Ancient Near Eastern cuneiform tablets document one of the earliest writing systems known. Extensive collections of cuneiform tablets are in the process of being digitized by many institutions worldwide in an effort to make the digitized inscriptions available to remote researchers. With an increasing demand for digitization in the museum sector, this project addresses the ineffectiveness of manual image processing and aims to contribute to ancient Near Eastern studies with automated image processing of cuneiform tablets.
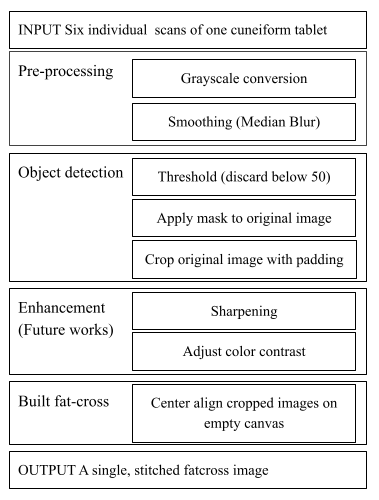
Manually, a six-sided tablet is scanned on each side on a flatbed scanner and sent for post-production, in which the images are digitally enhanced and stitched in the form of a “fatcross” using programs like Photoshop. Automation of such image processing will include 1) preparation of the image data, 2) image segmentation with methods like thresholding, and 3) accurate assembly of separate images. This research aims to identify a simple and effective edge detection method and its implementation parameters to automate building a fatcross.
