Annotated Bibliography
on 2020-09-28
with
No Comments
The file can be found here: https://drive.google.com/file/d/1oljfEJN0xPCyrRnoc160miq2ZJ8VWOWX/view?usp=sharing.
Keywords: edge detection, Sobel, Canny, Gaussian smoothing filter, hysteresis, Assyriology, cuneiform tablet
Abstract:
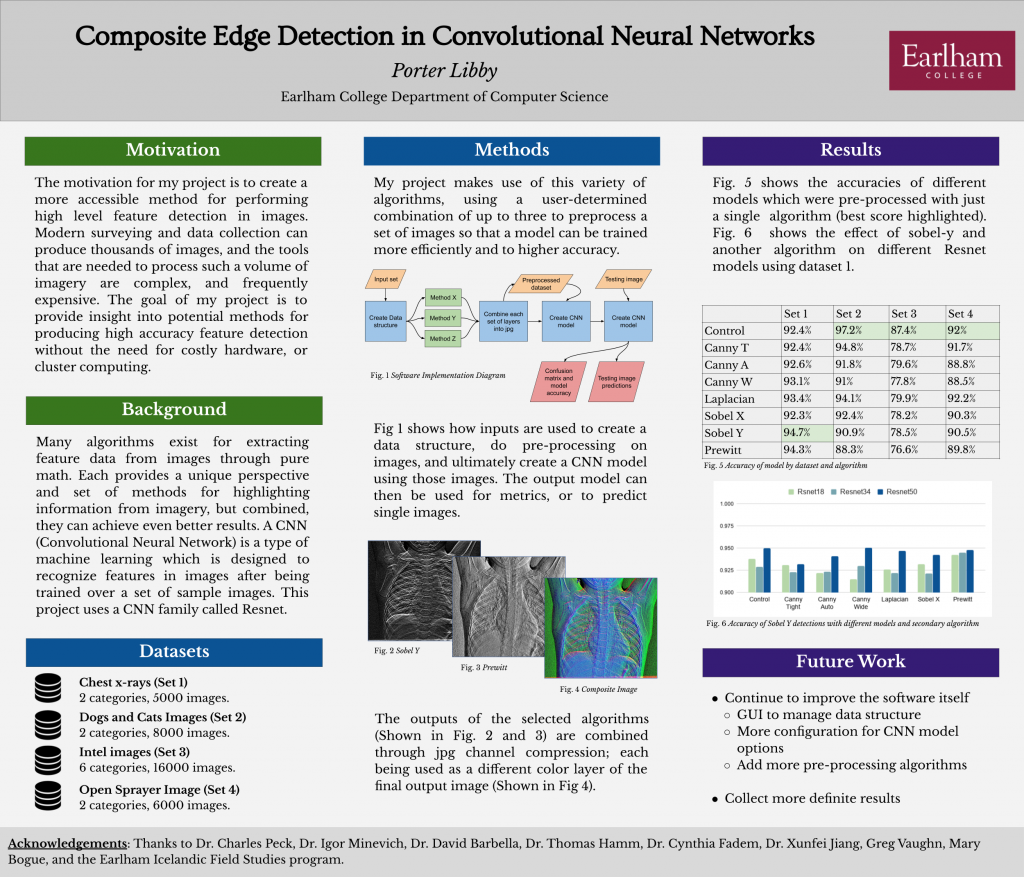
Cuneiform tablets of the ancient Near East document one of the earliest writing systems known. Millions of such cuneiform tablets are archived and are beginning to be digitized by many collections around the world. The six-sided tablet is conventionally digitized by scanning each sides on a flat-bed scanner and stitching the processed scans in the form of a `fatcross’. With the increasing demand for digitization, an effective means of fatcross automation is in demand to tackle the time-consuming process of manual digitization. A challenge in implementing an automated fatcross production is identifying appropriate image segmentation methods. Edge detection is a viable method given its sensitivity to pixel intensity change, such as that of the rapid transition between an illuminated tablet and its dark background. This research aims to identify the most appropriate edge detection method and its implementation parameters to detect the edges from a cuneiform tablet scan.
presentation: https://docs.google.com/presentation/d/1o5tocDFjyPA1eswjaDEi_mrpe2eHbuZGkbrdTn4egXQ/edit?usp=sharing
Cancer staging and metastasis detection using convolutional neural networks and transfer learning
ABSTRACT
Artificial Intelligence (AI) has been used extensively in the field of medicine. More recently, advanced machine learning algorithms have become a big part of oncology as they assist with detection and diagnosis of cancer. Convolutional Neural Networks (CNN) are common in image analysis and they offer great power for detection, diagnosis and staging of cancerous regions in radiology images. Convolutional Neural Networks get more accurate results, and more importantly, need less training data with transfer learning, which is the practice of using pre-trained models and fine-tuning them for specific problems. This paper proposes utilizing transfer learning along with CNNs for staging cancer diagnoses. Randomly initialized CNNs will be compared with CNNs that used transfer learning to determine the extent of improvement that transfer learning can offer with cancer staging.
