Attached are the final versions of my paper and poster
Final Paper and Poster
on 2019-05-03
with
No Comments
Attached are the final versions of my paper and poster
This week, I spent time figuring out how to make the software publication ready, and discussed with Craig on whereabouts of the server and database
This week, I finalized my poster and prepared my paper for the evaluation draft submission. I also met with Craig to discuss taking the application live.
This week ive been working on revising my paper according to the feedback i got and suggestions from Xunfei.
Ive been trying to polish out any remaining functionality issues and format it better for presentations.
This week, I started working on my poster, and revised my paper based on the feedback I received from Dave and Ajit
This week I tested out the reader with student interface, and checked if self-check in and check-out worked properly. I also met with Craig and discussed plan to migrate the application to the server and perhaps have it ready for the EPIC expo.
This week I spent most of my time working on the paper, and finished the implementation and design sections. I also started working on the administrator interface and got a good portion of it done.
This week I have been working on my paper both revising the submitted partial draft and adding the portions that were not done yet.
I have also done some work on my project itself. I have been doing a lot of refactoring. I made it so all the variations I am testing can be turned on and off via toggle buttons and all things that need to be initialized to run the patch are accessible in the main patch window instead of having to open the subpatches. I also revised portions of my project that had large repeated sections of code.
This week I:
-worked on my paper draft
-worked on fixing bugs in my software
This week I finished implementing a rough version of the student user interface. I spent a considerable time discussing the logic behind to student check out and check and what measures were necessarily to put in. I received feedback from Ajit on the design, and modified my approach based on that.
-I created a large variation to my algorithm that spacializes the visualization based on the ratios just intonation ratio instead of being directly correlated to the frequencies. This involved implenting a new module that calculates the just intonation ratio and scales the sine wave visuals to that.
-I created tables to use in my paper draft and started turning my outline into my draft.
This week I discussed the structure of my paper with Ajit, and received feedback on how to explain the design and implementation sections. I also started working on implementing the student user interface.
This week I did the following tasks:
-Met with Dave about the structure of my outline and my experimental results section
-Met with Forrest to get feedback on my work.
-Began to work on a new variation of my algorithm based on Forrest’s feedback
-Read chapter 5 in writing for computer science
This week I finalized the schema for the database with Ajit, and familiarized myself with the PostgreSQL commands after receiving the log in information from Craig. I faced an unexpected challenge with the ordering of the RFID device from Ebay. Instead I researched for two days and found a few other cost friendly options in the US, and have proposed to the department to purchase one of them.
I am planning to finish all the software end of the project by the time I get my hands on the device!
This week I accomplished several things:
-Reconfigured the way my patch combines matrices to avoid issues I was having w crossfade
-implenented horizontal movement after note press
-Organized parts of my project into sub-patches and cleaned up some stuff
-Implemented envelopes connected to sound and video out
-Created an outline for my paper
This week, I finally got my own laptop so I redownloaded all the necessary software and libraries for my gesture recognition system. Using the OpenCV library in Python, I was finally able to use the camera to detect the hand by separating the background with the foreground via thresholding. Then, I used findContours to identify the hand within a region of interest (roi). Finally, I made a copy of the the frame containing the roi and displayed the video in binary black and white. My code can now detect the hand with a static background.
This week I met with Ajit and discussed some of the necessary features for the user interface that the administrator will be using. This involved seeing a list of recently checked out items, adding new objects, and adding new users. I also met with Craig and discussed the back-end work. We decided to use Django and PostgreSQL.
Here is what I worked on for my project this week:
-Worked with poly tool to process two simultaneous notes.
-Got it working but temporarily disabled the circle of fifths map table-Now midi messages are sent to two paths for separate notes.
-Using xfade to combine matrices is not good, colors are still evenly distributed throughout the whole matrix instead of following freq mapping.
-Patch is getting crowded need to figure out in and out tool to split up and organize project.
-Talked with Xunfei about getting Max installed on some Earlham laptops
Researched how image processing works (tutorials, examples using python and open-source software OpenCV). ~20 minutes on 1/19/19, ~30 minutes on 1/21/19
Made sure all necessary software was downloaded to my computer. ~30 minutes on 1/17/19
Adjusted timeline. ~15 minutes on 1/23/19
This is my first post for CS488.
