Capstone Software Video
on 2020-05-04
with
No Comments
This week I prepared my poster for the final submission, while editing also reworking my paper for the final submission next week. Last week I received feedback regarding user interaction and did research this week into what is the best way to build a GUI for my software.
This week I submitted my second draft of the paper, which required lots of results production as well as time to write. I graphed prediction trends between different materials of foreign data with my model which also was demonstrating how my model was performing. I received great feedback from my advisor regarding the poster and paper and will look to improve these both this week for final submission.
This week we had the first draft of the poster due, which meant producing and visualizing a lot of results from my project. From this motivation, I compared my predictions across very different data (news articles, fictional novels, ect) and also was able to produce a convolution matrix that showed just how accurate my model was. This coming week I want to transfer these results into the next paper draft and continue with the user flow of the software.
This week I further improved the pre-processing of sentences so that they are cleaner and easier to read on output. I then downloaded some previous year project posters to help with designing my own and have already completed half of it. It showed me that now I need to work further on results to present, on the accuracy of my model outside of its dataset.
During the past couple of weeks, I made some good progress on my project. I now have a functioning driver file that the user will run to train or validate a model, or to predict from their input data. This has allowed me to tie up different parts of my software into one functioning project. I also have predictions working (big step) and am currently working on the best way for the user to view their results.
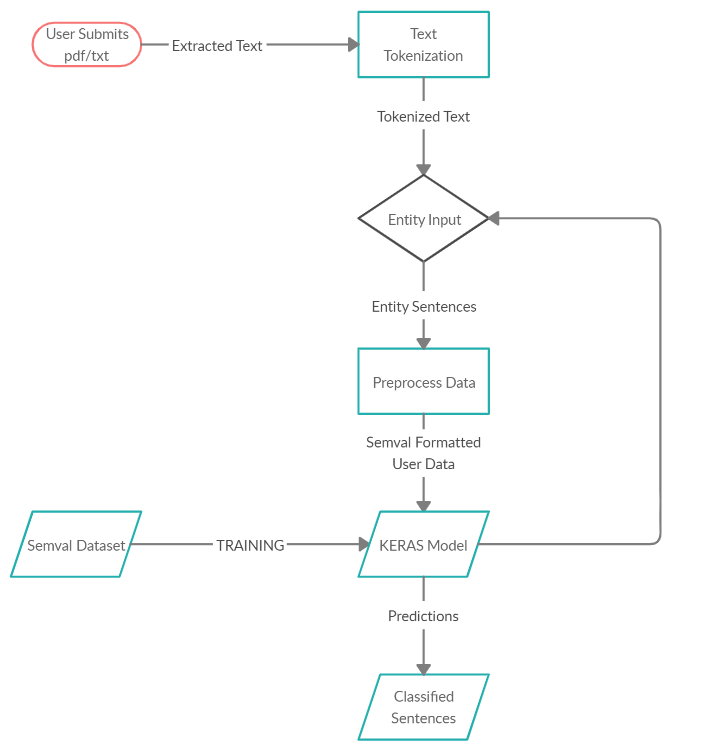
Please click on the title above to view my flow diagram.
This week I focused more on refining my idea and how it would flow for a user, which then helped me to create a flow diagram for this week. During this process, I realized some flows in my code were inefficient, so I changed the flow of information through certain functions to match up with my flow diagram.
I created a validation function to test a loaded model and also an argument parser to make it easier to pass values for different and important variables into the code.
This week I began creating a model using the Keras Python library. I have been training it on the SemVal Task 8 2010 dataset, with accuracies of around 90% during training and 5 epochs and 60-65% validation accuracy. I was successfully able to save and reload the model.
I will be working on increasing the accuracy of this model in the coming week before applying it outside of its dataset.
My project aims to see how applicable semantic relation extraction models are outside of their dataset. Semantic relations are how we draw knowledge and facts from a text and no text is the same and when we research we usually look for these relationships regarding certain subjects in the text important to us. I want to see if a normal user can use state-of-the-art semantic models outside of their dataset to decrease the time needed to find specific knowledge about any entity in an unstructured text.
This week I was trying to run two different TensorFlow models with checkpoints, however, I could get the checkpoints to work which is key to my project. After a discussion with Dave, I have decided to implement a simple model myself using the Keras library since it is more abstracted and well documented, so it shouldn’t take too much time. I will be aiming for a minimum of 50% accuracy with my model and the SemVal-2010 Task 8 Dataset, which I think is the best dataset choice for this task.
Following this implementation, I want then start testing my model outside its dataset.
This week I first worked on creating an outline for my final paper, which was useful as it sharpened my current understanding of my project and where it is headed. I also was working with a new model and was able to successfully train it, save checkpoints and load them. I also created basic pre-processing functions for my data to match the format of input sets.
Loading of weights did seem to not work with this model. When I reached a checkpoint with 80%+ accuracy and saved the weights, I followed up with loading the weights and feeding in test data from the dataset, but accuracy dropped to 5%. This was extremely confusing and is my priority to understand this week otherwise I will have to find another model.
This week I made efforts to get predictions from my model that was trained last week. However, after some hours spent understanding the code, I realized that this model is not for practical use but rather theoretical predictions, as each query set requires a supporting set.
