Here is an updated machine learning pipeline for my project.
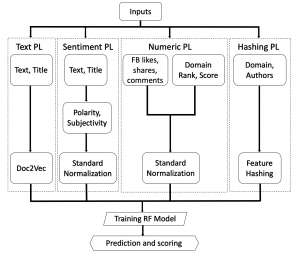
Here is an updated machine learning pipeline for my project.
Submitted the CS second draft on Wednesday and waiting for Xunfei’s Feedback. The demo presentation went well without much questions from the audience. On working on making the poster for the presentation on Dec 5.
I met with my mentors 3 times to discuss the proposal’s feedback and what I can do to improve it. I also reached out to some folks whose previous work could help me. I decided on my end product as a result of that. I also decided to change a few things in my project based on the feedback I got. I will start with a simpler artist style to replicate and if that goes well, I will move to the more complex one. I will also most likely change my sensor from an “air quality” to a CO sensor because that will allow me to see more variation on campus, but I will have to obtain preliminary data before I can make a final call.
This week I did a lot of research into how jitter works and how it communicates with max and msp objects. In the process I found a few more helpful sources to replace some of the less relevant related works that I have. The past couple of days I did some programming on a max patch to familiarize myself with the basics of converting an audio signal into jitter output. I still have a lot to figure out but I was able to create a visual representation of a basic sine wave. I learned about audio sample rates and how to buffer an audio stream into a matrix.
A much slower week than normal, I was swamped with a number of other pre break assignments so I wasn’t able to put much work into reading or revising this week. But I was able to work on revising my introduction and related works section. The focus for the coming week will be to make any final revisions in my paper, and see if there are one or two more papers worth adding in. Found a very good paper on field work that helps establish the background for my work.
During the past week, my focus has been on:
I have been reading up on documentation and research for the Leap Motion controller so that writing the code will be more easily managed in the future. I have also been updating the commented portions of my proposal, and I’m also changing certain sections so that it will make more sense with the context of the scope of my project.
This week I worked more on my proposal after I received constructive feedback from Xunfei. I explored some of the papers further in depth to learn about how to design my project. I am also researching on what tools to buy.
Worked on the demo presentation. Experimented with 2 datasets each taking 4 hours of run time. One observation I found is that changing the labels of the fake news changes the accuracy. It was found that detecting reliable news rather than fake news was statistically better in performance.
This week I made some minor changes to the python script so now the generated file is in the right format. I also made some major changes to my paper and have an updated draft of it. Next week I’ll be able to get together a draft of my poster and then I should be pretty much set to start extending this work in my psychology capstone next semester.
During the last week, I mostly continued working on getting the exhaustive parameter search working for the classifiers. At first, I was having a few errors but in the end, I was able to get it working and get results.
Next, I worked with the Open American National Corpus. I extracted all the text files in one folder. I was able to convert those text files into a csv where each sentence is contained in one row. After that, I run a script which created two csv files: one containing sentences which can potentially contain analogies and one that potentially don’t. I have started labeling them manually.
I have also started preparing for the demo and the second draft of the paper.
My proposal adviser will be Dave. We met last friday to talk about my project idea. one note he gave me was to be clear what parameters I will use to measure my success since my project is almost completely software designing as opposed to research. Over the next few weeks I need to revise my proposal and prototype some basic features of my audiovisual synth.
My adviser for my project for the remainder of the semester is Charlie Peck. We met on Tuesday to discuss my weekly plan. Over the next 4 weeks I will be building the database from the source code, which includes installation of many things. I will also be doing statistical analyses over some datasets that I have yet to find in order to understand the research/ database user side of my project. I have a clear plan of my tasks that lay ahead.
Found an advisor, Ajit, and scheduled a meeting. Otherwise did a second look at a couple papers I had only done a first pass on. Otherwise waiting on feedback on my first draft and spent a little time looking at some potential test data if I find myself in need of other sources.
This week, I met with Craig, and discussed what kind of tools I need to purchase for the project, such as RFID reader and Tags. There are many options however, I need to make sure to purchase a reader that allows backend manipulation. I am scheduling a meeting with Ajit, to discuss this further with him.
This week
This week I re-structured things again. I decided to look into other methods of generating a visualization and decided to separate that process out from NVDA. Under this design, the developer runs NVDA with my plugin installed and that generates a text file. Then the developer navigates to my web-based visualization tool, uploads the file, and then views the generated visualization. I have a working demo of the visualization tool now, but I’m still working on ironing out some of the issues in generating the text files (specifically coming up with a method for splitting the chunks pulled out appropriately).
The front end development part for my project is almost complete. The database setup and connection is completed. The integration of backend machine learning model with flask has worked. The flask prediction model has also been linked with the frontend. There are some issues with websites that are not blog and I am fixing the issue. Next step is to make a retrainable model.
I read more papers where the researchers used a Leap Motion controller to recognize gestures. People use a variety of methods to classify static and dynamic gestures. One of the more frequently used methods takes advantage of a ‘Hidden Markov Model”.
