging boards most certainly aren’t.
While most researchers looked for either pre-determined bag of words or manually labelled data set, Makrehchi et al automated labelling the text documents [9]. If a company outperforms expec- tations or their stock prices goes higher compared to S&P 500, they assume that the public opinion would be positive and negative if prices go lower than S&P500 or under performs than expectations. Each tweet is turned into a vector of mood words where the column associated with the mood word becomes 1 if the word is mentioned in the tweet and 0 if it isn’t. This way, they train their sentiment analysis model with automated labels for tweets.
3.2 The Prediction Model
All the papers discussed in this proposal use the insights gained from text data collected from various sources. However, the ultimate goal is to check if there is a possibility to predict movement in stock market as a result of such news and tweets online. And researchers use different approaches to make an attempt at finding relationships between online sentiment and stock prices, and they are discussed in this section.
Markechi et. al. collected tweets from people just before and after a major event took place for a company [9]. They used this information to label the tweets as positive or negative. If there was a positive event, the tweets were assumed to be positive and negative if there was a significant negative event. The researchers use this information to train their model to predict the sentiment of future tweets. Aggregating the net sentiment of these predicted tweets, they make a decision on whether to buy, hold, or sell certain stocks. Accounting for weekends and other holidays, they used
Table 1: Papers and Algorithms Used
Papers
Makrehchi et al. [9] Nguyen and Shirai [11] Atkins et al. [2] Axel et al. [6] Gidofalvi [5]
Algorithm Discussed
time stamp analysis TSLDA
LDA
K mean clustering Naive Bayes
this classification model to predict the S&P 500 and were able to outperform the index by 20 percent in a period of 4 months.
Nguyen and Shirai proposed a modified version of Latent Dirich- let Allocation (LDA) model which captures topics and their senti- ments in texts simultaneously [11]. They use this model to assess the sentiments of people over the message boards. They also label each transaction as up or down based on previous date’s price and then use all these features to make prediction on whether the price of the stock in the future will rise or fall. For this classification problem, the researchers use the Support Vector Machine (SVM) classifier which has long been recognized as being able to efficiently handle high dimensional data and has been shown to perform well on many tasks such as text classification [4].
Atkins et. al. used data collected from financial news and used the traditional LDA to extract topic from each news article [2]. Their reasoning of using LDA is that the model effectively reduces features and produces a set of comprehensible topics. Naïve Bayes classifier model follows the LDA model to classify future stock price movements. The uniqueness of this research is that it aims to predict the volatility in prices for stocks instead of trying to predict closing stock prices or simply the movement. They limit their prediction to 60 minutes after an article gets published as the effect of news fades out as time passes.
Axel et. al. collected tweets from financial experts, who they de- fined as people who consistently tweet finance related material, and then used this set of data for their model [6]. After pre-processing the data and reducing dimensions of the data, they experimented with both supervised and unsupervised learning methods to model and classify tweets. They use K mean clustering method to find user clusters with shared tweet content. The researchers then used SVM to classify the tweets to make decisions on buying or selling a stock.
Gidófalvi labelled each transaction as up or down based on pre- vious day pricing [5]. They also labelled articles with the same time frame with similar labels. That is, if a stock price went up, articles that were published immediately before or after also were labelled as up. They then trained the Naïve Bayes text classifier to predict which movement class an article belonged to. Using this predicted article in the test dataset, they predicted the price movement of the corresponding stock. The researchers, through experimentation, found predictive power for the stock price movement in the inter- val starting 20 minutes before and ending 20 minutes after news articles become publicly available.
In terms of classifying text from online media, there was two typed of approaches generally used by researchers. [5] and [9] have used the approach of classifying a text as positive if the text
Stock Price Prediction using Online Sentiment
, ,
was published around a positive event, and classified it as negative sentiment if it was published around the time of some negative event. Their method doesn’t actually look at the contents of the text but rather the time the text was published in. On the other hand, [2] [6] and [11] ,as one would expect, looks inside the text and analyze the contents to classify on whether the authors of these texts intended a positive or negative sentiment. Although algorithms like the LDA or the modified version discussed in [11] are the more intuitive approaches, the fact that classifying texts based on time also yields good results makes me think if reading the text and using computational resources are actually necessary. In the other hand, researchers seem to consistently agree on using SVM as it is widely used in classification problems. Analyzing the various papers, we believe that SVM is the most effective classifier for this stock prediction problem. In the case of sentiment analysis, we believe that more experiments should be done to conduct a cost benefit analysis of actually reading the text for sentiment analysis versus the potential loss of accuracy by just analyzing the time stamp of an article’s publishing.