KEYWORDS
Artificial Intelligence, Cancer Detection, Tumor Detection, Machine Learning, Transfer Learning, Convolutional Neural Networks, Ra- diology, Oncology
1 INTRODUCTION
Artificial Intelligence (AI) has grown into an advanced field that plays a major role in our healthcare. AI in conjunction with Ma- chine Learning (ML), has been aiding radiologists with detecting cancerous regions [2], determining if the cancerous region is benign or malignant [5], to what degree cancer has spread outside of the initial area [6], how well a patient is responding to treatment [8], and more. Among many ML methods assisting radiologists, Con- volutional Neural Networks (CNN) are deep learning algorithms capable of extracting features from images and making classifi- cation using those features [4]. CNN’s are one of the major deep learning methods on image analysis and have become a popular tool in AI-assisted oncology [2]. Over the years many studies have attempted to improve the accuracy of these implementations by comparing different CNN architectures [12], addressing overfitting of the models, using continuous learning [10], transfer learning [12], etc. This proposal aims to improve cancer staging CNNs by applying transfer learning methods and combining the unique im- provements that CNN and transfer learning methods can offer. In this paper, related work for implementation of CNNs and transfer learning for cancer detection is examined and compared to set up an understanding of the algorithms and the tools, the implemen- tation of the CNNs and transfer learning is described, and finally the evaluation method for determining the accuracy of the CNNs is mentioned. Additionally, major risks for the implementation and a proposed timeline of the implementation are included.
2 BACKGROUND
This section focuses on outlining the main components of what is being proposed in this paper. CNN’s and transfer learning methods are used frequently in recent related research and it is important to understand the basics of how they work.
Ali Farahmand afarah18@earlham.edu
Computer Science Department at Earlham College Richmond, Indiana
Figure 1: Simple CNN implementation (derived from Choy et al. [4])
2.1 Convolutional Neural Network
Convolutional Neural Networks are a subset of deep learning meth- ods that extract features from images and further use these features for classification. CNNs are optimized for having images as input and since radiology is image focused, CNNs are one of the most common AI methods used in radiology [14]. A CNN consists of convolution and pooling layers. Figure 1 shows the layer layout of a basic CNN [4]. Convolution layers include filters that, through training, learn to create a feature map which outputs detected fea- tures from the input [14]. This feature map is then fed to a pooling layer, which downsizes the image by picking either the maximum value from the portion of the image that was covered by the con- volution filter or the average value from the portion of the image that was covered by the convolution filter. These two pooling meth- ods are referred to as Max Pooling layer and Average Pooling layer respectively. The purpose of pooling is to reduce computa- tion and/or avoiding overfitting the model. At the end of the last convolution and pooling layers there is fully connected (FC) layer which is used as the classifier after the feature extracting process. Figure 2 visualises a CNN with two convolution layers and two pooling layers. There are multiple architectures for CNNs which use different layer combinations [14] and these architectures are used in detection, segmentation and diagnosis steps of oncology [12]. Among the common architectures there are: AlexNet and VGG architectures. AlexNet is the shallow one of the two with five con- volutional layers. AlexNet can have different numbers of pooling layers, normally on the convolutional layers that are closer to the FC
Ali Farahmand
Figure 2: CNN with two conv and pooling layers (derived from Soffer et al. [14])
layer. Figure 3 shows the AlexNet architecture without the pooling layers included. VGG is a deeper CNN with VGG16 having sixteen layers and VGG19 having nineteen layers. Both VGG16 and VGG19 are very clear about how many convolutional and pooling layers are included. Figure 4 shows a VGG16 architecture along with a breakdown of the layers. As shown in figure 4, pooling layers are present after every two or three convolutional layers in the VGG16 architecture. Both AlexNet and VGG16 have been used in cancer detection systems [14]. AlexNet, as the shallower of the two archi- tectures is more commonly used for detection while VGG is used for diagnosis since it is a deeper network and has smaller kernel sizes. These two architecture will both be used and compared in my work for staging cancer.
Figure 3: AlexNet architecture (derived from Han et al. [7]). AlexNet includes five convlution layers and a combination of pooling layers after any of the convolution layers
different learning environments, as knowledge gained from one learning process can be used in a different learning process with a different but similar goal. CNNs are commonly known to require large amounts of data for reasonable levels of accuracy, and as a re- sult, training CNNs could face problems such as: not having access to enough data, not having access to enough hardware resources for computation, time-consuming training process, etc. Transfer learning can reduce the need for large sets of data while also increas- ing the accuracy of the CNN [11]. When a CNN without transfer learning is being trained, it is initialized with random weights be- tween the nodes of the network, however, in transfer learning, a pre-trained model is used as the initial state of the network and as a result less data is required to train a capable model for the original problem. This pre-trained model is a network that was trained to solve a different but similar problem. For instance, if we have a functional model that can detect horses in images, the model can be used, with little fine-tuning, for transfer learning into a new model that aims to detect dogs. Transfer learning can be very useful in cancer detecting CNNs as it helps improve and expedite the training process. Transfer learning with [1] and without [11] fine tuning has been used in medical imaging systems and has shown improved results.