Additionally, I did research on the software available for the Leap Motion controller. By the end of this week I will finalize the framework of my project.
This week I accomplished these tasks:
-found the rest of my 15 sources for my paper
-Met with Xunfei to discuss my design outline
-wrote my project proposal
-Did a second pass of a few of my papers
Worked on my final paper some more, as well as familiarizing myself with my two-node blockchain set-up. I’m still working out how to integrate my other modules into the system, particularly how to pass a function from one server to another through the chain, but I am making progress and anticipate that I will be finished with that tomorrow at the latest. I’ve taken a glance at how my poster will be set-up, but it’s been a tertiary concern for the past few days.
This week I just worked on writing the first draft of my proposal. Found several additional papers to bring myself up to the requirement and fleshed out my idea for what I want to do in a bit more detail. The new papers provided insight on several other computer vision algorithms that I might be able to use, time allowing. Got notes and incorporated those changes into my draft. Built a diagram for my proposal.
This past week, I did my literature review presentation and got caught up with class assignments. I also created a framework for my project and obtained the Arduino air pollution sensor I will use so I can start testing that. I did I third pass on some of my most important sources and I am 85% ready for the proposal.
For the first half of the last week, I was working on the first draft of the paper. Since then, I have been working on getting the exhaustive search working. It has been a struggle. I was trying to implement a pipeline between the classifier and feature extraction tools. However, this seems to be incompatible with data structures I have been using. As a result, I have decided to not use the pipeline, but rather do the exhaustive searches separately for the classifiers.
On the other hand, I have started working with the Open American National Corpus. I should have labeled data in the next two weeks at a maximum.
Finally, I started working on an outline for the poster.
At this point, since I’m still having issues with DrawString, I decided to start looking into alternative options. My adviser recommended that I look into Tkinter again, but after some playing around with it and digging into it, I learned that Tkinter is fundamentally incompatible with NVDA because it does not produce accessible content. wxPython is often used to make NVDA-related GUIs, so I looked into that some but I don’t think it will let me make quite what I want to, so I’ve decided to back up and change plans slightly. I’m going back to the idea of just creating a clean-as-possible transcript of what information NVDA is able to gather when it’s running and developing a script completely outside of NVDA that can take that transcript and create a visual representation from it. I’ve started working on the transcription script and will hopefully have that done by the end of the week so that over the weekend I’ll be able to get a visualization together and ready to present.
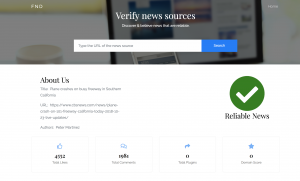
Worked on completing the frontend. I have decided to use my local machine for hosting flask and have made progress on the backend. I still need to fix Database issues but progress this week has been significant. I have just received feedback from Xunfei on my project and will be working on it this week. A look at my front end:
I have decided to go with the Database Akumuli. My reasoning behind this is both because of the index structure it uses along with it’s documentation. This data base clearly states in the README that it uses a combination of an LSM tree and B+ tree. These also happen to be trees that are very well researched and it is easy to become well informed about these trees. Other databases I’ve looked at, for example InfluxDB, while very well documented, uses it’s very own specific tree that was created specifically for this database. Therefore, it is more difficult to learn about it. Akumuli also has a page where it describes it’s index structure, https://akumuli.org/akumuli/2017/04/29/nbplustree/. Furthermore, I have cloned the repository and looked at the index source code. It is in C plus plus, a language I am not as familiar with, but I have used it once or twice. This code was well organized and well commented. For the index the programmers used a boost property tree. While I couldn’t find very much documentation about the property on boost, Akumuli is good at explaining the functionality of the tree. On Thursday I met with Xunfei, who gave me some helpful advice as to where to focus my efforts to be prepared for the proposal. One of these areas includes preliminary testing of the database. At this point I do not have that time at my disposal, seeing as I have just spent a lot of time and effort finding and choosing this database. This requires learning how to use the database and figuring out a testing environment along with finding datasets. Often ingesting datasets into a database can be very time consuming. However, the documentation of Akumuli does include some details and figures about it’s performance. I am in a good spot. I have a solid direction to go in. While there are still some things I need to do, I am only at the first draft stage of the proposal, so there is still time to do things and include them in my final proposal.
I reviewed more papers over the week to get a better sense of what I would need to address in my proposal. I also met with Xunfei and discussed the structure of my project as well as how to work with some of the shortcomings of an RFID system
Worked on the front end component of the project. With the sys admin telling me that they cannot host flask for my project. I started to look for alternatives. Heroku could not be used as it did not provide support for sci-kit the way I needed. Worked with Ajit to edit my first draft paper. Mades some figures of the architectures.
