Capstone Paper – Machine Learning Models For Predicting And Modeling More Engaging Business Manuscripts
on 2020-05-04
with
No Comments
I have been working on cleaning up and refining my code as well as the frontend. I also worked on the final poster as well as the final version of the paper.
I have been working on wrapping up my project and worked on finishing up the final paper and the poster. The obstacle remains the same where the model gives out very erratic outputs for sentences that are not in its vocabulary but works well with sentences that it has seen before. I will keep continuing to keep working on this and try to figure out a way to make it work, but this goal might be outside the scope of the project given the current workload and time.
I worked on finishing the frontend and wrapping up my project and figuring out what metrics to use measure and compare my models with. I also worked on the poster for my project. This upcoming week I will work on wrapping up my final paper and add the description of my second model to the final paper.
I have finished the front end of the project, and am trying to wrap it up. One obstacle that I am facing is that my project proposed to have human testing, which will not be possible due to the current situation. I will be working on the poster in the next few days.
Having implemented my first two models, I started working on the front end of my project for the user to interact with. This upcoming week I will keep working on the frontend as well as the poster and the paper.
This past week I worked on my other model that uses both engaging/readable and non-engaging/readable advertisements, I found that this model does not perform well because of the lack of parallel data and sentence structures between the two different sentences. For the next week, I will work on refining my initial model as well as writing the frontend for the project.
Since I uploaded the architecture design last week, this will I will go back to posting the normal updates here – I have been slowly working on my second model that I will compare my initial mode to. I have not faced any obstacles yet except the learning curve that comes with learning Keras, but since Keras is well documented it does not take much time for me to figure out something that I am stuck in. In the upcoming week, I will keep working on the second model and plan to have it finished by the end of spring break.
— Elevator Pitch —
My project aims to use a sequence to sequence encoder-decoder model to make text-based advertisements more engaging and readable. This will help businesses get an edge over their competitors by attracting new customers as well as retaining their existing customers by making sure that their advertisements are readable and engaging to their target audience. This will be done through the analysis of pre-existing advertisements which will then be used to train the model on how to restructure sentences to make them more readable and engaging.
I finished writing my initial model and have trained it using a small sample dataset. The accuracy of my initial model is quite bad. I am currently researching how I can modify and improve the accuracy of my model as well as downloading a larger dataset to increase the accuracy. I also worked on the outline of the first draft of the final paper. Currently, the obstacle is the lack of accuracy of my model. This next week I will work on finishing up the first draft of the final paper as well as increasing the accuracy of my model.
Last week I worked on collecting and preprocessing the data using Groupon API. I also started learning about and implementing my autoencoder model. So far the obstacle has been the learning curve but I have been extensively reading about neural networks and Keras and should be able to continue working on the project without any hiccups. Next week I plan to start my first draft of the paper as well as have a somewhat working version of the autoencoder model.
Since my project involves a significant part that’s marketing, I was advised by my instructor to talk to Seth and other professors about how I should approach a dataset. After talking to them, I have decided that a good approach would be creating a dataset using the readability formulas. First I will calculate the average readability and then filter the dataset using that average readability. A marketing dataset has been extremely hard to find, but asking around has led me to the Groupon API – it lets me get 100 deals per second which will help me easily scrape millions of deals in a few days. I plan to run a script in the background that does it. Since last week, I have also successfully implemented word2vec using Genism – a python library.
Due to a lack of available usable datasets, after talking to my advisor and instructor I decided to modify my project to focus on readability and sentiment instead. I researched papers on readability and sentiment this last week and have starting writing code using python(Keras). My next week’s goals are to have some working code for a trained network that produces more readable code. I still need to look a bit more into what constitutes as readable when it comes to marketing material.
I have researched and read a few more papers in the last week. I have expanded upon my analyze -> split -> replace modules with actual implementation details using an encoder-decoder model to swap less engaging text with more engaging text. In order to do this, the text needs to be vectorized and then trained. I have also found a module that can help me achieve that. I have also extensively worked on my proposal presentation. I also met with my advisor and went over the presentation and was advised to explain the slides in a way that a person with no understanding of neural networks can understand what is being communicated.
This week I have been working on my presentation and have refined my proposal a bit. I will keep working on my presentation until the upcoming Wednesday as I wait for feedback on my second draft of my proposal
I have mostly worked on the second draft of my proposal in the past week. I simplified and restructured my framework model. I also looked for more use cases of my project and decided what frameworks to use while implementing it.
In the past week, I have spent most of my time working on the first draft of the proposal. I decided to research and include a new category of papers in my proposal that I had not spent a lot of time before on. The new category that I included was “Sentiment Analysis.” While working on the proposal and refining the design of my framework, I realized that sentiment analysis, something that has been thoroughly covered by researchers of neural networks is very close to my research since I also need to know the sentiment behind the email/piece of text that is to be improved.
I extensively worked on the proposal last week, reading more papers and writing out what I plan to do helped me figure out the scope of the proposed project. I also experimented a bit more with tensorflow. I made some changes to my initial framework design to now include a frontend and backend for the end-user to interact with.