3 RELATED WORK
Substantial research has been done on the usability of both CNN and transfer learning methods and how they can improve the results of Computer-Aided Detection (CADe) and Computer-Aided Diagnosis (CADx) systems. Shin et al. use three different CNN architectures along with transfer learning for cancer detection and have published very thorough results in their work [12]. This proposal is very similar to the work Shin et al. have done with the key differences of the focus on staging and the use of the VGG architecture. Shi et al. use similar methods to reduce the number of false positives in cancer detection [11]. Bi et al. [2], Hosny et al. [8] and Soffer et al. [14] all have thoroughly explored the current and future applications of CNNs in cancer detection.
4 DESIGN
The process of acquiring images and pre-processing the data is no different than other cancer detection CNNs, as the major difference in this proposal is that it focuses on staging the cancerous tumor us- ing transfer learning with a pre-trained model. The staging system that will be used is the TNM staging system developed by the Na- tional Cancer Institution [3]. Table 1 represents how TNM numbers are associated with each patient. Each of the TNM numbers can also be represented as X instead of a number which would mean the measurement was not possible for that patient. Table 2 shows how different stages are determined, based on the numbers from Table 1.
Figure 5 shows the proposed framework of this project. This framework will be applied to both AlexNet and VGG architectures. Each architecture however, will be started off once randomly ini- tialized and once with a pre-trained model. This means that the proposed framework in figure 5 will be implemented at least four times in this project and at least four accuracy results will be re- ported and compared. As shown in figure 5, the datasets will be
Figure 4: VGG16 architecture (derived from Peltarion web- site [9] based on Simonyan et al. [13]). VGG16 includes a to- tal sixteen layers of convolution and pooling
2.2 Transfer Learning
Transfer learning is inspired by the way humans learn new knowl- edge. The core concept is built around the idea of not isolating
Cancer staging and metastasis detection using convolutional neural networks and transfer learning
Range T 0-4
N 0-3
M 0-1
Meaning
Size of the tumor,
bigger number means bigger tumor Number of nearby lymph nodes affected by cancer spread Whether the cancer has spread to a distant organ
for the ImageNet and Ciphar datasets that can be used for transfer learning. Additionally pre-trained models can be acquired from previous work done in this field such as Shin et al. [12].
4.2 Evaluation
The accuracy of AlexNet and VGG architectures will be assessed both with and without transfer learning. The difference between the accuracy results of the two architectures will be measured before and after using a pre-trained models. This will show how much of a difference transfer learning has made for each CNN architecture. The goal is to find the architecture with the highest accuracy and to find the architecture that had more of an improvement with transfer learning.
5 MAJOR RISKS
Table 1: The meaning of T, N and M numbers in TNM staging system. (derived from: National Cancer Institute’s website [3] )
Stage Stage 0
Stage I, II and III Stage IV
Meaning Abnormal cells present but no cancer present yet. Cancer is present Cancer has spread to
a distant organ
Table 2: Staging of the final TNM number. (derived from: Na- tional Cancer Institute’s website [3] )
pre-processed before being used for feature extraction in the CNN or for the classification.
Figure 5: The overall framework of the project
4.1 Pre-Trained models
The project’s aim is to create the pre-trained models for transfer learning in the final model for cancer staging. This can be achieved with training the AlexNet and VGG architectures with publicly available datasets such as MNIST and Ciphar. However, if this pro- cess turns out to be too time consuming for the proposed timeline, there are different pre-trained models are available such as models
7 ACKNOWLEDGMENTS
I would like to thank David Barbella for helping with this research idea and clarifying the details of the proposed technology.
REFERENCES
node evaluation utilizing convolutional neural networks using MRI dataset. Jour-
nal of Digital Imaging 31, 6 (2018), 851–856.
[7] Xiaobing Han, Yanfei Zhong, Liqin Cao, and Liangpei Zhang. 2017. Pre-trained
alexnet architecture with pyramid pooling and supervision for high spatial res- olution remote sensing image scene classification. Remote Sensing 9, 8 (2017), 848.
[8] AhmedHosny,ChintanParmar,JohnQuackenbush,LawrenceHSchwartz,and Hugo JWL Aerts. 2018. Artificial intelligence in radiology. Nature Reviews Cancer 18, 8 (2018), 500–510. [9] peltarion.com. [n.d.]. Peltarion Website. Retrieved September 22, 2020 from https://peltarion.com/knowledge- center/documentation/modeling- view/build- an- ai- model/snippets- – – your- gateway- to- deep- neural- network- architectures/vgg- snippet [10] Oleg S Pianykh, Georg Langs, Marc Dewey, Dieter R Enzmann, Christian J Herold, Stefan O Schoenberg, and James A Brink. 2020. Continuous learning AI in radiology: implementation principles and early applications. Radiology (2020), 200038. [11] Zhenghao Shi, Huan Hao, Minghua Zhao, Yaning Feng, Lifeng He, Yinghui Wang, and Kenji Suzuki. 2019. A deep CNN based transfer learning method for false positive reduction. Multimedia Tools and Applications 78, 1 (2019), 1017–1033. [12] Hoo-Chang Shin, Holger R Roth, Mingchen Gao, Le Lu, Ziyue Xu, Isabella Nogues, Jianhua Yao, Daniel Mollura, and Ronald M Summers. 2016. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Transactions on Medical Imaging 35, 5 (2016), 1285–1298. [13] Karen Simonyan and Andrew Zisserman. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014). [14] Shelly Soffer, Avi Ben-Cohen, Orit Shimon, Michal Marianne Amitai, Hayit Greenspan, and Eyal Klang. 2019. Convolutional Neural Networks for Radiologic Images: A Radiologist’s Guide. Radiology 290, 3 (2019), 590–606. https://doi.org/ 10.1148/radiol.2018180547Ali Farahmand
Here is my final literature review for the project.