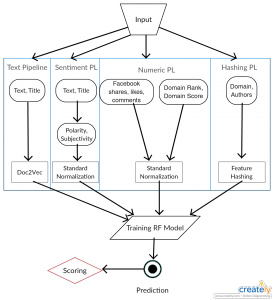
During the past week, I have mostly worked on the first draft of the paper. I did a quick review with Dave on Monday. Then, I reworked on the paper based on the suggestions from Dave.
I have also worked on the coding aspect. I am almost done with implementing the exhausting grid search for hyperparameter tuning for the classifier and the feature extraction tools. The results of the grid search should improve the overall performance of the system.
I am also close to deciding on the corpus that will be used for the experiments. Once I have that, getting the results should be relatively straightforward.
I have successfully set up a blockchain system, and run experiments to familiarize with how it works and the involved processes. My first draft of the paper is mostly complete and will be ready by the deadline tonight. It will not be a complete paper, as the evaluation and conclusion sections will be mostly empty. Advice and consultation from Ajit on the paper is making me restructure some things, and has given me a better reference point for what is required and expected. The paper right now also does not have direct citations to any of the references, as the documentation on how that part works is confusing me. I decided to move that part of the work to the second draft.
I found this function to create a font and played around with it until I had a version that was recognized by the GdipDrawString function. Now I have code that compiles without errors and causes no runtime errors, but the text is still not displaying (or maybe just not displaying how & where I thought it should). So I still need to play around with that problem, but at least I know that I have found a function that produces the right type of thing to pass to GdipDrawString.
I spent quite a bit of time this week drafting my paper and sent a rough draft to my adviser Friday. He responded quickly enough that I was able to make revisions before submitting a draft for grading. Overall I’m happy with the way the paper is shaping up.
I have been taking notes and learning about different tree indexing structures. I currently have 6 pages of notes and understand How R trees work and how X trees uses techniques from both R trees and B trees. I need to go further into detail and learn about R* tree and the X tree along with the LSW tree along with others. I have also started looking into which database to use for my project. I need a database that uses R or R* trees. I am doing this by downloading a database’s source from github and looking into the code using tools such as searches. I am starting by looking into the database InfluxDB. The documentation for this database seems adequate, so it is a good option.
After filtering through many different project ideas, I finally decided to create an aesthetically pleasing data visualization of pollution on Earlham’s campus. I have written a literature review of 15 sources on all of data visualizations, artistic factors that influence them, pollution health effects and awareness of them, as well as multiple projects that use Arduino to collect and display pollution data.
This week I finished writing the literature review and looking in depth into the literature available for my two topics: RFID in library and Sentiment analysis for stock prediction. I believe I will proceed with RFID technology and research more about the resources and different components of the system.
Finished the machine learning pipeline with actual experimentation. Having issues getting Flask setup and have been in touch with the SysAdmins. Halfway through the first draft of the paper. Made new design for the system architecture.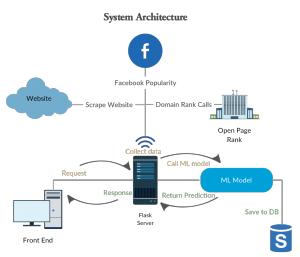
I am still in the process of writing my literary reviews. I have completed one and the second I am currently outlining. I am learning a lot of new information with my new sources. Since I know which of the two topics I will be choosing, I am using the second literary review, which is on a related topic to learn more background on the general area that these two topics are in. The most challenging feat I am facing currently is accessing book sources through the ACM website.
This week I filled out the quiz and started looking into what resources I’ll need for my project, image stitching. At the least I’ll need openCV, but probably imageMagick as well. Starting to think about how I should organize my project, and looking into how easy or hard parallelizing my procedure will be. A few of the papers I read referenced open image libraries they used and I’m thinking about looking into how hard it will be to get access to those.
For the past week, I have been looking at some available corpora found online. I was able to get one for free, namely the Open American National Corpus. It seems like it might be a better fit than the Blogs corpora. In the meantime, the TSVM is working and I have been getting some basic results. I have started working on implementing an exhaustive grid search to find the best parameters for the TSVM. I have also worked on the first draft of the paper, which is due next week. I am hoping to get the results from the grid search before Wednesday, so I can add those to the paper.
Last week I was able to set-up a two node blockchain on the Earlham Cluster, after working through technical issues with the help of Craig. However, I discovered several problems with this structure this week. I couldn’t re-access an already created chain, and getting nodes to connect to it was giving me errors. Unfortunately I had spent the Thursday and Friday of that week working on my draft and module designs, so by the time I encountered the problem I wasn’t able to meet and discuss with Craig until Monday. We talked about it and are working on solving the issue together, but he said he needs to poke around and look at things in the cluster. I tried experimenting with the issue on my end, using the program on my desktop and laptop computer, as well as ssh-ing into the servers, and have had little results to show for it.
This week I dedicated my time towards designing my proposal idea. After my literature review I decided I wanted to continue my audiovisual project. I read through the documentation for the jitter programming language to see what would be feasible to work on. Then I designed a basic architecture for how the synthesizer would convert MIDI note messages into visuals.
