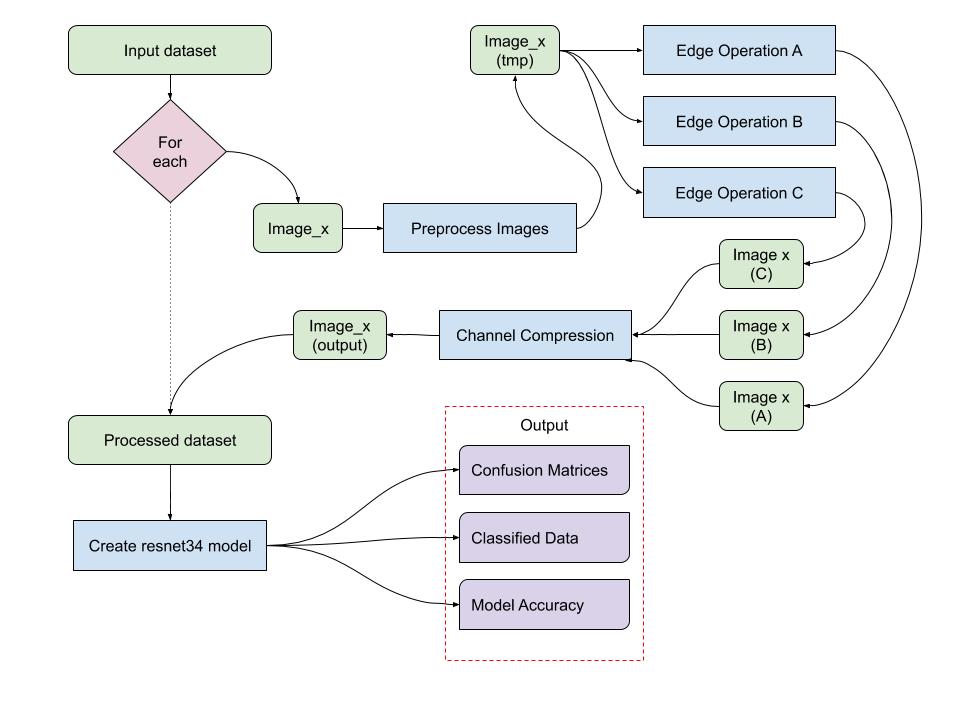
My project is about extracting features from images. Using low-cost collection techniques such as satellite imagery or drone surveys, a database of positive and negative cases can be created. Additional information will be extrapolated from each image in the database using a combination of modern algorithms and combined back into a single imager as different colored layers of a JPEG image. These processed images, the goal of which is to provide as much information as is possible, are used to train a machine learning model. Hypothetically, the additional information provided by the edge detection algorithms will enhance the accuracy and reliability of the machine learning model, reducing the need for expensive surveying equipment.
CS488 – Elevator Pitch
on 2020-03-10
with
No Comments