My first idea is for a application that allows the computer to be navigated with gesture control, initial thought is to use the camera that is on almost every laptop to map the mouse pointer between say the thumb and the forefinger, and when the thumb and forefinger touch emulate a the click of the mouse. Further interface could also be implemented such as a virtual keyboard or talk to text features, basically attempting to replace a mouse and keyboard, further research needed.
My second idea is either a stand alone software or a Photoshop add on for real time pixel art animation editors. Given a sequence of images with a specified distance apart, color pallet and speed at which to move through the images, one could make a change and the animation would update real time, also allowing the change of color pallets.
My third idea is a personal budget planning and expense tracking app. I person can track what they buy by inputting the cost of an item and categorize that item falls into (possibly further subcategories for more in depth statistics) ie $16.69 on groceries on 1/21/19, $32.55 on cloths on 1/22/19 etc. One can input there salary and how much they want to not spend and the app could keep track and suggest a budget for you, give statistics about your spending patterns etc.
I have gotten off to a relatively smooth start on my project. Xunfei is going to be my adviser and I have scheduled a meeting with her for tomorrow morning. I have prepared to present on my topic in class tomorrow. The majority of my time this week I spent starting my project implementation. I am still learning how to use Max/Jitter effectively but here are some of the things I have done:
-Map color values to MIDI notes.
-Map a saw waveform function over the x axis with scale relative to note frecuency
-Make the saw function scroll horizontally at a rate relative to frequency
-Crossfade the color and waveform matrices
With all of this together, my projects output visual output represents a single note at a time. Obviously it is a pretty rough version of what I want the eventually single note visualization to look like but the foundation of representing tone through color and pitch through wave frequency is functional and has no noticeable latency between note press and display.
This week I met with Ajit for an hour. We went over timeline and design of my project. I also met with Craig and ordered the RFID reader and tags after approving them.
This week after receiving feedback from Xunfei on the second draft of my paper, I updated it with respect to her comments. I also followed up with Craig; he is going to purchase the equipment early next semester.
Worked on the poster and got it printed. Copy of the poster attached.

This week I received feedback on the second draft of my proposal from Xunfei. I spent time updating the proposal with respect to her feedback. I also met with Craig and decided on a set of RFID reader and tags. Craig is going to purchase them before the end of the semester.
This and the previous week, I spend my time trying to beat my way through a variety of problems related to one specific module of my project’s code. After talking over it with my adviser I have shifted both that piece of code and what should be taking my priority. The original model of my project was that, after the blockchain authenticated a ‘website’ so that it could access a user’s ‘cookie’ file, the functions would be passed over to the user from the website’s server to the user’s. My adviser suggested I simply change this so that the user has both the file and the functions, and that the website simply sends a signal if the blockchain transaction was approved. The actual process of the functions on the cookie file are not as important as the blockchain authentications, which is the center of the project.
The refocusing suggestion was also on everything related to my experiment, such as the details of my experimentation, and the discussion of further research. Leave it so that I have as much done as possible, with that window left for my experimental results.
This week, I was focused on making the poster and including the final results of my research.
This week I haven’t been able to work much because of some traveling. However, I was able to think more about my design decision including the RFID reader that I will buying. I have selected a device, and discussed with Xunfei. I am planning to meet with Craig and possibly purchase the equipment before the end of the semester.
This week I received feedback from Xunfei on my initial draft of proposal. I spent the last few days thinking more about design and trying to answer some questions that Xunfei raised. I tried referring back to my sources and it has been very helpful.
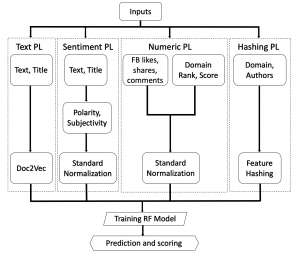
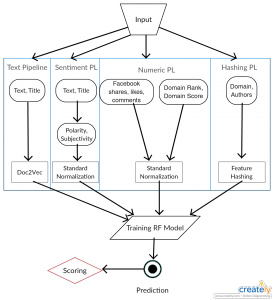
Here is an updated machine learning pipeline for my project.
Submitted the CS second draft on Wednesday and waiting for Xunfei’s Feedback. The demo presentation went well without much questions from the audience. On working on making the poster for the presentation on Dec 5.
This week I did a lot of research into how jitter works and how it communicates with max and msp objects. In the process I found a few more helpful sources to replace some of the less relevant related works that I have. The past couple of days I did some programming on a max patch to familiarize myself with the basics of converting an audio signal into jitter output. I still have a lot to figure out but I was able to create a visual representation of a basic sine wave. I learned about audio sample rates and how to buffer an audio stream into a matrix.