This week I’ve focused primarily on drafting my final paper. So far I have a general outline of my paper (abstract –> introduction –> related work –> framework and design –> implementation –> conclusions and future work), and I’ve fully drafted the abstract, introduction, and related work sections. I have a clear idea of what I want to go in each of the other sections, so I should be able to have those sections fully drafted by this time next week.
In terms of the software development component of the project, I almost have a complete (although not especially fancy or sophisticated) visualization tool, but I have spent most of the last week making lots of progress at getting nowhere. All I absolutely need at this point is to figure out how to make a call to the function GdipDrawText, but because gdip is the way python handles GDI+ — a component of .NET made to work for C, C++, and C#, the documentation on it is fuzzy and somewhat sparse. I still have a couple of ideas to try, though, and I’m trying to find people who have experience using it.
I did an experimentation with Sci-kit Learn. The run-time for the program was more than 2 hours. Testing the multiple dataset has been an issue lately.
Progress on the draft of the paper. Related works is almost completed.
This week I am writing my literary review for Indexing Time Series Databases. It is going well. Because this is an area that has been researched for over two decades there is a lot of background information I will be covering in this literary review. I have been focusing on Time Series Database Indexing as a whole rather than a specific database. Since I am feeling confident about going in this direction with my senior projects, my next steps after completing the literary review includes researching specific databases and looking at the road maps for these individual Time Series Databases to know at what development stage each database is at and if it fits the criteria for a database I am looking for.
This week I made good progress in my research. Here are some of the things I have done:
-Met with Forrest Tobey to discuss his past research involving motion tracking virtual instruments as well as visual capabilities of the Max/MSP/Jitter programming language
-Condensed my research papers that I will be using and selected 8 for each literature review
-worked extensively on writing my literature reviews
Making heavy headway into literature review, but still adjusting to overleaf. My final topics are predicting matches in the premier league, and making a software that combines several CV methods in a robust wrapper for easy use. Found eight sources for both topics. Found surprisingly little continuity in methods predicting futbol games.
Last week I was having a problem with a deprecation warning. I looked into that and I thought I fixed it. It seemed to be working fine, but I got the same error at a different point. So I am just ignoring the warning for now. This lead to getting the TSVMs working and getting some results. For the next step, I intend on getting bigger datasets and also looking at the available corpora. I am currently considering the Corpus of Contemporary American English.
Moreover, I reread my last year’s proposal and started to prepare to work on the first draft of the paper.
This week I started playing around with creating the visualization tool piece of my project. In doing that, I learned a lot of the more finicky details of NVDA. It uses an internal installation of Python, which makes sense for users because they don’t need to already have Python installed on their machine to use NVDA. However, this makes installing packages more difficult and requires basically copying and pasting the contents of the package into a directory within the NVDA set up so that its installation of python can use it. To test small changes I want to make, I’ve found the NVDA Python console to be really helpful, but it’s only accessible when NVDA is running which can sometimes slow down the testing process. Overall, I feel like this project has gotten me really into the weeds and I’ve begun identifying specific problems in the way NVDA tries to go about reading this type of content, but I’m not entirely sure of what solutions would best fit with the existing NVDA structure.
Worked on the first draft of the paper. Focusing on the related works and findings currently.
After talking to Ajit about the problems I have been running into with my virtual machines I’ve made the decision to switch to using the Earlham servers for the purpose of running my experiments and collecting data. There’s only one thing that still needs to be worked out and I intend to talk to Ajit about it. Due to poor sleep and bad time management over the last few days I am not as far as long as I should be, and I have not been able to run experiments yet. I will move correct this in the coming weeks and aim to catch back up to the work.
In the past week, I have been working on the related for my three project ideas. I wrote an annotated bibliography for each topic with five different sources. This week got rid of one of the ideas and decided to work on these two:
Prepared a presentation for class on my final two topics, image stitching and predicting premier league games. Started searching for additional topics so I can meet the 8 requirement for the imminent lit review.
I found some quirks and issues with the way NVDA works in different settings. I can now get a transcript with the appropriate details by using object review mode in Firefox, but not by navigating the objects normally or while in Chrome. This gets at the issue of “not knowing what you don’t know” and screen reader users needing to have significant experience and ideas of how to work around poorly designed web layouts. Because at this point I don’t believe there’s an easy way to generalize the automatic transcript making and restructuring process, I think identifying these issues and barriers and creating example demonstrations may be the best end result for my project at this point.
Continuing from last week, I was able to change the implementation of the Scikit-Learn wrapper for TSVM from Python2 to Python3. I am currently getting a new deprecation warning caused by TSVM. It seems like the code for TSVM assumes I am using an older version of Numpy. For this week, I plan to look more into that so I can figure out how to solve the issue.
I have randomly generated a sample from the Blogs corpora and during this week(as well as the next one) I will manually label it. Moreover, I plan on rereading my proposal to determine the parts which are going to be useful in my final paper.