https://drive.google.com/file/d/1qo6oh-i2g2RinazIF8OGN465CjcZnCha/view?usp=sharing
Not really perfect because it’s still some errors in the reference part, however overall is good enough to move forward to the proposal.
Artificial intelligence in radiology cancer detection: a literature review
KEYWORDS
Artificial Intelligence, Cancer Detection, Tumor Detection, Machine Learning, Convolutional Neural Networks, Radiology
1 INTRODUCTION
In a world where Artificial Intelligence (AI) is helping us drive our cars and control our traffic, it is to no surprise that AI is also getting involved in our healthcare. Computers have been used for many decades to help healthcare workers with both imaging patient organs and reading those images [4]. Now with the power of AI, new aspects of computer technology are helping healthcare workers and patients. Research has shown that radiologists have better sensitivity in their cancer detection diagnostics if they’ve had the help of AI-powered software [11], and in some cases the AI was able to outperform the radiologists [12]. The even more complex concept of detecting if the cancer has spread to other locations has also been tackled by AI [6]. Arguably AI can help minimize or eliminate human error in such a sensitive field where a patient’s life depends on how an image is interpreted [12]. Modern AI methods are more than capable of learning and correcting what triggers a radiologists to decide whether there is a cancerous tumor, whether a tumor is benign or whether cancer has spread to other places in the patient’s body. On the other hand, some AI methods are reliant on data from radiologists for their learning, and, as a result, these AI methods cannot completely replace human radiologists. In addition, all AI software needs to be maintained and updated over time to keep the integrity of the AI model, given that an outdated AI model can lose quality over time [10]. This literature review discusses different methods of radiology imaging, along with how they are used and what specific fields of cancer detection AI can be helpful in. Finally it focuses on how Convolutional Neural Networks can be trained to imitate a radiologist in detecting and diagnosing cancer and the spread of cancer.
2 ONCOLOGY AND ARTIFICIAL INTELLIGENCE
Oncology is the branch of medicine that focuses on diagnosing and treating cancer patients. After the proper images are acquired through Computed Tomography (CT), Positron Emission Tomogra- phy (PET), Magnetic Resonance Imaging (MRI) or any other means of radiology imaging, the images need to be preprocessed in a for- mat that the AI can accept as input. Artificial Intelligence has made itself a crucial part of the oncology world by assisting in three clin- ical steps: 1-Detection , 2-Characterization and 3-Monitoring of the given cancerous abnormality[1]. Figure 1 shows the com- plete steps of AI assistance in oncology from image creation until final diagnostic and monitoring of the patient’s response to the
treatment. Specific tumor detection where AI has been applied to be useful with oncology or could potentially be useful are: Breast, Lung, Brain and Central Nervous System (CNS), Gastric, Prostate, Lymph node spreads, etc [1] [6].
2.1 Detection
Abnormality detection is defined as the process in which an AI system searches for a Region of Interest (ROI) in which any abnor- mality can be present [1] [7]. It is in this step where AI is aiming to correct any oversensitivity or undersensitivity in a human radi- ologist, reducing the number of false-negative and false-positive diagnostics. Computers have been helping with this step in oncol- ogy for over two decades in what is described as Computer Aided Detection (CADe) [3]. However, with rapid advancements in AI’s capabilities and popularity, CADe and AI-CADe have become an inseparable part of radiology imaging.
2.2 Characterization
After the detection of the abnormality, the detected abnormality needs to be characterized. Characterization includes separating the tumor or the area in question from the non-cancerous surrounding tissue, classifying the tumor as malignant or benign and finally determining the stage of cancerous tumor based on how much the tumor has spread. These three steps in characterization are com- monly referred to as: Segmentation, Diagnosis and Staging[4] [7].
Ali Farahmand afarah18@earlham.edu
Computer Science Department at Earlham College Richmond, Indiana
2.3
• Segmentation is a process similar to edge detection in im- age processing, as it aims to narrow down the image and only draw focus to the cancerous part of the image.
• Computer Aided Diagnosis (CADx) is the name of systems used in the diagnosis part of characterization [4]. CADx sys- tems use characteristic features such as texture and intensity to determine the malignancy of the tumor [4].
•
There are specific criteria that put each patient into pre- specified stages according to data acquired in the segmen- tation and diagnosis steps. Staging systems use measures such as the size of the tumor, whether the cancer has spread out of the tumor (Metastasizing) and the number of nearby lymph nodes where the cancer has spread to.