I have been reading up on documentation and research for the Leap Motion controller so that writing the code will be more easily managed in the future. I have also been updating the commented portions of my proposal, and I’m also changing certain sections so that it will make more sense with the context of the scope of my project.
This week I worked more on my proposal after I received constructive feedback from Xunfei. I explored some of the papers further in depth to learn about how to design my project. I am also researching on what tools to buy.
Worked on the demo presentation. Experimented with 2 datasets each taking 4 hours of run time. One observation I found is that changing the labels of the fake news changes the accuracy. It was found that detecting reliable news rather than fake news was statistically better in performance.
My proposal adviser will be Dave. We met last friday to talk about my project idea. one note he gave me was to be clear what parameters I will use to measure my success since my project is almost completely software designing as opposed to research. Over the next few weeks I need to revise my proposal and prototype some basic features of my audiovisual synth.
This week, I met with Craig, and discussed what kind of tools I need to purchase for the project, such as RFID reader and Tags. There are many options however, I need to make sure to purchase a reader that allows backend manipulation. I am scheduling a meeting with Ajit, to discuss this further with him.
The front end development part for my project is almost complete. The database setup and connection is completed. The integration of backend machine learning model with flask has worked. The flask prediction model has also been linked with the frontend. There are some issues with websites that are not blog and I am fixing the issue. Next step is to make a retrainable model.
I read more papers where the researchers used a Leap Motion controller to recognize gestures. People use a variety of methods to classify static and dynamic gestures. One of the more frequently used methods takes advantage of a ‘Hidden Markov Model”.
Additionally, I did research on the software available for the Leap Motion controller. By the end of this week I will finalize the framework of my project.
This week I accomplished these tasks:
-found the rest of my 15 sources for my paper
-Met with Xunfei to discuss my design outline
-wrote my project proposal
-Did a second pass of a few of my papers
Worked on my final paper some more, as well as familiarizing myself with my two-node blockchain set-up. I’m still working out how to integrate my other modules into the system, particularly how to pass a function from one server to another through the chain, but I am making progress and anticipate that I will be finished with that tomorrow at the latest. I’ve taken a glance at how my poster will be set-up, but it’s been a tertiary concern for the past few days.
I reviewed more papers over the week to get a better sense of what I would need to address in my proposal. I also met with Xunfei and discussed the structure of my project as well as how to work with some of the shortcomings of an RFID system
Worked on the front end component of the project. With the sys admin telling me that they cannot host flask for my project. I started to look for alternatives. Heroku could not be used as it did not provide support for sci-kit the way I needed. Worked with Ajit to edit my first draft paper. Mades some figures of the architectures.
I have successfully set up a blockchain system, and run experiments to familiarize with how it works and the involved processes. My first draft of the paper is mostly complete and will be ready by the deadline tonight. It will not be a complete paper, as the evaluation and conclusion sections will be mostly empty. Advice and consultation from Ajit on the paper is making me restructure some things, and has given me a better reference point for what is required and expected. The paper right now also does not have direct citations to any of the references, as the documentation on how that part works is confusing me. I decided to move that part of the work to the second draft.
This week I finished writing the literature review and looking in depth into the literature available for my two topics: RFID in library and Sentiment analysis for stock prediction. I believe I will proceed with RFID technology and research more about the resources and different components of the system.
Finished the machine learning pipeline with actual experimentation. Having issues getting Flask setup and have been in touch with the SysAdmins. Halfway through the first draft of the paper. Made new design for the system architecture.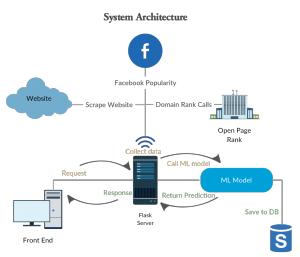
Last week I was able to set-up a two node blockchain on the Earlham Cluster, after working through technical issues with the help of Craig. However, I discovered several problems with this structure this week. I couldn’t re-access an already created chain, and getting nodes to connect to it was giving me errors. Unfortunately I had spent the Thursday and Friday of that week working on my draft and module designs, so by the time I encountered the problem I wasn’t able to meet and discuss with Craig until Monday. We talked about it and are working on solving the issue together, but he said he needs to poke around and look at things in the cluster. I tried experimenting with the issue on my end, using the program on my desktop and laptop computer, as well as ssh-ing into the servers, and have had little results to show for it.