In order to get more familiar with neural networks I decided to use a program that lets you create neural networks. In order to do this I started reading about tensorflow and tensorflow graphs and their inner workings like variables, constants and operations. I read some tutorials on tensorflow and also studied about the Keras model subclassing API which is one of the building blocks of tensor flow to start building a simple neural network. I also read I also searched for more papers that are similar to my research and read Semantic expansion using word embedding clustering and convolutional neural network for improving short text classification, Semantic Clustering and Convolutional Neural Network for Short Text Categorization in order to familiarize myself more with neural networks that are used for text classification.
This past week I worked on revising my literature review as well as writing my proposal outline that will serve as a starting point for my first proposal draft. I met with my advisor who helped me to come up with a good starting dataset for my initial neural network. I will continue read about neural networks and maybe try to implement a simple one in the upcoming weeks.
I read over 20 papers in the last two weeks to work on my literature review. I met with my advisor and talked to him about my proposal and what could be improved in my literature review. I have found some projects/papers that touch upon what my project aims to be. This will help me find and establish a starting point once I start working on my project. One of the challenges that I am currently facing is finding a dataset. I have come across a few datasets that I can use from kaagle.com.
This is what my initial model looks like (This does not delve deeper into how the neural networks are configured.)
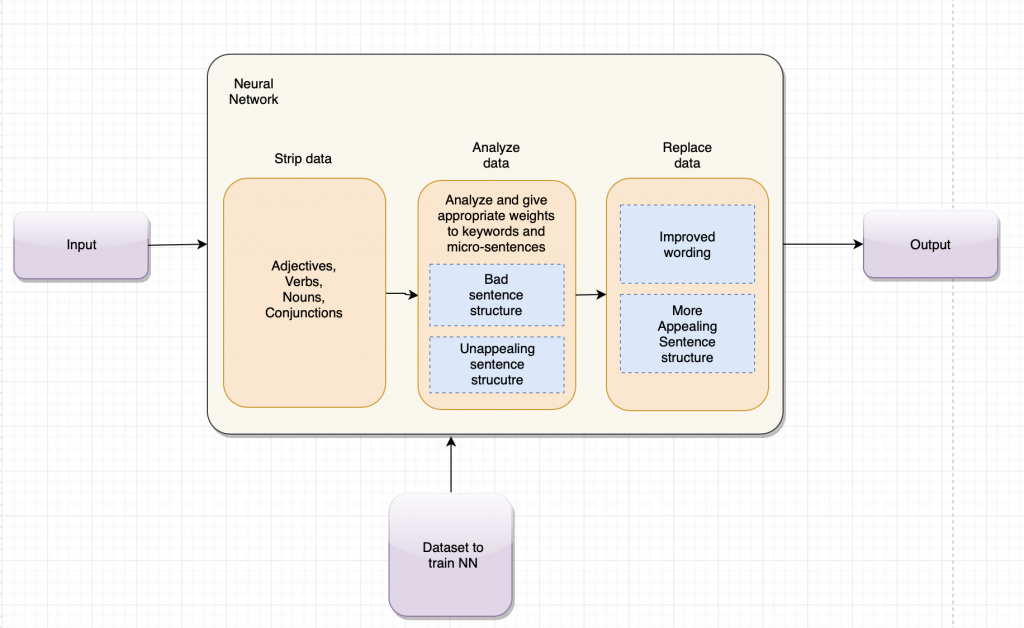
I now know what idea I am going to go with, it’s a new idea and is not related to any of my old ideas. My new idea is about using neural networks and natural language processing to predict a better way to write emails or other forms of text in order to better engage the reader. This will be focused on business emails and other forms of business-related texts. I have read a lot of papers on neural networks in the past week and have spent most of my time writing my literature review on it.
I read more papers on my ideas, met with my advisor to schedule a weekly meeting and discussed a new idea proposed by the company I interned with this summer.
The new idea is a Neural Network driven A.I. that can learn and predict better ways to write emails, marketing campaigns and other forms of communication with the customer.
Most of the articles I have read this week have been quite informative and take the time to explain even the most basic things. However, this has not been true for all the articles that I have read. Some of these articles assume that the reader is already familiar with the terminologies and technologies used in their research or study. Although this helps the reader dig deeper into the topic and come out with a better understanding of the study or research, it also means that doing a 1 or 2 par reading often does not suffice in these cases. Along with reading research papers this week, I also worked on some technical diagrams for my projects this week.
I did a 2 pass reading of all the sources that I had collected over the last two weeks. I realized that some of the things I had in mind already exist. I’m still researching about pre-existing technologies/frameworks that could help me set up a reference point to build upon as I work on my project.
