Build a rough machine learning pipeline for testing. Worked with Ajit to update timeline. Started with the first draft of paper.
Progress
on 2018-09-30
with
No Comments
Build a rough machine learning pipeline for testing. Worked with Ajit to update timeline. Started with the first draft of paper.
I am certain at this point that I will be going in a direction where I will be doing research on a database. My first thought was to explore how to store Tree Data Structures in Postgresql. Which led me to then think about indexes in relational databases and finding an open source relational database that is less mature than Postgresql and improving on the way they store their indexes. Firebird is one that popped up onto my radar. I am unfamiliar with it and still need to do background research. Later, it was pointed out to me that relational databases in general are very mature and don’t have as much room for improvement especially when compared to Time Series Databases. My two ideas are to improve the way indexes are used in Time Series Databases and in Relational Databases. My next steps include looking into what open source databases of these types exists and how they use their indexes.
For my project, optimizing an AI agent for Dungeon Crawl Stone Soup, I’ve recently changed the scope of my project somewhat. Instead of trying to improve the AI agent’s chance of winning a game of DCSS, I’m now working to optimize its chance of success at delving past the first floor of the dungeon.
This different scope has several benefits:
Some example results of preliminary trials are as follows:
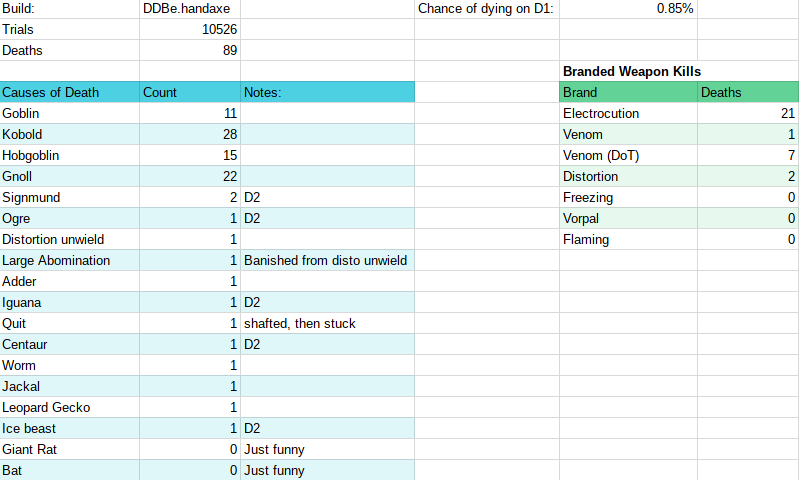
Some bug fixing and tweaking of the algorithm is necessary to avoid accidental “shafting” to lower floors of the dungeon. Additionally, with the high rate of success you see above, it may be necessary to choose a weaker starting character to make room for significant improvements.
Nothing much to report, worked on my annotated bibliography and am narrowing down my interest to just two of my three ideas. Currently leaning towards 2d stitching, potentially expanding it to include some 3d point cloud work as well, but that is only a thought at the moment. The amount of work that has gone into predicting premier league games has taken a lot of interesting directions, but I’m not sure thats what I want to focus on.
I’ve laid down the bare bones for my thesis paper.
With the main project however, I am running into problems with my virtual machines and blockchain code, rather I keep running into problem after problem with them. I plan on talking to my adviser about this and try to figure out something. Biggest issue is that I can reliable to collect and study my data until I get this set up, which is a problem.
This week I’ve gotten minorly stuck. I know that NVDA is able to grab — and speak — certain information about the data visualizations I’ve created(it might say, for example, “graphic New York” when I navigate to a point representing the population of New York). But when I try to grab information about those navigator objects, I end up grabbing objects whose roles are either “unknown” or “section.” These objects also don’t have names, descriptions, basic text, or any useful attribute containing the text information NVDA is able to provide, but isTextEmpty also consistently returns False. At this point I’m not entirely sure where I should be looking to keep digging — I’ve looked into the code for NVDAObjects, TextInfo, speech.py, etc. I’ve also dug into forums and things and found an NVDA development mailing list, so I posted a response to a forum thread asking for clarification about something that might be relevant to this issue and sent a more detailed account of the issue I’m facing and request for guidance to the mailing list. Hopefully I’ll get this sorted out by this time next week.
