Abstract
An ever-present problem in the world of politics and governance in the United States is that of unfairly political congressional redistricting, often referred to as gerrymandering. One method for removing gerrymandering that has been proposed is that of using software to create nonpartisan, unbiased congressional district maps, and there have been some researchers who have done work along these very same lines. This project seeks to be a tool with which one can create congressional maps while adjusting the weights of various factors that it takes into account, and further evaluate these maps using the Monte Carlo method to simulate thousands of elections to see how ‘fair’ the maps are.
Software Architecture Diagram
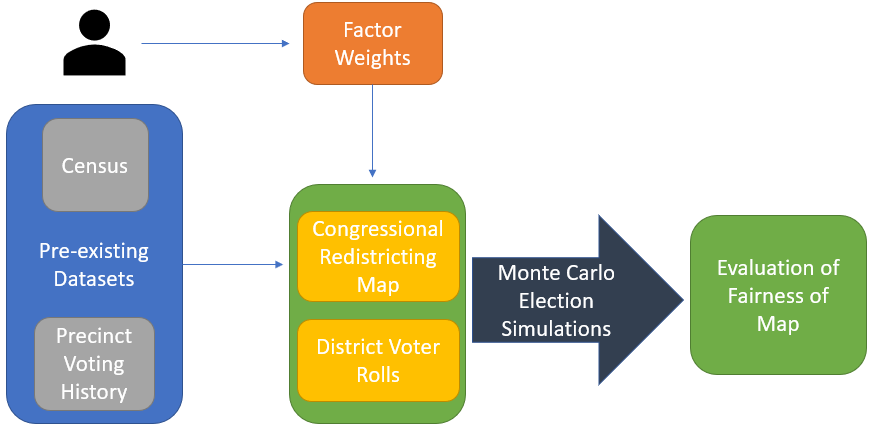
As shown in the figure above, this software will create a congressional district map based off of pre-existing datasets (census and voting history) as well as user-defined factor weighting, which then goes under a Monte Carlo method of simulating thousands of elections in order to evaluate the fairness of this new map. The census data is used both for the user-defined factor weighting and for determining the likelihood to vote for either party (Republican or Democrat), which includes race/ethnicity, income, age, gender, geographical location (urban, suburban, or rural), and educational attainment. The voting history is based on a precinct-by-precinct voting history in Congressional races, and has a heavy weight on the election simulation.
Research Paper
The current version of my research paper can be found here.
Software Demonstration Video
A demonstration of my software can be found here.