Build a rough machine learning pipeline for testing. Worked with Ajit to update timeline. Started with the first draft of paper.
I am certain at this point that I will be going in a direction where I will be doing research on a database. My first thought was to explore how to store Tree Data Structures in Postgresql. Which led me to then think about indexes in relational databases and finding an open source relational database that is less mature than Postgresql and improving on the way they store their indexes. Firebird is one that popped up onto my radar. I am unfamiliar with it and still need to do background research. Later, it was pointed out to me that relational databases in general are very mature and don’t have as much room for improvement especially when compared to Time Series Databases. My two ideas are to improve the way indexes are used in Time Series Databases and in Relational Databases. My next steps include looking into what open source databases of these types exists and how they use their indexes.
For my project, optimizing an AI agent for Dungeon Crawl Stone Soup, I’ve recently changed the scope of my project somewhat. Instead of trying to improve the AI agent’s chance of winning a game of DCSS, I’m now working to optimize its chance of success at delving past the first floor of the dungeon.
This different scope has several benefits:
Some example results of preliminary trials are as follows:
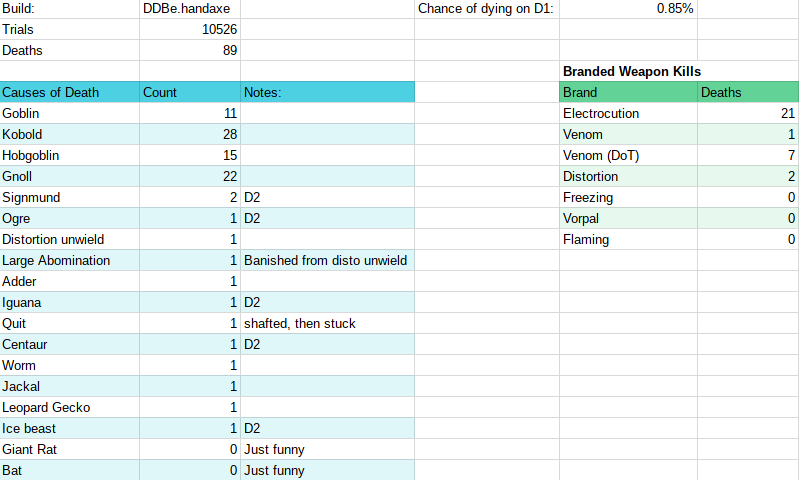
Some bug fixing and tweaking of the algorithm is necessary to avoid accidental “shafting” to lower floors of the dungeon. Additionally, with the high rate of success you see above, it may be necessary to choose a weaker starting character to make room for significant improvements.
Nothing much to report, worked on my annotated bibliography and am narrowing down my interest to just two of my three ideas. Currently leaning towards 2d stitching, potentially expanding it to include some 3d point cloud work as well, but that is only a thought at the moment. The amount of work that has gone into predicting premier league games has taken a lot of interesting directions, but I’m not sure thats what I want to focus on.
I’ve laid down the bare bones for my thesis paper.
With the main project however, I am running into problems with my virtual machines and blockchain code, rather I keep running into problem after problem with them. I plan on talking to my adviser about this and try to figure out something. Biggest issue is that I can reliable to collect and study my data until I get this set up, which is a problem.
This week I’ve gotten minorly stuck. I know that NVDA is able to grab — and speak — certain information about the data visualizations I’ve created(it might say, for example, “graphic New York” when I navigate to a point representing the population of New York). But when I try to grab information about those navigator objects, I end up grabbing objects whose roles are either “unknown” or “section.” These objects also don’t have names, descriptions, basic text, or any useful attribute containing the text information NVDA is able to provide, but isTextEmpty also consistently returns False. At this point I’m not entirely sure where I should be looking to keep digging — I’ve looked into the code for NVDAObjects, TextInfo, speech.py, etc. I’ve also dug into forums and things and found an NVDA development mailing list, so I posted a response to a forum thread asking for clarification about something that might be relevant to this issue and sent a more detailed account of the issue I’m facing and request for guidance to the mailing list. Hopefully I’ll get this sorted out by this time next week.
During the past week, I run into a few problems. I kept getting a PendingDeprecationWarning coming from one the methods used from Scikit Learn. It seems that something has changed or is currently changing on Numpy that affects Scikit learn modules. For now, I was able to ignore the warning. However, I will look more into it to make sure that the warning won’t become a bigger problem in the future.
I was able to find a Scikit wrapper for TSVM, and I tried implementing it. I am currently getting an error coming from the implementation of the TSVM. I suspect it is due to being written for Python 2. I will make the necessary changes so I can use with the current version of Python. For example, it uses xrange() instead of range(). I believe that once I make the necessary changes, the TSVM should work as suspected.
Moreover, the Blogs corpus was too big to be imported as CSV on Google Sheets. So I am currently implementing a simple script which will randomly create a smaller sample, which I will manually label afterward.
