Paper: Fake_News_Capstone
Poster:

Github directory: https://github.com/mashres15/FakeNewsCapstone
Finished working on the final paper.
Worked on the poster and got it printed. Copy of the poster attached.
This week, I was focused on making the poster and including the final results of my research.
Here is an updated machine learning pipeline for my project.
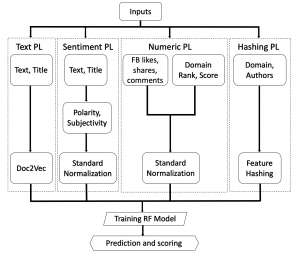
Submitted the CS second draft on Wednesday and waiting for Xunfei’s Feedback. The demo presentation went well without much questions from the audience. On working on making the poster for the presentation on Dec 5.
Worked on the demo presentation. Experimented with 2 datasets each taking 4 hours of run time. One observation I found is that changing the labels of the fake news changes the accuracy. It was found that detecting reliable news rather than fake news was statistically better in performance.
The front end development part for my project is almost complete. The database setup and connection is completed. The integration of backend machine learning model with flask has worked. The flask prediction model has also been linked with the frontend. There are some issues with websites that are not blog and I am fixing the issue. Next step is to make a retrainable model.
Worked on completing the frontend. I have decided to use my local machine for hosting flask and have made progress on the backend. I still need to fix Database issues but progress this week has been significant. I have just received feedback from Xunfei on my project and will be working on it this week. A look at my front end:
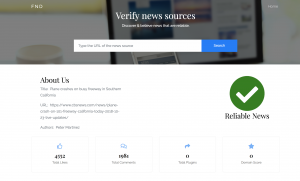
Worked on the front end component of the project. With the sys admin telling me that they cannot host flask for my project. I started to look for alternatives. Heroku could not be used as it did not provide support for sci-kit the way I needed. Worked with Ajit to edit my first draft paper. Mades some figures of the architectures.
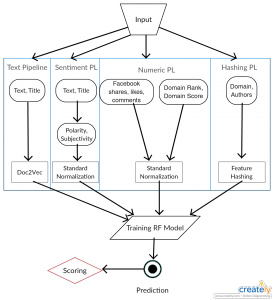
Finished the machine learning pipeline with actual experimentation. Having issues getting Flask setup and have been in touch with the SysAdmins. Halfway through the first draft of the paper. Made new design for the system architecture.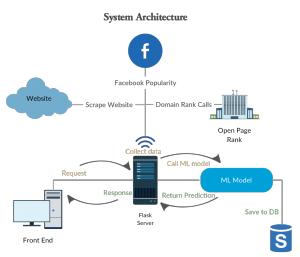
I did an experimentation with Sci-kit Learn. The run-time for the program was more than 2 hours. Testing the multiple dataset has been an issue lately.
Progress on the draft of the paper. Related works is almost completed.
Worked on the first draft of the paper. Focusing on the related works and findings currently.
Build a rough machine learning pipeline for testing. Worked with Ajit to update timeline. Started with the first draft of paper.
Created a smaller dataset using pySpark for training and testing the fake news model.
Completed corpus creation. Filter the dataset and collecting data from Facebook. Automated process using pyspark. Reduced 40GB file to 9 GB and needed to be cleaned for machine learning processing.
Worked with setting up sci-kit learn and testing environment. Got Craig to give me access to Pollock and Bronte.
Retrieved the FakeNewsCorupus Dataset from Kaggle. The file size is 40GB and I am thinking about selecting a subset of it to create a smaller dataset. Sci-kit learn cannot load the data on my computer and I need to use a cluster system. Will talk to Craig about getting the issue fixed.
Started the project pipeline for Fake News Detection.
A Data Science and Machine Learning Project to explore the stock data of a particular stock exchange. The exploration will be focused on observing the repetitive trend in stock markets and relating it to the business cycles. Some questions that can be asked in this project is as follows:
The main resource for this project would be “Python for Finance” Analyze Big Financial Data by O’Reilly Media. Some other resources are as follows:
A portfolio tracker that keep tracks of investments in stocks in a particular market. Keeping in mind the time limitation, it would be better to focus on small markets for this project. The web-based application will provide different portfolios to users to keep track of their investments and to easily look at their best and worst investment.
In this project, the major component of research would be figuring about how to structure the database design for such a system as well as enforcing multiple levels of database transactions logging. A further investigation might be in mirroring the data for backup. Along with this, the project can have a data analysis research segment for any market that might suffice the need of this project.
The research component of this project will also lie in using Model View Controller design pattern to develop such a system. This project essentially has two part, the software design, and the data analysis research. If this project is taken, serious amount of planning has to be done to ensure that all both the component of the project is completed,
The project is about creating a software that can determine an optimal value for a company by looking at their balance sheets records in the past to predict future cash flows. Financial analysis methods such as DCF, DDM and FCE can be implemented in this approach (only one). This system would be automated using machine learning and data analysis.
The main research for this project is coming up with a model that can predict the future cash flows of a company by looking at past trends. Regression will be one of the core Machine Learning Techniques that will be applied in this research. Some resources for this project will be “Python for Finance” Analyze Big Financial Data by O’Reilly Media.
The valuation of the company is doing using what finance people call as the time value of money adjustment. Basically, what this means is that getting $100 today is better than getting in tomorrow or anytime in the future. Thus, all future cash flows that the company generates needs to be discounted at today’s value. In order to do this, we need to figure out the discount rate. There are different approaches we can take for this. For instance, we can use the interest rate provided by the Federal Reserve or we can make our own that can reflect the real financial scenario better. The Capital Asset Pricing Model can be used in this scenario but there are things such are beta and the free interest rate that needs to be estimated. This estimation can be the second part of the research.