4 DESIGN
4.1 Framework
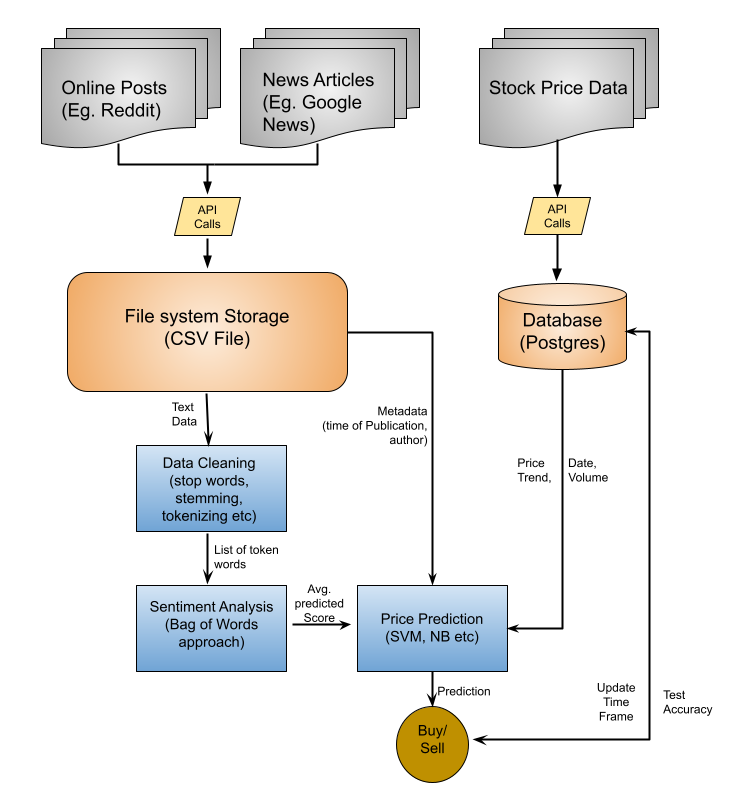
Figure 1: Prediction model framework
The framework of this project is shown in Figure 1. The entire project can be divided into two components. The first part is to use the text data collected from various news articles, messaging boards and tweets and create a sentiment analysis model that is able to extract the average sentiment for individual companies. After that, we use the information from this model to train a price prediction classifier which will predict the direction of the stocks prices. Based on this prediction, the overall output will be a recommendation of buy, sell or hold, which we will use to make investment decisions. The recommendation will be made based on predicted price, current price and purchase price. We will analyze the returns of investment strategies suggested my our model, and compare if our profitability would be better than simply investing and holding an index like the S&P 500.
4.2 Data Collection
In order to gather the sentiment from the entire market, we will diversify our sources of textual data. As Antweiler and Frank dis- covered, messaging board comments were heavily skewed towards day traders [1]; we assume the informal setting of Twitter suggests the input of more traditional and individual investors. We also want to include news articles to capture the sentiment of stakeholders that may have been omitted by the other platforms mentioned. In terms of stock prices, we are using Yahoo Finance which is being consistently used by other researchers to capture the stock prices across time. All of this data will be stored in a Postgres database management system
4.3 Capturing Sentiment
For the purpose of categorizing the text documents as positive and negative sentiments, we are going to compare the Rocchio Algo- rithm [13] and the Latent Dirichlect Allocation (LDA) model [3]. These are the two most discussed method and are the algorithms used by researchers to conduct binary classification of textual sen- timent.
After cleaning the data by eliminating non essential text data (filter texts using keywords), we will transform the data into the form needed by the models. Both these algorithms use a bag of word approach where we select a collection of words that are determined to be capturing sentiment in text. For Rocchio algorithm, each text is converted into a vector of words where we keep track of the frequency of words in the text and use this representation of text to predict sentiment. The basic idea of LDA, on the other hand, is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words [3].
4.4 Price Prediction
Results generated from the Sentiment Analysis model will be used along with a few other input variables from text data to train a classifier which will allow us to make price prediction for individual stocks. For the price prediction model, decision tree [14], support vector machine (SVM) [7] and possibly the Naive Bias models [8] will be tested. We will compare these various models and analyze which model and algorithm produces the best outcome.
5 BUDGET
This project is primarily a python project with some integration of database management system. We intend to use Python pro- gramming, Postgres database management system, Django, and possibly some visualization tool like Tableau. All the computational resources and storage devices are available in Earlham. Since we do not require the purchase of any software, and we anticipate the data to be available online for no cost, there is no cost anticipated at this time.
6 TIMELINE
• week 1-3: finalize the data sources. Research the method/ process to extract data from sources.
• week4-5:ExtractthedatausingappropriateAPIandcreatea database to store the data. Request hardware resources from
, ,
Muskan Uprety
system admins. Have a clear idea of access and updating
database.
- week 5-6: Start implementing the Sentiment analysis algo- rithm to generate/ predict the sentiment of text data.
- week 7-8: Test the sentiment analysis model. After confir- mation of the model’s functionality, begin working on the price prediction classifier. Experiment with all the different models for the specific project.