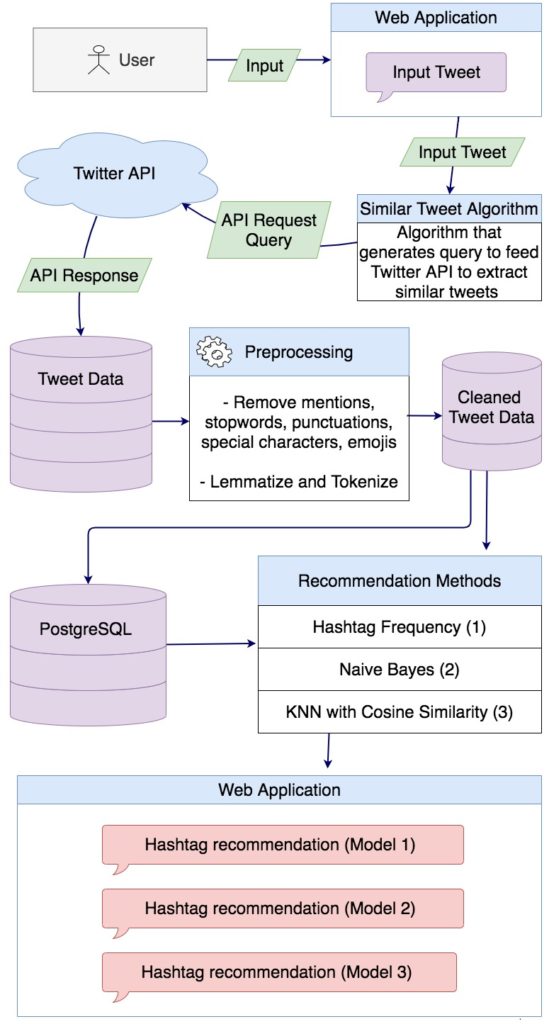
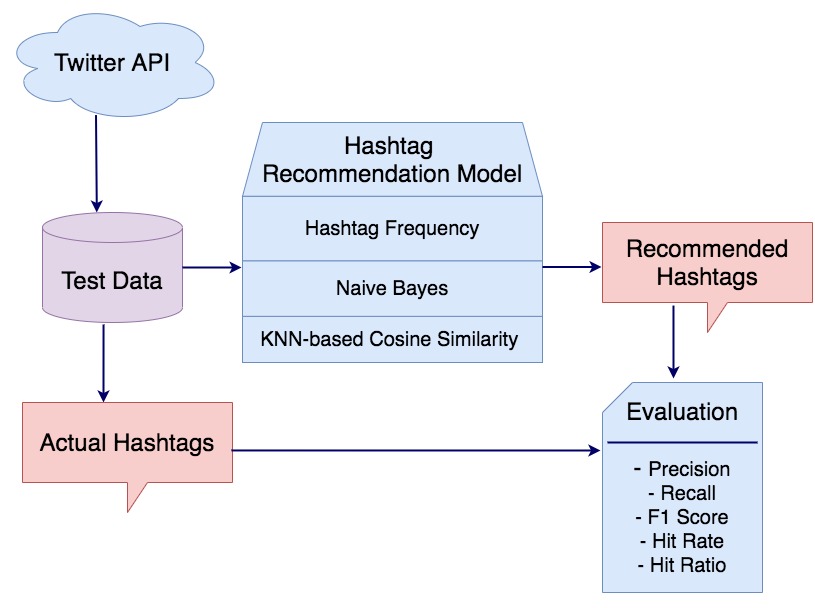
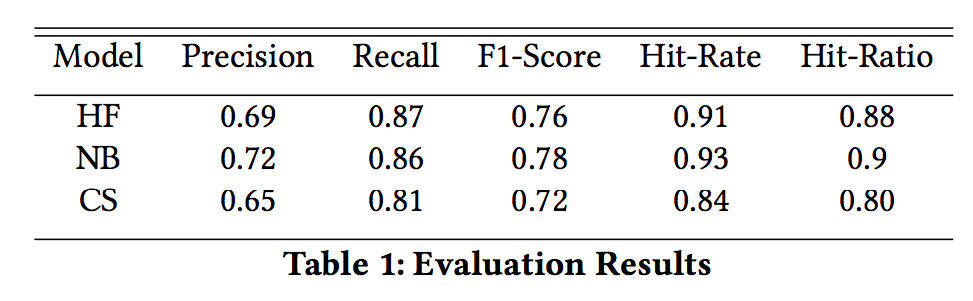
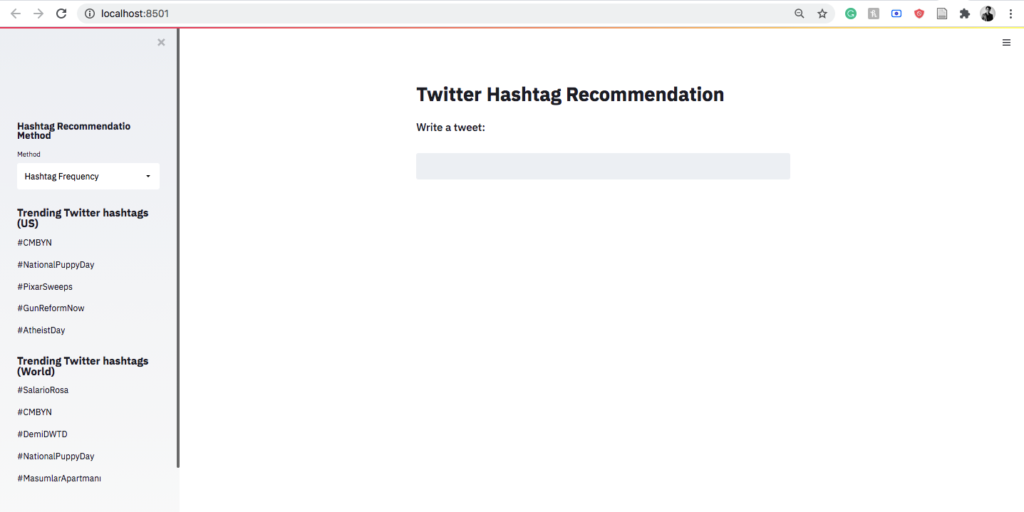
For Twitter, a hashtag recommendation system is an important tool to organize similar content together for topic categorization. Much research has been carried out on figuring out a new technique for hashtag recommendation, and very little research has been done on evaluating the performance of different existing models using the same dataset and the same evaluation metrics. This paper evaluates the performance of different content-based methods(Tweet similarity using hashtag frequency, Naïve Bayes model, and KNN-based cosine similarity) for hashtag recommendation using different evaluation metrics including Hit Ratio, a metric recently created for evaluating a hashtag recommendation system. The result shows that Naive Bayes outperforms other methods with an average accuracy score of 0.83.