Monitoring
The final step where AI assists in oncology is monitoring a patient’s response after a period of time in which the patient underwent one or a series of treatments, such as chemotherapy. The AI is effectively looking for any changes in the tumor, such as growth or shrinking in size, changes in the tumor’s malignancy and the spread. The AI system can do this accurately since it can detect changes that
might not be visible to the radiologists’ eyes. The AI system also eliminates the human error involved in reading smaller changes in images and comparison between images over time [1].
3 DATASETS
Machine Learning is mostly data driven. Thus, AI systems have a constant need for patient radiology records in order to be of any assistance to radiology practices or to have the ability to compete with human radiologists. Fortunately, there is no lack of data or variety of data in this field as statistics show that one in four Amer- icans receive a CT scan and one in ten Americans receive an MRI scan each year [7].
Furthermore, industry famous dataset libraries are publicly avail- able, including but not limited to:
• OpenNeuro [9] (formerly known as OpenfMRI [8]) • Camelyon17 as part of the camelyon challenge [5] • BrainLife [2]
4 ARTIFICIAL INTELLIGENCE METHODS IN RADIOLOGY
Different AI algorithms and methods have been used in oncology both for Computer-Aided Detection (CADe) and for Computer- Aided Diagnosis (CADx). Traditionally, supervised, labeled data and shallow networks have been used. However, with advancements in AI technology, unsupervised, unlabeled and deeper networks have proven to be of more help in detecting patterns for CADe and CADx systems. Deep learning methods might even find patterns that are not easily detectable to the human eye [15].
4.1 Support Vector Machines
Support Vector Machine (SVM) is a supervised machine learning model that is more on the traditional side of models for CAD sys- tems. Due to their simplicity and the fact that they aren’t very computationally expensive, SVMs have been used extensively in tumor detection and have yielded good results [1]. However they’ve been succeeded with more advanced machine learning methods that are capable of detecting features without having labeled data as their input.
4.2 Convolutional Neural Networks
Convolutional Neural Networks are commonly used for unsuper- vised learning and are considered to be deep learning meaning they include many more layers than supervised versions of neural
networks. CNNs are optimized for having images as input and since radiology is image focused, CNNs are one of the most common AI methods used in radiology [14]. In a 2016 study by Shin et al. on different CNN applications, CNNs yielded better average results than traditional approaches on lymph node datasets [13]. CNNs layers consists of convolution and pooling layers. Convolution lay- ers include filters which through training, learn to create a feature map which outputs detected features in the input [14]. Pooling layers are used for downsizing the output of the convolution lay- ers which helps with reducing the computation and overfitting issues [14]. What makes CNNs unique from other multi-layered machine learning models is feature extracting which is powered by the combination of convolution and pooling layers. At the end of the last convolution and pooling layers there is fully connected (FC) layer which is used as the classifier after the feature extracting process [14]. There are multiple architectures for CNNs which use different layer combinations [14] and these architectures are used in detection, segmentation and diagnosis steps of oncology [13].
5 CONCLUSION
This literature review looked into how AI has been used in radiology for detecting, diagnosing and monitoring cancer in patients. We discussed the main steps the AI applies to oncology, from when the image has been acquired by CT, PET or MRI scanner machines, to when the AI-CAD system reads the image to detect an ROI and diagnose the tumor, to how AI can be helpful to monitor the shrink or growth of tumors in a patient that is undergoing a treatment for the tumor. We further discussed how AI systems are capable of detecting metastasis which it categorizes the patient into different stages depending on how much the cancer has spread away from the initial tumor. After discussing the data and glancing over a few important datasets we looked at different AI, both supervised and unsupervised, and discussed how they differ.
REFERENCES
Figure 1: The main AI steps in Oncology
Ali Farahmand
Artificial intelligence in radiology cancer detection: a literature review
[4] Macedo Firmino, Giovani Angelo, Higor Morais, Marcel R Dantas, and Ricardo Valentim. 2016. Computer-aided detection (CADe) and diagnosis (CADx) system for lung cancer with likelihood of malignancy. Biomedical engineering online 15, 1 (2016), 1–17. [11] [12] [13] [14] [15]Alejandro Rodríguez-Ruiz, Elizabeth Krupinski, Jan-Jurre Mordang, Kathy Schilling, Sylvia H Heywang-Köbrunner, Ioannis Sechopoulos, and Ritse M Mann. 2019. Detection of breast cancer with mammography: effect of an artificial in- telligence support system. Radiology 290, 2 (2019), 305–314. https://doi.org/10. 1148/radiol.2018181371 arXiv:https://doi.org/10.1148/radiol.2018181371 Alejandro Rodriguez-Ruiz, Kristina Lång, Albert Gubern-Merida, Mireille Broed- ers, Gisella Gennaro, Paola Clauser, Thomas H Helbich, Margarita Chevalier, Tao Tan, Thomas Mertelmeier, et al. 2019. Stand-alone artificial intelligence for breast cancer detection in mammography: comparison with 101 radiologists. JNCI: Journal of the National Cancer Institute 111, 9 (2019), 916–922.