This week I dedicated my time towards designing my proposal idea. After my literature review I decided I wanted to continue my audiovisual project. I read through the documentation for the jitter programming language to see what would be feasible to work on. Then I designed a basic architecture for how the synthesizer would convert MIDI note messages into visuals.
I did an experimentation with Sci-kit Learn. The run-time for the program was more than 2 hours. Testing the multiple dataset has been an issue lately.
Progress on the draft of the paper. Related works is almost completed.
This week I made good progress in my research. Here are some of the things I have done:
-Met with Forrest Tobey to discuss his past research involving motion tracking virtual instruments as well as visual capabilities of the Max/MSP/Jitter programming language
-Condensed my research papers that I will be using and selected 8 for each literature review
-worked extensively on writing my literature reviews
Worked on the first draft of the paper. Focusing on the related works and findings currently.
After talking to Ajit about the problems I have been running into with my virtual machines I’ve made the decision to switch to using the Earlham servers for the purpose of running my experiments and collecting data. There’s only one thing that still needs to be worked out and I intend to talk to Ajit about it. Due to poor sleep and bad time management over the last few days I am not as far as long as I should be, and I have not been able to run experiments yet. I will move correct this in the coming weeks and aim to catch back up to the work.
In the past week, I have been working on the related for my three project ideas. I wrote an annotated bibliography for each topic with five different sources. This week got rid of one of the ideas and decided to work on these two:
Build a rough machine learning pipeline for testing. Worked with Ajit to update timeline. Started with the first draft of paper.
I’ve laid down the bare bones for my thesis paper.
With the main project however, I am running into problems with my virtual machines and blockchain code, rather I keep running into problem after problem with them. I plan on talking to my adviser about this and try to figure out something. Biggest issue is that I can reliable to collect and study my data until I get this set up, which is a problem.
Created a smaller dataset using pySpark for training and testing the fake news model.
I’ve been researching Voronoi graph regions and their usage in recommendation system. I’m particularly interested in finding open-source implementation of Voronoi graph regions usage. I’ve also been reading and researching FiveThirtyEight’s gerrymandering maps and how they created their maps of different districting schemes. I am especially interested in the algorithm they used for one of the districting plans. Lastly, I decided on a mapping tool, Leaflet, which is an open-source JavaScript library for interactive maps. I started building the visualization tool using Leaflet and the algorithm taken from FiveThirtyEight.
Read the papers and summarized them.
I am leaning more towards the gesture control system idea, but at the moment it seems like I keep finding more and more challenges to overcome with this project. Typing with gestures may not be feasible, and if I use a camera, there would be lag, making it suck.
My project ideas have been evolving since starting to research articles. My main fields of research have been in audiovisual synthesis, motion control for virtual instruments, and algorithmic music composition. I have found lots of articles including a good one by alumni Edward Ly that relates very directly. I think his project will be very useful for what I want to work on. He was focusing on conducting an orchestra which is not what I want to do, but I think there should be some overlap and hopefully I could build off of some of his work. I’m still scratching the surface of the research field though and have lots more to find out.
Have found a working software for my Virtual Machines and the blockchain program to run on them, was harder to find than I thought it would be. I have my timeline finished and solidified thanks to my talk with Ajit, so I know what I am doing week by week. I am difficulty actually installing the blockchain onto my Virtual Machines and am not entirely sure why, need to investigate that now and get back on-top of things.
Also have a number of small website files to run on the program for the purposes of my tests. Will see how they work when I get the system fully set up.
I spent the past week reading related papers to my three ideas. It helped me gain a better understanding of the scope and challenges associated with each potential project. I also met with Ajit and discussed the projects. I believe I am leaning more towards working on the RFID technology as it seems a distinct idea and has a fair scope.
Worked with setting up sci-kit learn and testing environment. Got Craig to give me access to Pollock and Bronte.
Met with my advisor twice, worked on an updated timeline. Worked out a design framework and prepared the presentation slides.
This week, I decided to change my first project (soccer coaching tool) and do something different. I haven’t really thought to utilize my knowledge I’ve gained from classes and I want to do some type of AI or ML project.
Additionally, I found articles that relate to my ideas.
-I met with Kendall to get my ACM membership
-I continued refining my ideas.