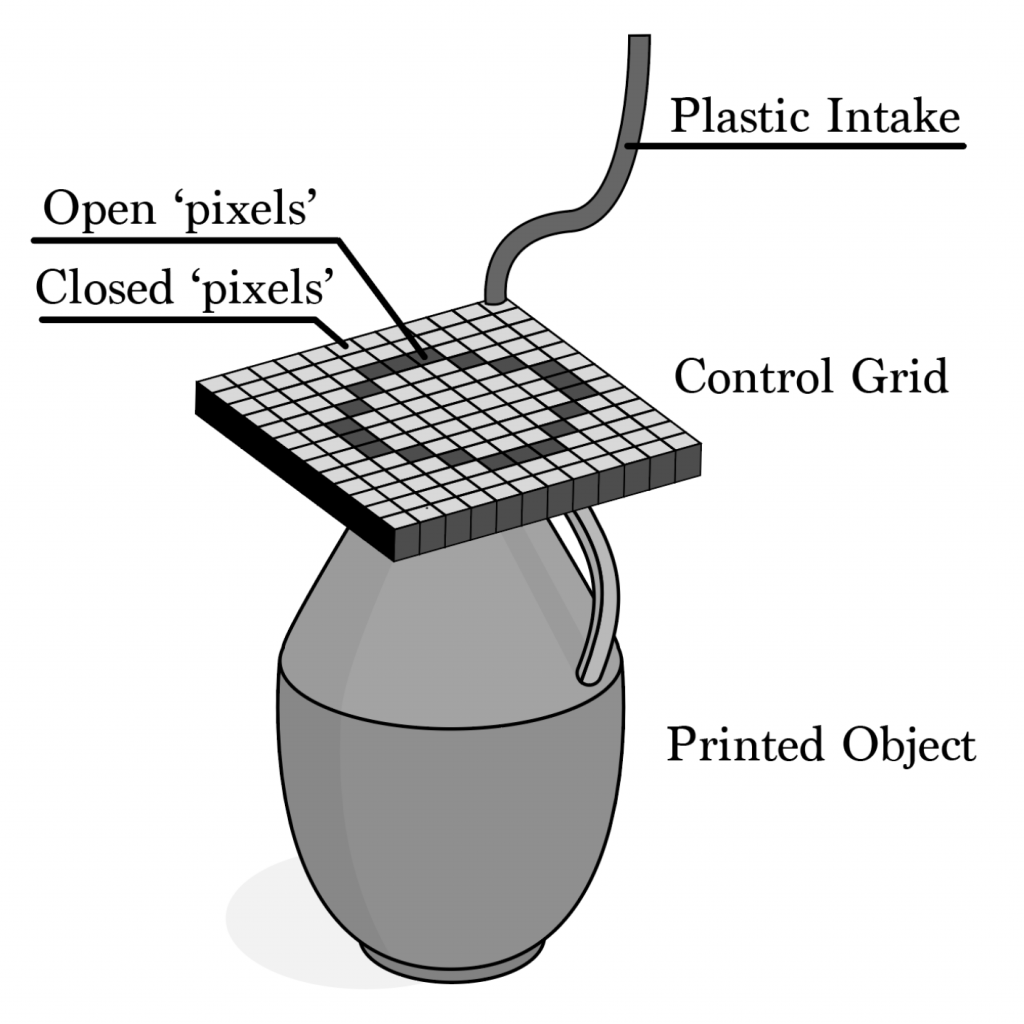
A new way of 3d printing. The implementation includes a pixel grid that is controlled by a computer, the 3d object is converted into layers, the layer then controls the corresponding pixels the molten plastic flows through. Based on the layer the pixels ‘open’ and ‘close’ to form the 3d object. The pixel grid moves up as it finishes a layer forming the 3d object.
A drone that creates a google street view like map. A radius can be set using a mobile interface and the drone will go around using pathfinding algorithms. It will take images that will be stitched together to create a 3d space – google street view like maps. This can be used to map and study deep cave systems.
A new way of 3d printing. The implementation includes a pixel grid that is controlled by a computer, the 3d object is converted into layers, the layer then controls the corresponding pixels the molten plastic flows through. Based on the layer the pixels ‘open’ and ‘close’ to form the 3d object. The pixel grid moves up as it finishes a layer forming the
Based on natural language processing and AI – a program that takes in a description of the application that needs to be built. The AI will then use a natural language processor to convert the description to code. This can be useful for businesses that cannot afford to hire software developers to build their application.
Name of Your Project?
Pixel Printer
What research topic/question your project is going to address?
My project aims to improve the current process of 3d printing that is used for mainstream industrial 3d printing.
What technology will be used in your project?
What software and hardware will be needed for your project?
How are you planning to implement?
My implementation includes a pixel grid that is controlled by a computer, the 3d object is converted into layers, the layer then controls the corresponding pixels the molten plastic flows through,. Based on the layer the pixels ‘open’ and ‘close’ to form the 3d object. The pixel grid moves up as it finishes a layer.
How is your project different from others? What’s new in your project?
My project is an entirely new concept. This process of 3D-printing does not exist. The current 3d printers consist of a nozzle through which the molten plastic flows, the nozzle then moves around forming the object which is very time consuming. My process uses a pixel grid that allows molten plastic to flow through the pixels forming the object.
What’s the difficulties of your project? What problems you might encounter during your project?