H. Shin, H. R. Roth, M. Gao, L. Lu, Z. Xu, I. Nogues, J. Yao, D. Mollura, and R. M. Summers. 2016. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Transactions on Medical Imaging 35, 5 (2016), 1285–1298.
Shelly Soffer, Avi Ben-Cohen, Orit Shimon, Michal Marianne Amitai, Hayit Greenspan, and Eyal Klang. 2019. Convolutional Neural Networks for Radiologic Images: A Radiologist’s Guide. Radiology 290, 3 (2019), 590–606. https://doi.org/ 10.1148/radiol.2018180547
An Tang, Roger Tam, Alexandre Cadrin-Chênevert, Will Guest, Jaron Chong, Joseph Barfett, Leonid Chepelev, Robyn Cairns, J Ross Mitchell, Mark D Cicero, et al. 2018. Canadian Association of Radiologists white paper on artificial intel- ligence in radiology. Canadian Association of Radiologists Journal 69, 2 (2018), 120–135.
[5] grand challenge.org. [n.d.]. Camelyon17 grand challenge. 17, 2020 from https://camelyon17.grand- challenge.orgRetrieved September
Retrieved September 17,
[10] Oleg S Pianykh, Georg Langs, Marc Dewey, Dieter R Enzmann, Christian J Herold, Stefan O Schoenberg, and James A Brink. 2020. Continuous learning AI in radiology: implementation principles and early applications. Radiology (2020), 200038.Pitch #1
Style transfer and Image manipulation
Given any photo this project should be able to take any art movement such as Picasso’s Cubism and apply the style of the art movement to the photo. The neural network first needs to detect all the subjects and separate them from the background and also learn about the color schemes of the photo. Then the art movement datasets needs to be analyzed to find patterns in the style. The style will then need to be applied to the initial photo. The final rendering of the photo could get a little computationally expensive, if that is the case there will be need for GPU hardware. Imaging libraries such as pillow and scikit would be needed. It might be a little hard to find proper datasets since there are limited datasets available for each art movement. Contrarily I could rid myself of the need for readily-made datasets by training the network to detect style patterns by feeding it unlabeled painting scans.
Source #1:
Chen, D. Yuan, L. Liao, J. Yu, N. Hua, G. 2017. StyleBank: An Explicit Representation for Neural Image Style Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1897-1906.
This paper uses a network that successfully differentiates between content and style of each image. I’ve had doubts about this project being two separate tasks: 1- understanding what subjects are in the photo (content). 2- understanding the color scheme and style used for these subjects (style). This paper’s approach manages to tackle both of those. The conclusion of this paper actually mentions what wasn’t explored but it could be an interesting new thing to investigate which could be a good starting point for my work. Many successful and reputable other works are used for comparison in this paper (including source #2 below) and overall this paper is a gold mine of datasets (including the mentioned Microsoft COCO dataset). It might be hard to find a way to evaluate my final results for this pitch, however this paper does an excellent job of doing this evaluation simply by comparing the final image with final images in previous work.
Source #2:
Gatys, L.A. Ecker, A.S. Bethge M. 2016. Image Style Transfer Using Convolutional Neural Networks. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2414-2423.
Gatys et al. start with an amazing summary and comparison of previous work in the introduction. They propose a new algorithm which is aimed to overcome the challenges of separating content and style of an image. This paper is one of the most famous and popular approaches to style transfer and it has been cited many times. The filters used in this paper to detect content can be very useful in my project since the approach focuses on higher layers in the convolutional network for content detection which are not the exact pixel recreations of the original picture. Eliminating the exact pixel representation of the image could also result in reducing the need for computationally expensive code.
Source #3:
Arpa, S. Bulbul, A. Çapin, T.K. Özgüç, B. 2012. Perceptual 3D rendering based on principles of analytical cubism.Computers & Graphics, 6. 991-1004.
This paper is gives us a different perspective than the other resources since it analyzes what exactly constructs the cubism model by analyzing cubism in a 3d rendered environment. The approach uses three different sets of rules and patterns to create cubist results which are 1-Faceting, 2-Ambiguity and 3- Discontinuity. If I can successfully apply these three patterns in a 2d environment then I have decreased the number of filters that need to be applied to each photo down to only three filters. Faceting seems to be the most important part of cubism as different facet sizes can actually create both ambiguity and discontinuity. Main problem with this paper is that there is not much other work to compare this to and it seems the only way to evaluate the final work is just by observing and out own judgement even though the paper includes some art critics input.
Source #4:
Lian, G. Zhang, K. 2020. Transformation of portraits to Picasso’s cubism style. The Visual Computer, 36. 799–807.
This paper start off by mentioning that the Gatys et al. (source #2) approach, however successful, is slow and memory consuming and it claims to improve the method to be more efficient. The problem with this paper is that even though the algorithm is a lot more efficient and quicker than Gatys et al. it only applies the same style and it only applies that style to portraits. Gatys, however memory consuming does a great job to work with any image with any content inside. So my goal would be to expand on this papers efficient approach to be able to work with a wider range of image content and styles while still being less computationally expensive than the famous Gatys et al. approach.