-I talked with music professor Forrest Tobey about my ideas and projects that the music department is interested in.
I want to work on a system that manages courses, students and registration similar to Earlham directory but with better management and user-interface. The project will entail a large scale design and breakdown of the problem into smaller subproblems. I will need to learn to work on managing database, and perhaps writing a REST api to create the communication between the system and the database. It will involve easy to understand graphics, and a user friendly interface.
I want to build a system similar to Uber- online tracking, separate accounts for users and online payment. The project will entail several moving pieces. I will need to use different tools in order to store the data, process payments, and have authorization in place. A great portion of the project will be designing and understanding how to make the different pieces work together.
The project will be on predicting the price movements and trends of stocks based on the sentiments expressed on social media or newspapers. This will involve parsing and sentiment analysis of the data and studying its comparison with the price trend of a group of stocks. The project will entail usage of different sources for managing and parsing the input sentiments. A great portion of it will also be on using machine learning to study the correlation between the price and polarity of sentiments.
Have set up and arranged weekly meeting times with Ajit as my adviser. We’ll be meeting weekly at 4:00pm on Wednesday.
I have better evaluated what pitfalls and goals I will need to be aware of for my research, and have worked on re-evaluating my timeline. The protocols for managing the data are important, as well as the time overhead of the whole system, and so regular testing and experimentation are going to be important in working things out.
I have also found a few good virtual machines to run my tests on, still selecting which specific one I’ll use..
Idea 1: Soccer Coaching Tool
Did research to find similar softwares for coaching.
Idea 2: Hand/Finger Gesture Sensor for Browser Control and Navigation
Read research papers regarding similar ideas about monitoring hands and fingers. Found devices that provide the sensors and can easily be used with Google Chrome browser.
Idea 3: Thermal Modeling of Building(s) on Earlham’s Campus
Create 3D map of a building or buildings at Earlham and simulate the dynamics of energy loss and generation. Read papers regarding empirical model of temperature variation in buildings.
Started the project pipeline for Fake News Detection.
Ideas:
I realize my ideas are a bit general at the moment, but I am trying to make them more specific and novel after discussing with Dave and Ajit.
(Made my first entry as part of my Portfolio by accident)
January 23rd, 2018
Spent time thinking and researching for a third idea, decided to go with an adaptation of one of my other ideas. ~2 hours 30 minutes.
A Data Science and Machine Learning Project to explore the stock data of a particular stock exchange. The exploration will be focused on observing the repetitive trend in stock markets and relating it to the business cycles. Some questions that can be asked in this project is as follows:
The main resource for this project would be “Python for Finance” Analyze Big Financial Data by O’Reilly Media. Some other resources are as follows:
A portfolio tracker that keep tracks of investments in stocks in a particular market. Keeping in mind the time limitation, it would be better to focus on small markets for this project. The web-based application will provide different portfolios to users to keep track of their investments and to easily look at their best and worst investment.
In this project, the major component of research would be figuring about how to structure the database design for such a system as well as enforcing multiple levels of database transactions logging. A further investigation might be in mirroring the data for backup. Along with this, the project can have a data analysis research segment for any market that might suffice the need of this project.
The research component of this project will also lie in using Model View Controller design pattern to develop such a system. This project essentially has two part, the software design, and the data analysis research. If this project is taken, serious amount of planning has to be done to ensure that all both the component of the project is completed,
The project is about creating a software that can determine an optimal value for a company by looking at their balance sheets records in the past to predict future cash flows. Financial analysis methods such as DCF, DDM and FCE can be implemented in this approach (only one). This system would be automated using machine learning and data analysis.
The main research for this project is coming up with a model that can predict the future cash flows of a company by looking at past trends. Regression will be one of the core Machine Learning Techniques that will be applied in this research. Some resources for this project will be “Python for Finance” Analyze Big Financial Data by O’Reilly Media.
The valuation of the company is doing using what finance people call as the time value of money adjustment. Basically, what this means is that getting $100 today is better than getting in tomorrow or anytime in the future. Thus, all future cash flows that the company generates needs to be discounted at today’s value. In order to do this, we need to figure out the discount rate. There are different approaches we can take for this. For instance, we can use the interest rate provided by the Federal Reserve or we can make our own that can reflect the real financial scenario better. The Capital Asset Pricing Model can be used in this scenario but there are things such are beta and the free interest rate that needs to be estimated. This estimation can be the second part of the research.