During the past week, I run into a few problems. I kept getting a PendingDeprecationWarning coming from one the methods used from Scikit Learn. It seems that something has changed or is currently changing on Numpy that affects Scikit learn modules. For now, I was able to ignore the warning. However, I will look more into it to make sure that the warning won’t become a bigger problem in the future.
I was able to find a Scikit wrapper for TSVM, and I tried implementing it. I am currently getting an error coming from the implementation of the TSVM. I suspect it is due to being written for Python 2. I will make the necessary changes so I can use with the current version of Python. For example, it uses xrange() instead of range(). I believe that once I make the necessary changes, the TSVM should work as suspected.
Moreover, the Blogs corpus was too big to be imported as CSV on Google Sheets. So I am currently implementing a simple script which will randomly create a smaller sample, which I will manually label afterward.
Created a smaller dataset using pySpark for training and testing the fake news model.
I’ve been researching Voronoi graph regions and their usage in recommendation system. I’m particularly interested in finding open-source implementation of Voronoi graph regions usage. I’ve also been reading and researching FiveThirtyEight’s gerrymandering maps and how they created their maps of different districting schemes. I am especially interested in the algorithm they used for one of the districting plans. Lastly, I decided on a mapping tool, Leaflet, which is an open-source JavaScript library for interactive maps. I started building the visualization tool using Leaflet and the algorithm taken from FiveThirtyEight.
Read the papers and summarized them.
I am leaning more towards the gesture control system idea, but at the moment it seems like I keep finding more and more challenges to overcome with this project. Typing with gestures may not be feasible, and if I use a camera, there would be lag, making it suck.
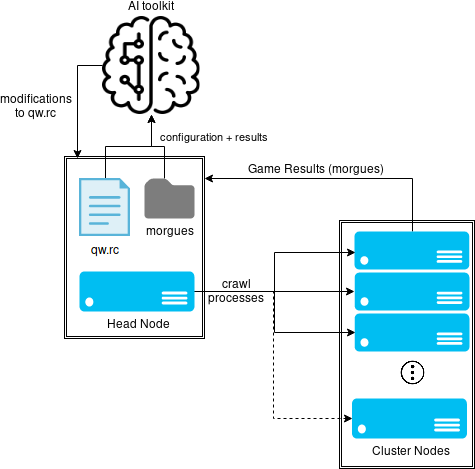
For my senior project, I’m working on optimizing the performance of qw, an AI Agent developed to play (and sometimes win) the game of Dungeon Crawl Stone Soup.
To reduce the search space and make optimization with machine learning faster, easier, and more efficient, I’m limiting the bot to only explore the first floor of the Dungeon. This takes significantly faster to complete compared to running through a full game, and the AI agent will be faced with a much smaller set of monsters, items and dungeon features.
Currently, the plan is to adjust minor variables in the coding of qw to see if it can survive the first floor of the dungeon with a higher rate of success.
Following is my experimental design.
My project ideas have been evolving since starting to research articles. My main fields of research have been in audiovisual synthesis, motion control for virtual instruments, and algorithmic music composition. I have found lots of articles including a good one by alumni Edward Ly that relates very directly. I think his project will be very useful for what I want to work on. He was focusing on conducting an orchestra which is not what I want to do, but I think there should be some overlap and hopefully I could build off of some of his work. I’m still scratching the surface of the research field though and have lots more to find out.
Have found a working software for my Virtual Machines and the blockchain program to run on them, was harder to find than I thought it would be. I have my timeline finished and solidified thanks to my talk with Ajit, so I know what I am doing week by week. I am difficulty actually installing the blockchain onto my Virtual Machines and am not entirely sure why, need to investigate that now and get back on-top of things.
