Link to project on GitLab: https://gitlab.cluster.earlham.edu/senior-capstones-2020/lmgray16-senior-capstone
Capstone Software Video
on 2020-05-15
with
No Comments
Link to project on GitLab: https://gitlab.cluster.earlham.edu/senior-capstones-2020/lmgray16-senior-capstone

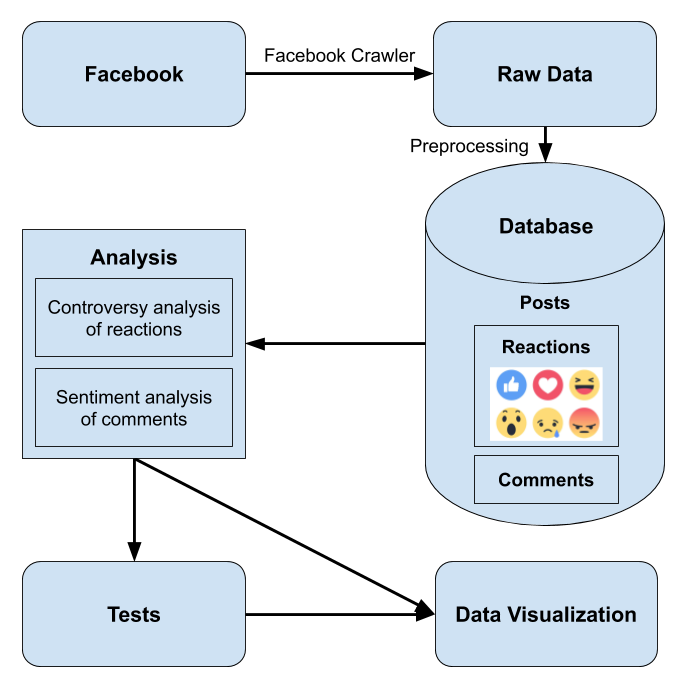
Gender bias on Facebook might be measured by analyzing the difference in reactions on posts by women or men. My project is studying bias on Facebook pages of United States politicians using Facebook Reactions and post comments. Specifically, I am focusing on politicians running for US Senate in 2020. Data is being collected from Facebook pages of the politicians using a crawler and will be into a database.
The data will be analyzed by performing sentiment analysis on the comments and using an entropy function on the reactions for each post. The comment analysis is both focused on whether a comment contains more negative or positive words, and if it contains more personal or professional related words. My hypothesis is that female politicians may have comments directed at them that are both more negative, and more focused on personal issues. I am using an entropy function on the reactions to each post to measure how divided the reactions are. Related work used an entropy function on reactions to measure the controversy of a post. My hypothesis is that, in general, posts by female politicians will be more controversial than posts by male politicians.
Last weekend, I spent time with a small group of friends filling out a spreadsheet of information for 2020 Senate candidates. So far, 154/348 filed candidates have been added to the sheet. During that time, we discovered that a few candidates operate their campaign on a public Facebook profile instead of a Facebook page. In talking with Charlie, he guessed that the process in the API to collect profile data shouldn’t be too different from page data. Therefore, I am planning to collect this data as well, while noting the names with profiles in case their results are drastically different from overall results. Next, I plan to develop the scripts to start collecting and analyzing small amounts of data, planning to scale and automize them later.
My project is to collect and study the Facebook Reactions and comments on posts by U.S. politicians to see if bias exists based on the gender of the politician. I have decided with Charlie’s advice to focus my project on the 2020 Senate races. The 2020 Presidential election doesn’t have enough candidates to be a good sample size. The 2020 House races would likely have a wide variety of candidate strategies based on the district, many districts with no competition, and less voters per race. By contrast, the Senate races have enough candidates to be a good sample size, while also having more voters per race, meaning there should be more Facebook Pages with enough user activity to be used in my dataset.
This week I found sources for the Senate races, created a spreadsheet for candidates, and decided on which relevant columns should be in the spreadsheet. I am filling out the sheet first for races where the filing deadline has passed for the primary first. Next, I plan to learn how to access the Facebook API using the Facebook SDK Python library, and to collect sample data for candidates I have already added to the spreadsheet.
This week, I investigated the technologies being used in my found papers more closely to find which technologies would be more feasible for my project. For data collection, I have found that the facebook-sdk python library (https://pypi.org/project/facebook-sdk/) used by Pool and Nissim is the best option to connect to the Facebook Graph API, since it looks well documented and has all the options I might need. I also decided to use the Facebook Pages of politicians as my dataset. I reread As the Tweet, So the Reply?: Gender Bias in Digital Communication with Politicians by Mertens et al. to see if their methods could be adapted to my project. I will need to look at their references for methods in more detail to see if I can feasibly apply them to my project.
I have narrowed my project to studying Facebook Reactions and how reactions may differ based on the gender of the post creator. I have also found papers that focus on facebook reactions. Because Facebook Reactions were released as a feature in 2016, the papers on the subject are limited, and I haven’t found any relating to gender. However, some papers I found analyze facebook reactions in a way that would be interesting to compare between the gender of the post creator. For example, one paper uses the reactions to measure the controversy of a post, so I could measure if posts by women are more controversial in general than that of men. I also found tools from some of these papers that I could use in my project.
I am working on finding more papers that study gender bias in social media posts and narrowing my idea further. One challenge is finding a feasible way to collect data from a site (since APIs have limits), or finding an existing data set or web scraper that fits my needs. I am also looking for authors that have published their code for their work and/or who have described their methods in detail.
In the past few weeks I have settled on my topic being exploring gender bias on a website using a combination of computational linguistics and quantitative analysis. After writing my literature review on work that explored a variety of sites, I decided this week to focus on a social media site for my project. My next step is to explore more papers focused on analyzing social media and the APIs available for different sites in order to choose which site I want to focus on.
A Forum Site to Improve Student Access to Administrative Information
How do we improve communication between students and Earlham administration? Currently, when students have an administrative question, information is not easily found on Earlham’s website, and it is difficult to find the right person to talk to.
Open source forum code such as Reddit or Discourse.
HTML, CSS, and Javascript, and the dependencies for the forum code I choose.
Using an open source forum code, I will create a site for Earlham student to post questions about certain departments or offices. Members of the Earlham community can post replies, and administrators can moderate the categories of questions that apply to them. There also may be an automatically generated reply found by searching Earlham’s website. When a question has a lot of upvotes, it may generate an email to the relevant administrator.
This site would provide a single space for student questions, improving student access to campus information. This would also ease the burden on administrators answering the same questions from many students. While the site is built upon an existing forum model, it would be formalized for usage by Earlham students and administrators.
Finding the best existing forum source code to use will take time. Using the chosen forum basis, and being able to build upon it to work for both students and administrators is key. As with any software project, the project could run into problems of feasibility, so planning the minimum and most important features is also important.