Created a smaller dataset using pySpark for training and testing the fake news model.
I’ve been researching Voronoi graph regions and their usage in recommendation system. I’m particularly interested in finding open-source implementation of Voronoi graph regions usage. I’ve also been reading and researching FiveThirtyEight’s gerrymandering maps and how they created their maps of different districting schemes. I am especially interested in the algorithm they used for one of the districting plans. Lastly, I decided on a mapping tool, Leaflet, which is an open-source JavaScript library for interactive maps. I started building the visualization tool using Leaflet and the algorithm taken from FiveThirtyEight.
Read the papers and summarized them.
I am leaning more towards the gesture control system idea, but at the moment it seems like I keep finding more and more challenges to overcome with this project. Typing with gestures may not be feasible, and if I use a camera, there would be lag, making it suck.
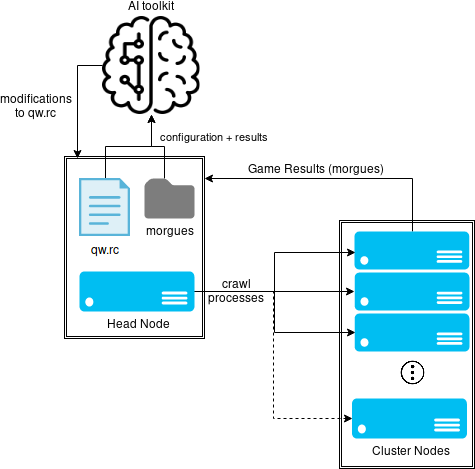
For my senior project, I’m working on optimizing the performance of qw, an AI Agent developed to play (and sometimes win) the game of Dungeon Crawl Stone Soup.
To reduce the search space and make optimization with machine learning faster, easier, and more efficient, I’m limiting the bot to only explore the first floor of the Dungeon. This takes significantly faster to complete compared to running through a full game, and the AI agent will be faced with a much smaller set of monsters, items and dungeon features.
Currently, the plan is to adjust minor variables in the coding of qw to see if it can survive the first floor of the dungeon with a higher rate of success.
Following is my experimental design.
My project ideas have been evolving since starting to research articles. My main fields of research have been in audiovisual synthesis, motion control for virtual instruments, and algorithmic music composition. I have found lots of articles including a good one by alumni Edward Ly that relates very directly. I think his project will be very useful for what I want to work on. He was focusing on conducting an orchestra which is not what I want to do, but I think there should be some overlap and hopefully I could build off of some of his work. I’m still scratching the surface of the research field though and have lots more to find out.
Have found a working software for my Virtual Machines and the blockchain program to run on them, was harder to find than I thought it would be. I have my timeline finished and solidified thanks to my talk with Ajit, so I know what I am doing week by week. I am difficulty actually installing the blockchain onto my Virtual Machines and am not entirely sure why, need to investigate that now and get back on-top of things.
Also have a number of small website files to run on the program for the purposes of my tests. Will see how they work when I get the system fully set up.
I spent the past week reading related papers to my three ideas. It helped me gain a better understanding of the scope and challenges associated with each potential project. I also met with Ajit and discussed the projects. I believe I am leaning more towards working on the RFID technology as it seems a distinct idea and has a fair scope.
I finished making an additional data visualization — a Sankey diagram this week. I looked into NVDA’s built-in logging system and decided I didn’t want to use it to create my logs because it includes — even at the bare minimum settings — too much information that is not relevant for my purposes. Writing to a blank output file makes the most sense as a course of action at this point. I found an existing add on for NVDA written by Takuya Nishimoto (found here) that draws a box around the NVDA “focus object” and “navigator object.” This was helpful because by using it I was able to see that those objects don’t actually completely reflect what the screen reader is picking up and what information it’s focusing on. Often those objects represented an entire window or page, so I need to search for how NVDA is pulling out those more granular details.
Completed corpus creation. Filter the dataset and collecting data from Facebook. Automated process using pyspark. Reduced 40GB file to 9 GB and needed to be cleaned for machine learning processing.
Worked with setting up sci-kit learn and testing environment. Got Craig to give me access to Pollock and Bronte.
Met with my advisor twice, worked on an updated timeline. Worked out a design framework and prepared the presentation slides.
This week, I decided to change my first project (soccer coaching tool) and do something different. I haven’t really thought to utilize my knowledge I’ve gained from classes and I want to do some type of AI or ML project.
Additionally, I found articles that relate to my ideas.
This week I revised my proposal, framework and timeline. These revisions are summed up in my presentation for this week (slides can be found here).
-I met with Kendall to get my ACM membership
-I continued refining my ideas.
-I talked with music professor Forrest Tobey about my ideas and projects that the music department is interested in.
Retrieved the FakeNewsCorupus Dataset from Kaggle. The file size is 40GB and I am thinking about selecting a subset of it to create a smaller dataset. Sci-kit learn cannot load the data on my computer and I need to use a cluster system. Will talk to Craig about getting the issue fixed.