Following this setback, I have now found some models to train from a smaller dataset in comparison to FewRel. I believe these models are able to be used practically on random query sets. With the smaller training time required for them, I should be able to verify which is best for my project this week.
This week I was able to create a saved checkpoint of my learning model for semantic relation extraction. This hopefully means I won’t need to train it further and can now focus on feeding it my data, which now needs to be pre-processed before being fed into the model. A basic GUI window was also up and running this week with PyQt5 which was great to see! I will be writing more code in the coming weeks now so I need to ensure that my project files are organized.
I forked MLMAN, a PyTorch model that achieved the second-highest accuracy of validation on the FewRel dataset for semantic relation extraction. Running locally with a useful amount of iterations, it took to long to train, so I will be training the module on hopper and saving the model there to fetch for local use. With this saved model, I hope to start pre-processing and feeding sentences into it for validation.
This week I created the presentation for Wednesday, which helped to make clear to me my new current goal after work done over break. I have found some new datasets and repositories for models online, which I will be presenting to my advisor to figure out which best suits my project. I have also tried to better breakdown my timeline following the selection of a module for the following month, and have personal project goals. I researched some libraries for GUI implementations, currently leaning towards Electron (Java) or PyQt5 (Python).
I did not add an update to week 6 due to the long weekend but had been working on my literature review, which I finished today. It was very useful to read and re-read certain articles and realise some are useful and some are not. I now have further inspiration with where I can take my idea and am happy with its process. I will be looking in the next week or two to start looking into potential technologies to use for my project, which currently seems to be leaning on public Python libraries.
This week I researched deeper into my three ideas, and now have developed preferences and better understandings of them. Specifically, I believe the natural language processing idea where I will create summaries of subjects in PDF’s seems to not only be the most interesting to me, but the most achievable and most understandable of the ideas. It requires a lot more CS than the other two, which I like. The others, especially the math proof assistant idea, seem like they will contain much more design choices and therefore will distract from the CS side of it. I did make more progress though on finding approaches to the math notes to LaTeX idea, as there is a decent amount of research in symbol recognition, however handwritten was harder to find as opposed to digitally drawn with electric pens. The proof assistant idea is the hardest to research but I am making slow steady progress in this field.
For this week, I started reading more into the papers that I found initially interesting for my ideas. I found some to be less relevant than others, but still drew some nice views that may be helpful later to shape my ideas. I want to perhaps find some replacement papers, and also talk to a CS professor this week about idea refinement.
Idea: Breakdown of Mathematical Proofs Using Natural Language Processing
I wish to use natural language processing to break down a bachelor-level mathematical proof into the components that make up a proof (e.g. given knowledge, statements, calculations). This will be shown in a GUI so that the user can clearly see the build-up of their proof. Without constraints of time, some more technologies could be applied (machine learning) to give feedback to the user of the strength of their proof.
Update:
No update to this idea.
Character Description Generation from Novels
I want to use natural language processing to allow a user to enter a character’s name (fictional or non-fictional) in whatever PDF they please, and have the algorithm generate a list of facts/short descriptive paragraph about the character. This could be useful when doing novel summaries, studying history and remembering the roles of persons, etc.
Update:
This idea is new and came after a discussion with Charlie that my previous ideas were not too interesting ideas (ie. not much room for expansion, not much coding).
Photo to LaTex Generation
This idea came while looking over some of my math notes and wanting to digitalize them. After looking online, the technology does not seem to be there, with some very primitive attempts. I would like to attempt myself at allowing someone to digitalize their math notes in LaTex form. It would require symbolic and natural language processing, potentially machine learning upon more investigation.
Update:
This is also a new idea, again discussed with Charlie after doubts about the previous idea.
Breakdown of Mathematical Proofs Using Natural Language Processing
I wish to use natural language processing to break down a bachelor-level mathematical proof into the components that make up a proof (e.g. given knowledge, statements, calculations). This will be shown in a GUI so that the user can clearly see the build-up of their proof. Without constraints of time, some more technologies could be applied (machine learning) to give feedback to the user of the strength of their proof.
WhatsUp! : A Passive Event-Sharing Application for Friends
This application will enable a user to check on friends current/planned activities through a simple feed or calendar. Events will have scheduled times, lists of “agreed” participants, and the location. They can be confirmed events, or requests for an event, such as someone looking to go to Walmart at a certain time. Privacy settings could be configured to those in a Geo-Area, or to a specific list of friends, and notifications could also be customized.
Extensive Music Recommendation Website
This website will allow users to input songs and/or attribute values to return recommendations. Users will be able to view detailed analysis of their input tracks attributes and can search also with track attributes (e.g. acousticness, energy, speechiness). This will be done with the Spotify API.
Breakdown of Mathematical Proofs Using Natural Language Processing
How available and useful current technology is to address completeness of mathematical proofs in intro/bachelor level mathematics courses.
Python Natural Language Processing libraries, and SwiftUI for the GUI.
Languages: Python, Swift
Development: XCode
The end goal would be to assist students taking undergraduate classes.
I have not seen/be able to find applications of natural language processing towards the field of algebra and mathematical proofs.
Finding a large enough dataset to work with, that is consistent. Creating a strict enough rule set to classify proof components by.