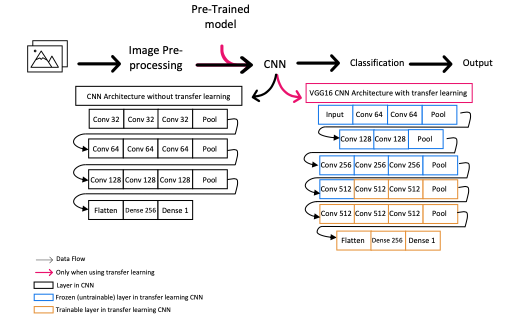
Artificial Intelligence (AI) has been used extensively in the field of medicine. More recently, advanced machine learning algorithms have become a big part of oncology as they assist with detection and diagnosis of cancer. Convolutional Neural Networks (CNN) are common in image analysis and they offer great power for detection, diagnosis and staging of cancerous regions in radiology images. Convolutional Neural Networks get more accurate results, and more importantly, need less training data with transfer learning, which is the practice of using pre-trained models and fine-tuning them for specific problems. This paper proposes utilizing transfer learning along with CNNs for staging cancer diagnoses. Randomly initialized CNNs will be compared with CNNs that used transfer learning to determine the extent of improvement that transfer learning can offer with cancer staging and metastasis detection. Additionally, the model utilizing transfer learning will be trained with a smaller subset of the dataset to determine if using transfer learning reduced the need for a large dataset to get improved results.
Writer identification based on handwriting plays an important role in forensic analysis of the documents. Convolutional Neural Networks have been successfully applied to this problem throughout the last decade. Most of the research that has been done in this area has concentrated on extracting local features from handwriting samples and then combining them into global descriptors for writer retrieval. Extracting local features from small patches of handwriting samples is a reasonable choice considering the lack of big training datasets. However, the methods for aggregating local features are not perfect and do not take into account the spatial relationship between small patches of handwriting. This research aims to train a CNN with triplet loss function to extract global feature vectors from images of handwritten text directly, eliminating the intermediate step involving local features. Extracting global features from handwriting samples is not a novel idea, but this approach has never been combined with triplet architecture. A data augmentation method is employed because training a CNN to learn the global descriptors requires a large amount of training data. The model is trained and tested on CVL handwriting dataset, using leave-one-out cross-validation method to test the soft top-N, hard top-N performance.
Software Architecture
Workflow
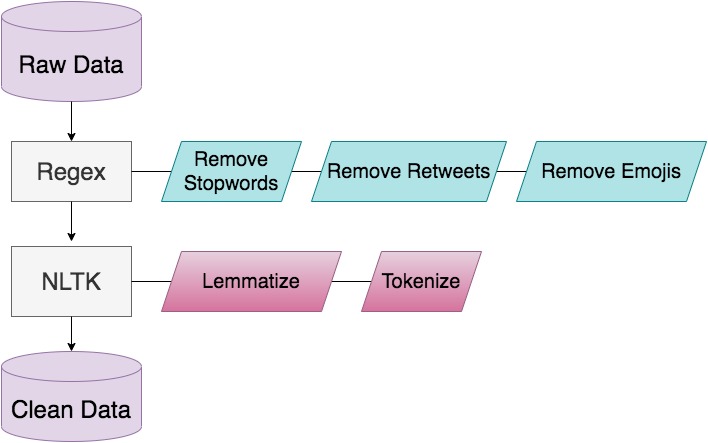
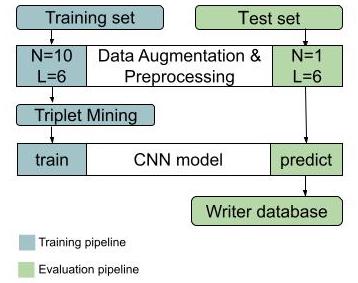
I’m using CVL writer database to train the model. All handwriting samples go through the data augmentation and pre-processing step to standardize the input for CNN. The samples in the training set get augmented, whereas only one page is produced per sample for the test set. The triplets of samples are chosen from each batch to train the CNN. The output of the CNN is a 256D vector. In order to evaluate the model, we build a writer database for samples in the test set.
Data Augmentation
Each handwriting sample goes through the same set of steps: 1. Original handwriting sample.
2. Sample is segmented into words.
3. The words from a single sample are randomly permuted into a line of handwriting. The words are centered vertically.
4. Step 2 is repeated L times to get L lines of handwriting. These lines are concatenated vertically to produce a page.
5. A page is then broken up into non-overlapping square patches. The remainder of the page is discarded. The resulting patches are resized to 224×224 pixels.