Also have a number of small website files to run on the program for the purposes of my tests. Will see how they work when I get the system fully set up.
I spent the past week reading related papers to my three ideas. It helped me gain a better understanding of the scope and challenges associated with each potential project. I also met with Ajit and discussed the projects. I believe I am leaning more towards working on the RFID technology as it seems a distinct idea and has a fair scope.
I finished making an additional data visualization — a Sankey diagram this week. I looked into NVDA’s built-in logging system and decided I didn’t want to use it to create my logs because it includes — even at the bare minimum settings — too much information that is not relevant for my purposes. Writing to a blank output file makes the most sense as a course of action at this point. I found an existing add on for NVDA written by Takuya Nishimoto (found here) that draws a box around the NVDA “focus object” and “navigator object.” This was helpful because by using it I was able to see that those objects don’t actually completely reflect what the screen reader is picking up and what information it’s focusing on. Often those objects represented an entire window or page, so I need to search for how NVDA is pulling out those more granular details.
Completed corpus creation. Filter the dataset and collecting data from Facebook. Automated process using pyspark. Reduced 40GB file to 9 GB and needed to be cleaned for machine learning processing.
Worked with setting up sci-kit learn and testing environment. Got Craig to give me access to Pollock and Bronte.
Met with my advisor twice, worked on an updated timeline. Worked out a design framework and prepared the presentation slides.
This week, I decided to change my first project (soccer coaching tool) and do something different. I haven’t really thought to utilize my knowledge I’ve gained from classes and I want to do some type of AI or ML project.
Additionally, I found articles that relate to my ideas.
This week I revised my proposal, framework and timeline. These revisions are summed up in my presentation for this week (slides can be found here).
-I met with Kendall to get my ACM membership
-I continued refining my ideas.
-I talked with music professor Forrest Tobey about my ideas and projects that the music department is interested in.
Retrieved the FakeNewsCorupus Dataset from Kaggle. The file size is 40GB and I am thinking about selecting a subset of it to create a smaller dataset. Sci-kit learn cannot load the data on my computer and I need to use a cluster system. Will talk to Craig about getting the issue fixed.
I want to work on a system that manages courses, students and registration similar to Earlham directory but with better management and user-interface. The project will entail a large scale design and breakdown of the problem into smaller subproblems. I will need to learn to work on managing database, and perhaps writing a REST api to create the communication between the system and the database. It will involve easy to understand graphics, and a user friendly interface.
I want to build a system similar to Uber- online tracking, separate accounts for users and online payment. The project will entail several moving pieces. I will need to use different tools in order to store the data, process payments, and have authorization in place. A great portion of the project will be designing and understanding how to make the different pieces work together.
The project will be on predicting the price movements and trends of stocks based on the sentiments expressed on social media or newspapers. This will involve parsing and sentiment analysis of the data and studying its comparison with the price trend of a group of stocks. The project will entail usage of different sources for managing and parsing the input sentiments. A great portion of it will also be on using machine learning to study the correlation between the price and polarity of sentiments.
Python Module for Image Processing
• Is your proposed topic clearly a research activity? Is it consistent with the aims and purposes of research?
Yes. I plan to create something new and make some small breakthrough.
• How is your project different from, say, software development, essay writing, or data analysis?
It is different because, although those are necessary to complete components of my project, they are not the purpose of this project.
• In the context of your project, what are the area, topic, and research question? (How are these concepts distinct from each other?)
The topic and area of my research has to do with image processing. My research question is different from the topic because it is more narrow and specified. My research question is looking at image processing text found over an image/video. For example, reading the overlaying text that appears from a camera in a home video that usually says the date, instance.
• Is the project of appropriate scale, with challenges that are a match to your skills and interests? Is the question narrow enough to give you confidence that the project is achievable?
This project seems of appropriate scale, however I can always extend this project seeing as it is a python module and adding features to it would be conceivable. It seems appropriate scale seeing as it will be from scratch. The challenges of this project that match my skill set is using python, however, image processing itself is not which is an interested I am excited to learn more about. I am confident that this is achievable in a semester.
