Capstone Video – Negation-Based Sentiment Analysis in Review
on 2020-05-07
with
No Comments
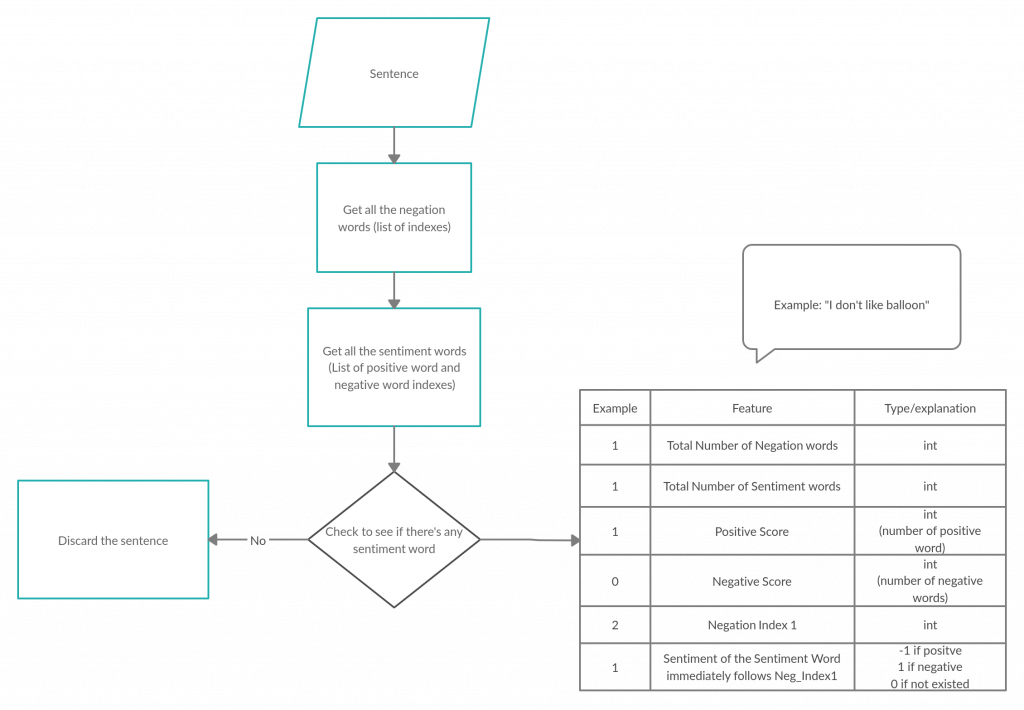
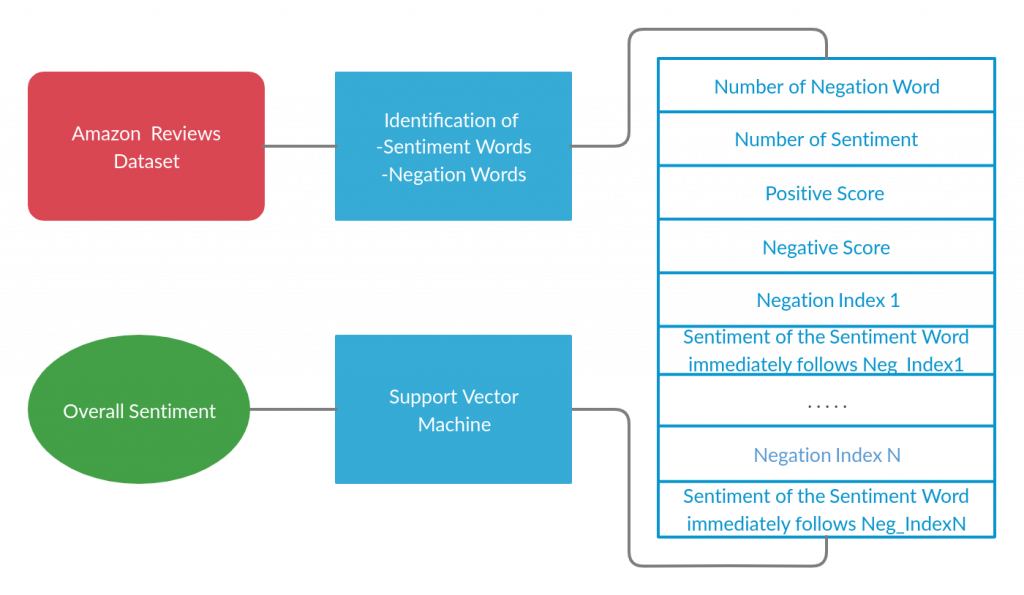
This week, I focused on writing the outline of the paper. I also have been using NLTK to extract features from the text reviews. I need to figure out how to handle a review that has multiple sentences since my feature extraction is currently only applied to one sentence.
For this week, I followed a tutorial from Educative about Natural Language Processing and followed for data preprocessing. I was able to load the dataset and I am in the process of preprocessing it. I ran into a problem of sentences that do not contain any emotions at all, therefore need to be eliminated. Also, I need to extract the word ‘not’ from words such as ‘don’t’, haven’t’ for better indication of a negation. In the following week, I shall try to do so
For the past week, I was able to skim through the Amazon Review datasets and chose Clothing, Shoes and Jewelry, on the criteria that its size is not too much. I then researched and learnt how to use pandas to import the dataset from its json type into a DataFrame. In the following week, I will continue to research and find out the way to extract the review of the data into multiple feature of interest that will be use to train our ML models with.
For the past week, I went back to my materials in CS388 and re-read my proposal along with the research papers in the proposals. In the following week, I need to obtain the dataset and learn (at least partially), the tools/ML models I will need for the project.
Talked to Dave and uploaded the outline for the proposal paper
For this week, I have been looking for research papers on the three topics that I have chose, specifically for the Text Categorization and the Air Quality Monitoring system. Two things I found out:
– Air Quality Monitoring system:There have been many research on a low-price air quality system, some of which use the same technology as I do. This gives me two advantages: First is that I can reference and study those paper for my research. Secondly, I can compare the results I made on my model with that of other researchers so that my model monitoring system would be the same as the others (which would indicate that my model is working correctly).
– Text Categorization: It has been a research and application topic for over a decade. Many researchers have made considerable amount of progress on this topic, which provides me with more insight into the way to approach, which model should I use, etc… Furthermore, I have not found any documents about the application of Text Categorization on Social Media. Therefore my application can be a newly added topic. One thing that I need to worry about is how I am able to get the post and analyze them. Also, I need a pre-classified dataset to train my model in, which I haven’t found. Other than that, I think this can be a great topic to look into.
I have changed two of my ideas upon re-evaluating the achievability of the project given my skill and the time limit I have