6. Steps (4) and (5) are repeated N times.
7. Finally we apply binarization. The patches are thresholded using adaptive Gaussian Thresholding with 37×37 kernel.
CNN framework
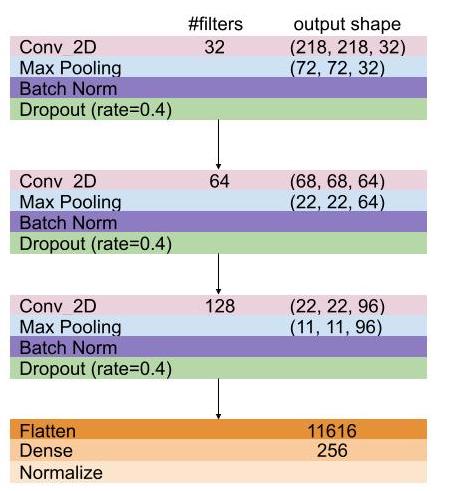
The CNN model consists of 3 convolutional blocks followed by a single fully connected layer. Each convolutional block includes a 2D convolutional, batch normalization, max pooling and dropout layers. The final final 256D output vector is normalized. I implemented this CNN framework in keras with tensorflow backend.
The model was trained for 15 epochs with batch gradient descend and Adam optimizer, with an initial learning rate of 3e-4. 10 epochs of training with semi-hard negative triplet mining was followed by 5 epochs of hard negative triplet mining.
Stock Prediction, Sentiment Analysis, Stock Price Direction, Social Media Sentiment
1. Abstract
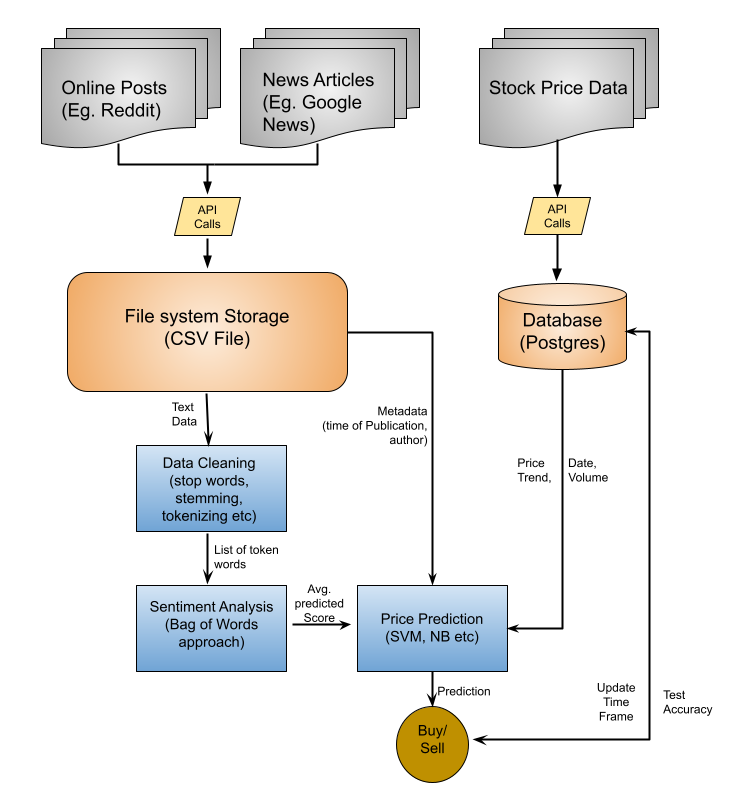
Due to the current pandemic of the COVID-19, all the current models for investment strategies that were used to predict prices could become obsolete as the market is in a new territory that has not been observed before. It is essential to have some predictive and analytical ability even in times of a global pandemic as smart investments are crucial for securing the savings for people. Due to the recent nature of this crisis, there is limited research in tapping predictive power of market sentiment when a lot of people are deprived from extracurricular activities and thus have turned their focus in capital markets. This research finds that there is evidence of market sentiment influencing stock prices. Adding market sentiment to the classification improved the prediction power of the model as compared to just price and trend information. This shows that sentiment analysis can be used to make investment strategies as it has influence over the price movements in the stock market. This research also finds that looking at the sentiment of posts up to one hour into the past yields the best predictive abilities in price movements