I want to work on a system that manages courses, students and registration similar to Earlham directory but with better management and user-interface. The project will entail a large scale design and breakdown of the problem into smaller subproblems. I will need to learn to work on managing database, and perhaps writing a REST api to create the communication between the system and the database. It will involve easy to understand graphics, and a user friendly interface.
I want to build a system similar to Uber- online tracking, separate accounts for users and online payment. The project will entail several moving pieces. I will need to use different tools in order to store the data, process payments, and have authorization in place. A great portion of the project will be designing and understanding how to make the different pieces work together.
The project will be on predicting the price movements and trends of stocks based on the sentiments expressed on social media or newspapers. This will involve parsing and sentiment analysis of the data and studying its comparison with the price trend of a group of stocks. The project will entail usage of different sources for managing and parsing the input sentiments. A great portion of it will also be on using machine learning to study the correlation between the price and polarity of sentiments.
Python Module for Image Processing
• Is your proposed topic clearly a research activity? Is it consistent with the aims and purposes of research?
Yes. I plan to create something new and make some small breakthrough.
• How is your project different from, say, software development, essay writing, or data analysis?
It is different because, although those are necessary to complete components of my project, they are not the purpose of this project.
• In the context of your project, what are the area, topic, and research question? (How are these concepts distinct from each other?)
The topic and area of my research has to do with image processing. My research question is different from the topic because it is more narrow and specified. My research question is looking at image processing text found over an image/video. For example, reading the overlaying text that appears from a camera in a home video that usually says the date, instance.
• Is the project of appropriate scale, with challenges that are a match to your skills and interests? Is the question narrow enough to give you confidence that the project is achievable?
This project seems of appropriate scale, however I can always extend this project seeing as it is a python module and adding features to it would be conceivable. It seems appropriate scale seeing as it will be from scratch. The challenges of this project that match my skill set is using python, however, image processing itself is not which is an interested I am excited to learn more about. I am confident that this is achievable in a semester.
• Is the project distinct from other active projects in your research group? Is it clear that the anticipated outcomes are interesting enough to justify the work?
I am working individually, however in the 388 group this project is very distinct because I am the only person in the group who has proposed a python module and a project related to image processing.
• Is it clear what skills and contributions you bring to the project? What skills do you need to develop?
The skills I need to develop is knowledge in image processing. I have experience with OpenCV, an image processing library, but I do not know the mechanics of how image processing works.
• What resources are required and how will you obtain them?
I will most likely be needing resources related to AI and image processing, most likely specific chapters in books along with online resources.
• What are the likely obstacles to completion, or the greatest difficulties? Do you know how these will be addressed?
I anticipate this project to be made from scratch, it will take specific deadlines and time management to address the difficulties in completing this project.
Platform for viewing data
• Is your proposed topic clearly a research activity? Is it consistent with the aims and purposes of research?
Yes, I don’t simply plan to create something, but create a minor, realistic breakthrough for a senior undergrad.
• How is your project different from, say, software development, essay writing, or data analysis?
It is different because, while these are a components of this project, they are not the purpose or specific question of my research. They are tools to help me answer my research question. My project is about creating a platform that will store data in a binary tree and to see how storing large amounts of data in a binary tree structure would work.
• In the context of your project, what are the area, topic, and research question? (How are these concepts distinct from each other?)
The context is of my project has to do with storing data, specifically binary tree data. The area is in big data and storing it. The topic has to do with storing and displaying binary tree data and algorithmically how to do that. The broad problem that I am investigating is storing binary data, so my research question is that.
• Is the project of appropriate scale, with challenges that are a match to your skills and interests? Is the question narrow enough to give you confidence that the project is achievable?
The scale is appropriate, if anything it is too large. The challenges in this project that match my skills and interests are dealing with large amounts of data along with creating a visualization for it. Furthermore, there will be a big challenge in figuring out the algorithmic part of this project for ingesting large amounts of data in an appropriate time. Because most of the components of this project have already been done in other tools, figuring out how to do them should be within my reach.
• Is the project distinct from other active projects in your research group? Is it clear that the anticipated outcomes are interesting enough to justify the work?
I am working individually on this research with one advisor, but in comparison to the wider group of 388, there are not projects from last week’s presentations that relate to this topic, so it is safe to say that this project is distinct from other projects in the research group. My anticipated outcome is to have a platform/database for ingesting and displaying binary tree data, which I personally find interesting and I believe justifies an entire semester’s work of work.
• Is it clear what skills and contributions you bring to the project? What skills do you need to develop?
Yes, to the project I bring some knowledge about big data, binary trees, some D3 and languages to build the project. Skills I need to develop are knowledge about ingesting large amounts of data and algorithms for storing data into binary trees along with some other complex algorithms and skills to create such a platform.
• What resources are required and how will you obtain them?