• Is the project distinct from other active projects in your research group? Is it clear that the anticipated outcomes are interesting enough to justify the work?
I am working individually, however in the 388 group this project is very distinct because I am the only person in the group who has proposed a python module and a project related to image processing.
• Is it clear what skills and contributions you bring to the project? What skills do you need to develop?
The skills I need to develop is knowledge in image processing. I have experience with OpenCV, an image processing library, but I do not know the mechanics of how image processing works.
• What resources are required and how will you obtain them?
I will most likely be needing resources related to AI and image processing, most likely specific chapters in books along with online resources.
• What are the likely obstacles to completion, or the greatest difficulties? Do you know how these will be addressed?
I anticipate this project to be made from scratch, it will take specific deadlines and time management to address the difficulties in completing this project.
Platform for viewing data
• Is your proposed topic clearly a research activity? Is it consistent with the aims and purposes of research?
Yes, I don’t simply plan to create something, but create a minor, realistic breakthrough for a senior undergrad.
• How is your project different from, say, software development, essay writing, or data analysis?
It is different because, while these are a components of this project, they are not the purpose or specific question of my research. They are tools to help me answer my research question. My project is about creating a platform that will store data in a binary tree and to see how storing large amounts of data in a binary tree structure would work.
• In the context of your project, what are the area, topic, and research question? (How are these concepts distinct from each other?)
The context is of my project has to do with storing data, specifically binary tree data. The area is in big data and storing it. The topic has to do with storing and displaying binary tree data and algorithmically how to do that. The broad problem that I am investigating is storing binary data, so my research question is that.
• Is the project of appropriate scale, with challenges that are a match to your skills and interests? Is the question narrow enough to give you confidence that the project is achievable?
The scale is appropriate, if anything it is too large. The challenges in this project that match my skills and interests are dealing with large amounts of data along with creating a visualization for it. Furthermore, there will be a big challenge in figuring out the algorithmic part of this project for ingesting large amounts of data in an appropriate time. Because most of the components of this project have already been done in other tools, figuring out how to do them should be within my reach.
• Is the project distinct from other active projects in your research group? Is it clear that the anticipated outcomes are interesting enough to justify the work?
I am working individually on this research with one advisor, but in comparison to the wider group of 388, there are not projects from last week’s presentations that relate to this topic, so it is safe to say that this project is distinct from other projects in the research group. My anticipated outcome is to have a platform/database for ingesting and displaying binary tree data, which I personally find interesting and I believe justifies an entire semester’s work of work.
• Is it clear what skills and contributions you bring to the project? What skills do you need to develop?
Yes, to the project I bring some knowledge about big data, binary trees, some D3 and languages to build the project. Skills I need to develop are knowledge about ingesting large amounts of data and algorithms for storing data into binary trees along with some other complex algorithms and skills to create such a platform.
• What resources are required and how will you obtain them?
Many resources are required, some having to do with data structures, other with web development and others with moving large amounts of data. I plan to obtain them primarily form the internet and picking apart other such tools.
• What are the likely obstacles to completion, or the greatest difficulties? Do you know how these will be addressed?
There are many components of this project that will be difficult to push through, using time management and helpful pointers from my adviser. Furthermore, since this project entails creating a platform (probably web) from scratch, I will probably need to specify specific deadlines for myself to keep progress steady.
Computer Echolocation
• Is your proposed topic clearly a research activity? Is it consistent with the aims and purposes of research?
Yes, although I will be creating physical, it will be productive and novel.
• How is your project different from, say, software development, essay writing, or data analysis?
This project deals specifically with the intersection of software and hardware. So, it also has a component of hardware in addition to these specific things. Additionally, although hardware, software development, essay writing and data analysis are involved, my project is about exploring the intersection of hardware and software in the are of computer echolocation.