Pitch #2
Image manipulation detection
Neural network would be trained to detect image manipulation in a given photo. There are many ways to achieve this including but not limited to image noise analysis. Different algorithms can be compared to see which can do the best detection manipulation or which one was better automated with the training process.
Python libraries such as Keras and sklearn will be used for the Neural Network and the deep learning. Many previous research papers and datasets are available for this project or similar ones.
Source #1:
Zhou, P. Han, X. Morariu, V.I. Davis L.S. 2018. Learning Rich Features for Image Manipulation Detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 1053-1061.
Strong paper with strong list of citations. Separate convolutions for RGB and noise level seem to work together very well. This paper talks about how they had issues with finding good enough datasets and how they overcame this problem by creating a pre trained model from the Microsoft COCO dataset. The noise stream approach is especially interesting. The filters used in the convulsions are given which can be used directly or slightly modified for comparison and perhaps enhancement of the method. The results section of this unlike the previous pitch is very thorough and shows how the RGB and noise level approach compliment each other. My goal would be to enhance the noise approach model until it can identify manipulation independent from the RGB stream. The noise level detection seems to be almost complete on its own and stripping the RGB stream and the comparison between the two would decrease the computation resources required for the method extensively.
Source #2:
Bayram, S. Avcibas, I. Sankur, B. Memon, N. 2006. Image manipulation detection. J. Electronic Imaging, 15.
This paper is a lot more technical than Zhou et al (source #1). Source #1 above seems to be more focused on if more content was added or if content was removed from an image while this paper also focuses on if the original photo is still with the same content but slightly manipulated. Very strong results along with thorough graphs are included for comparison between methods. Five different forensic approaches are compared in this paper which all five need to be separately researched to be able to apply the actual method (or only the best performing one in the results section of the paper). My goal would be to find what makes each approach do better than others and take only the best parts of each approach and somehow mix them together.
Source #3:
Bayar, B. Stamm M.C 2016. A Deep Learning Approach to Universal Image Manipulation Detection Using a New Convolutional Layer. In Proceedings of the 4th ACM Workshop on Information Hiding and Multimedia Security (IH&MMSec ’16). Association for Computing Machinery, New York, NY, USA, 5–10.
This paper does a great analysis of what different convolutional neural network methods are which ones could be used for maximum optimization in image manipulation and forgery detection. The datasets used are a massive collection of images with more than 80000 images (all publicly available on their github page) which would be very helpful for my project if I were to choose this pitch. The two sets of results for binary classification and multi-class classification approach both get very impressive results with the binary classification getting a minimum of 99.31% accuracy. This paper’s unique approach is to remove the need for detecting the content of the image and directly attempting to detect manipulation with no pre-processing.
Pitch #3
Radiology disease detection
Trained neural networks for detecting radiology abnormalities and diseases have reached a level that can easily compete with a human radiologists. For this project I will be using neural network libraries to detect different abnormalities. There are very different field that this can apply to such as: Brain tumor detection, breast cancer detection, endoscopic, colonoscopy, CT/MRI, oncology, etc. There are countless datasets and different approaches available for a project such as this one which leaves gives me the opportunity to compare and contrast different variations of them. This is a very rich field with a lot of previous work and published papers to explore.
Source #1:
Liu, Y. Kohlberger, T. Norouzi, M. Dahl, G.E. Smith, J.L. Mohtashamian, A. Olson, N. Peng, L.H. Hipp, J.D. Stumpe, M.C. 2019. Artificial Intelligence–Based Breast Cancer Nodal Metastasis Detection: Insights Into the Black Box for Pathologists. Arch Pathol Lab, 143 (7). 859–868.
A lot of medical terms used in this paper which helped me understand the field better by looking them up. Examples are: LYNA, Sentinel Lymph node, metastatic, etc. This paper is different from the other sources since the sources below (especially the brain tumor one: source #3) are all focused finding tumor in a specific place, while this paper is focused on finding out if cancer has spread to other places such as lymph nodes (that’s what metastatic means). Detecting if cancer has spread seems to me a better real life application of deep learning radiology and potentially might affect the final version of this pitch. More than one good datasets are mentioned in this paper which can be used in this pitch. This includes the Camelyon16 dataset from 399 patients. Additionally there is a newer Camelyon17 dataset available. This paper comes incredibly close to the Camelyon16 winner which could also be a good source to check out. Strong list of references which includes papers about using deep networks to detect skin cancer. Some of the authors of this paper have other papers that contribute to the field even further. (interesting fact, somehow a lot of the authors of this paper and the ones in the references list are from my country)
Source #2:
Manogaran, G. Shakeel, P. M. Hassanein, A. S. Kumar, P.M. Babu G.C. 2019. Machine Learning Approach-Based Gamma Distribution for Brain Tumor Detection and Data Sample Imbalance Analysis. IEEE Access, 7. 12-19.