Many resources are required, some having to do with data structures, other with web development and others with moving large amounts of data. I plan to obtain them primarily form the internet and picking apart other such tools.
• What are the likely obstacles to completion, or the greatest difficulties? Do you know how these will be addressed?
There are many components of this project that will be difficult to push through, using time management and helpful pointers from my adviser. Furthermore, since this project entails creating a platform (probably web) from scratch, I will probably need to specify specific deadlines for myself to keep progress steady.
Computer Echolocation
• Is your proposed topic clearly a research activity? Is it consistent with the aims and purposes of research?
Yes, although I will be creating physical, it will be productive and novel.
• How is your project different from, say, software development, essay writing, or data analysis?
This project deals specifically with the intersection of software and hardware. So, it also has a component of hardware in addition to these specific things. Additionally, although hardware, software development, essay writing and data analysis are involved, my project is about exploring the intersection of hardware and software in the are of computer echolocation.
• In the context of your project, what are the area, topic, and research question? (How are these concepts distinct from each other?)
The topic is computer echolocation, however my research question is much more narrow and specific because it deals with the intersection of software and hardware in the area of computer echolocation.
• Is the project of appropriate scale, with challenges that are a match to your skills and interests? Is the question narrow enough to give you confidence that the project is achievable?
My project is both appropriate scale for the semester and is not too ambitious that it would take longer than a semester to create. This project matches my interest in echolocation and matches my skills in software development.
• Is the project distinct from other active projects in your research group? Is it clear that the anticipated outcomes are interesting enough to justify the work?
Although this project is individual and will not be done by an entire group, the overall group of 388 has thus far not mentioned any project having to do with echolocation. The anticipated outcome is to have a robot that is blind but uses microphones to understand it’s surroundings, I personally find this very interesting and am confident that the work is worthwhile given the anticipated outcome.
• Is it clear what skills and contributions you bring to the project? What skills do you need to develop?
Yes, I will be needing to develop knowledge and experience with hardware. The overall contributions involve hardware, software and an understanding of echolocation.
• What resources are required and how will you obtain them?
Most of the resources needed are available online. I will be needing resources that explain the varying hardware that exists, what they do and how to use them.
• What are the likely obstacles to completion, or the greatest difficulties? Do you know how these will be addressed?
The obstacles that are in my way for this project are obtaining hardware. I will address this difficulty with my adviser.
Have set up and arranged weekly meeting times with Ajit as my adviser. We’ll be meeting weekly at 4:00pm on Wednesday.
I have better evaluated what pitfalls and goals I will need to be aware of for my research, and have worked on re-evaluating my timeline. The protocols for managing the data are important, as well as the time overhead of the whole system, and so regular testing and experimentation are going to be important in working things out.
I have also found a few good virtual machines to run my tests on, still selecting which specific one I’ll use..
Deploying Software Defined Networking (SDN) for cloud endpoints
Topic Description: Using the cloud infrastructure, a Software Defined Networking (SDN) can be deployed for cloud endpoints. SDNs are used to connect data centers to public cloud providers to create a hybrid cloud network to manage micro-segmentation and dynamic scaling, implementing SDN with the mobility of cloud endpoints creates a more efficient hybrid cloud network capable of better managing network traffic and organizing the data.
Content Management System (CSM) for Android applications
Topic Description: The ability to flexibly manage mobile contents allows the app builders to create Android apps more efficiently and faster. Building a custom backend for the content management of the app is tedious work so, having a CMS for Android will allow developers to easily update the app. Certainly, the editors would be able to set up the content structure according to the need of the project.
Smart lock security system for Home
Topic Description: The capabilities of smartphones and (Internet of Things) IoT has made it possible for smartphones to take the role of remote control. I want to build a security lock system which can remotely be controlled using the smartphones. The system could also integrate Radio Frequency Identification Device (RFID) tagging which then allows the smartphone to be used as only a security monitoring device.
Idea 1: Soccer Coaching Tool
Did research to find similar softwares for coaching.
Idea 2: Hand/Finger Gesture Sensor for Browser Control and Navigation
Read research papers regarding similar ideas about monitoring hands and fingers. Found devices that provide the sensors and can easily be used with Google Chrome browser.
Idea 3: Thermal Modeling of Building(s) on Earlham’s Campus
Create 3D map of a building or buildings at Earlham and simulate the dynamics of energy loss and generation. Read papers regarding empirical model of temperature variation in buildings.
In this past week, I’ve found and simplified 2 types of data visualizations that I think would be useful for testing purposes: a slopegraph and a bubble graph. I’ve run some preliminary tests with NVDA on them to see how it’s trying to process them and developed basic plans on how to process that information in a way that makes more sense to NVDA.
In the upcoming week, I plan to finish gathering my data visualization test sets and coming up with those early transformation ideas and begin looking into how to get NVDA to transcribe what it’s looking at and output that to a file so it’s easier to track and document its process.
Started the project pipeline for Fake News Detection.