- week 9-10: Finalize which classifier model is the most accu- rate and is yielding the highest predictability.
- week 11-12: Compile everything together. Use the final rec- ommendation from the algorithm to make investment deci- sions. Compare the investment decisions coming from the algorithm against the traditional investing and holding a market index like S&P 500.
- week 13-14: Showcase and present the findings and results. 7 ACKNOWLEDGEMENT I would like to thank Xunfei Jiang for helping draft this proposal, along with the entire Computer Science Department of Earlham for providing feedback on the project idea. REFERENCES
- [1] Werner Antweiler and Murray Z. Frank. 2004. Is all that talk just noise? The information content of Internet stock message boards. Journal of Finance 59, 3 (2004), 1259–1294. https://doi.org/10.1111/j.1540-6261.2004.00662.x
- [2] Adam Atkins, Mahesan Niranjan, and Enrico Gerding. 2018. Financial news predicts stock market volatility better than close price. The Journal of Finance and Data Science 4, 2 (2018), 120–137. https://doi.org/10.1016/j.jfds.2018.02.002
- [3] JoshuaCharlesCampbell,AbramHindle,andEleniStroulia.2015.LatentDirichlet Allocation: Extracting Topics from Software Engineering Data. The Art and Science of Analyzing Software Data 3 (2015), 139–159. https://doi.org/10.1016/ B978- 0- 12- 411519- 4.00006- 9
- [4] Alexander Gelbukh. 2015. Computational Linguistics and Intelligent Text Pro- cessing: 16th International Conference, CICLing 2015 Cairo, Egypt, April 14-20, 2015 Proceedings, Part II. Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics) 9042, August (2015). https://doi.org/10.1007/978-3-319-18117-2
- [5] Gyözö Gidófalvi. 2001. Using news articles to predict stock price move- ments. Department of Computer Science and Engineering University of Cali- fornia San Diego (2001), 9. https://doi.org/10.1111/j.1540-6261.1985.tb05004.x arXiv:arXiv:0704.0773v2
- [6] AxelGroß-Klußmann,StephanKönig,andMarkusEbner.2019.Buzzwordsbuild momentum: Global financial Twitter sentiment and the aggregate stock market. , 171–186 pages. https://doi.org/10.1016/j.eswa.2019.06.027
- [7] Xiaolin Huang, Andreas Maier, Joachim Hornegger, and Johan A.K. Suykens. 2017. Indefinite kernels in least squares support vector machines and principal component analysis. Applied and Computational Harmonic Analysis 43, 1 (2017), 162–172. https://doi.org/10.1016/j.acha.2016.09.001
- [8] EdmondP.F.Lee,EdmondP.F.Lee,JérômeLozeille,PavelSoldán,SophiaE.Daire, John M. Dyke, and Timothy G. Wright. 2001. An ab initio study of RbO, CsO and FrO (X2+; A2) and their cations (X3-; A3). Physical Chemistry Chemical Physics 3, 22 (2001), 4863–4869. https://doi.org/10.1039/b104835j
- [9] MasoudMakrehchi,SameenaShah,andWenhuiLiao.2013.Stockpredictionusing event-based sentiment analysis. Proceedings – 2013 IEEE/WIC/ACM International Conference on Web Intelligence, WI 2013 1 (2013), 337–342. https://doi.org/10. 1109/WI- IAT.2013.48
- [10] Warwick J. McKibbin and Roshen Fernando. 2020. The Global Macroeconomic ImpactsofCOVID-19:SevenScenarios.SSRNElectronicJournal(2020). https: //doi.org/10.2139/ssrn.3547729
- [11] Thien Hai Nguyen and Kiyoaki Shirai. 2015. Topic modeling based sentiment analysis on social media for stock market prediction. ACL-IJCNLP 2015 – 53rd Annual Meeting of the Association for Computational Linguistics and the 7th Inter- national Joint Conference on Natural Language Processing of the Asian Federation of Natural Language Processing, Proceedings of the Conference 1 (2015), 1354–1364. https://doi.org/10.3115/v1/p15- 1131
- [12] BrendanO’Connor,RamnathBalasubramanyan,BryanR.Routledge,andNoahA. Smith. 2010. From tweets to polls: Linking text sentiment to public opinion time
series. ICWSM 2010 – Proceedings of the 4th International AAAI Conference on
Weblogs and Social Media May (2010), 122–129.
[13] J. ROCCHIO. 1971. Relevance feedback in information retrieval. The Smart
Retrieval System-Experiments in Automatic Document Processing (1971), 313–323.
https://ci.nii.ac.jp/naid/10000074359/en/
[14] P.H.SwainandH.Hauska.1977.Thedecisiontreeclassifier:Designandpotential.
IEEE Transactions on Geoscience Electronics 15, 3 (1977), 142–147.