• In the context of your project, what are the area, topic, and research question? (How are these concepts distinct from each other?)
The topic is computer echolocation, however my research question is much more narrow and specific because it deals with the intersection of software and hardware in the area of computer echolocation.
• Is the project of appropriate scale, with challenges that are a match to your skills and interests? Is the question narrow enough to give you confidence that the project is achievable?
My project is both appropriate scale for the semester and is not too ambitious that it would take longer than a semester to create. This project matches my interest in echolocation and matches my skills in software development.
• Is the project distinct from other active projects in your research group? Is it clear that the anticipated outcomes are interesting enough to justify the work?
Although this project is individual and will not be done by an entire group, the overall group of 388 has thus far not mentioned any project having to do with echolocation. The anticipated outcome is to have a robot that is blind but uses microphones to understand it’s surroundings, I personally find this very interesting and am confident that the work is worthwhile given the anticipated outcome.
• Is it clear what skills and contributions you bring to the project? What skills do you need to develop?
Yes, I will be needing to develop knowledge and experience with hardware. The overall contributions involve hardware, software and an understanding of echolocation.
• What resources are required and how will you obtain them?
Most of the resources needed are available online. I will be needing resources that explain the varying hardware that exists, what they do and how to use them.
• What are the likely obstacles to completion, or the greatest difficulties? Do you know how these will be addressed?
The obstacles that are in my way for this project are obtaining hardware. I will address this difficulty with my adviser.
Have set up and arranged weekly meeting times with Ajit as my adviser. We’ll be meeting weekly at 4:00pm on Wednesday.
I have better evaluated what pitfalls and goals I will need to be aware of for my research, and have worked on re-evaluating my timeline. The protocols for managing the data are important, as well as the time overhead of the whole system, and so regular testing and experimentation are going to be important in working things out.
I have also found a few good virtual machines to run my tests on, still selecting which specific one I’ll use..
Deploying Software Defined Networking (SDN) for cloud endpoints
Topic Description: Using the cloud infrastructure, a Software Defined Networking (SDN) can be deployed for cloud endpoints. SDNs are used to connect data centers to public cloud providers to create a hybrid cloud network to manage micro-segmentation and dynamic scaling, implementing SDN with the mobility of cloud endpoints creates a more efficient hybrid cloud network capable of better managing network traffic and organizing the data.
Content Management System (CSM) for Android applications
Topic Description: The ability to flexibly manage mobile contents allows the app builders to create Android apps more efficiently and faster. Building a custom backend for the content management of the app is tedious work so, having a CMS for Android will allow developers to easily update the app. Certainly, the editors would be able to set up the content structure according to the need of the project.
Smart lock security system for Home
Topic Description: The capabilities of smartphones and (Internet of Things) IoT has made it possible for smartphones to take the role of remote control. I want to build a security lock system which can remotely be controlled using the smartphones. The system could also integrate Radio Frequency Identification Device (RFID) tagging which then allows the smartphone to be used as only a security monitoring device.
Idea 1: Soccer Coaching Tool
Did research to find similar softwares for coaching.
Idea 2: Hand/Finger Gesture Sensor for Browser Control and Navigation
Read research papers regarding similar ideas about monitoring hands and fingers. Found devices that provide the sensors and can easily be used with Google Chrome browser.
Idea 3: Thermal Modeling of Building(s) on Earlham’s Campus
Create 3D map of a building or buildings at Earlham and simulate the dynamics of energy loss and generation. Read papers regarding empirical model of temperature variation in buildings.
In this past week, I’ve found and simplified 2 types of data visualizations that I think would be useful for testing purposes: a slopegraph and a bubble graph. I’ve run some preliminary tests with NVDA on them to see how it’s trying to process them and developed basic plans on how to process that information in a way that makes more sense to NVDA.
In the upcoming week, I plan to finish gathering my data visualization test sets and coming up with those early transformation ideas and begin looking into how to get NVDA to transcribe what it’s looking at and output that to a file so it’s easier to track and document its process.