This paper uses a datasets from openfmri which has turned into https://openneuro.org. Both the old and the new dataset are very large, very useful datasets that can be used for this pitch. This paper also includes two different algorithms that help find the location of the tumor in each radiology image. Important to remember that ROI in this paper doesn’t mean Return On Investment, it actually means Region of Interest which is the region that the Neural Network has detected the tumor to be located. Orthogonal gamma distribution model seems to play a big role in the ROI detection in this paper (it is in the title) which makes this approach unique as it gives the algorithm the capability to self-identify the ROI. This automation is the winning achievement of this paper.
Source #3:
Logeswari, T. Karnan, M. 2010. An improved implementation of brain tumor detection using segmentation based on soft computing. Journal of Cancer Research and Experimental Oncology, 2 (1). 6-14.
This paper proposes a hierarchical self-organizing map (HSOM) for MRI segmentation and it claims that this approach will have improvements to a traditional Self-Organizing Map (SOM) method. The winning neuron method is a simple yet elegant method that I can utilize in my application of MRI reading and detection. This paper is relatively old compared to the other sources and doesn’t include any significant dataset, however, the simple winning neuron algorithm is a good starting point that can be expanded on with better segmentation methods, better model training, etc.
Source #4:
Bi, W.L. Hosny, A. Schabath, M.B. Giger, M.L. Birkbak, N.J. Mehrtash, A. Allison, T. Arnaout, O. Abbosh, C. Dunn, I.F. Mak, R.H. Tamimi, R.M. Tempany, C.M. Swanton, C. Hoffmann, U. Schwartz, L.H. Gillies, R.J. Huang, R.Y. Aerts, H.J.W.L. 2019. Artificial intelligence in cancer imaging: Clinical challenges and applications. CA A Cancer J Clin, 69. 127-157.
This paper is a little different from the other sources, as it discusses Artificial Intelligence used in Cancer detection as a general concepts while also getting in depth in various fields of cancer detection such as lung cancer detection, breast mammography, prostate and brain cancer detection. The paper can be very helpful since it describes different methods of cancer detection in a machine learning environment and talks about different kinds of tumors and abnormalities at length. The authors even do a thorough comparison between previous work for each field which includes what tumor was studied, how many patients were in the dataset, what algorithm was used, how accurate the detection was and more. This paper opens the possibility for me to choose between any of the different fields to choose from for my final proposal.
Source #5:
Watanabe, A.T. Lim, V. Vu, H.X. et al. 2019. Improved Cancer Detection Using Artificial Intelligence: a Retrospective Evaluation of Missed Cancers on Mammography. In Journal of Digital Imaging 32. 625–637.
This paper focuses generally on human error in cancer detection and how Artificial Intelligence can minimize human error. Unfortunately, Artificial Intelligence cancer detection is not as mainstream as it should be even though it has been proven to assist and outperform radiologists. That is what this paper is trying to address. The paper claims that computer-aided detection (CAD) before deep learning was not being very helpful and tries to prove that since the addition of AI to CAD (AI-CAD), false negative and false positive detections have been diminished. The paper then studies the sensitivity, number of false positives, etc. in a group of radiologist with various backgrounds and experience levels to prove that the AI-CAD system in question is helpful. Perhaps my final results in my work could be compared against a radiologist’s detection for a small section in the results section of the paper using the same methods this paper used for comparison.
Source #6:
Rodriguez-Ruiz, A. Lång, K. Gubern-Merida, A. Broeders, M. Gennaro, G. Clauser, P. Helbich, T.H. Chevalier, M. Tan, T. Mertelmeier, T. Wallis, M.G. Andersson, I. Zackrisson, S. Mann, R.M. Sechopoulos, I. 2019. Stand-Alone Artificial Intelligence for Breast Cancer Detection in Mammography: Comparison With 101 Radiologists, In JNCI: Journal of the National Cancer Institute, Volume 111, Issue 9. 916–922.
Similarly to Watanabe et al. (source #5 above) this paper attempts to compare AI powered cancer detection to radiologists diagnosis without any computer assisted results. They use results from nine different studies with a total of 101 radiologist diagnostics and compare their collective results to their AI powered detection system. This paper does a more thorough comparison with a larger set of datasets and has more promising results than Watanabe et al. (source #5). Their supplementary tables show in depth results of each individual dataset against the AI system which shows slightly better results than the average of the radiologists in most cases.
Source #7:
Pianykh, O.S. Langs, G. Dewey, M. Enzmann, D.R. Herold, C.J. Schoenberg, S.O. Brink, J.A. 2020. Continuous Learning AI in Radiology: Implementation Principles and Early Applications.
The unique problem under focus in this paper is how even the best AI algorithms in radiology reading and detection can become outdated given that data and the environment is always evolving in the field. The paper proves that models trained to work in the radiology field lose their quality over even short periods of time, such as a few months, and it proposes a continuous learning method to solve this problem. Continuous learning and its advantages are discussed and explained at length in the paper. According to the data in the paper, the AI model was able to keep its quality if feedback from the radiologists and patients was given and the model was retrained once a week using this feedback data from the two groups. The problem with this approach is that inclusion of radiologists and the less knowledgeable patients into the model training process increases the risk of mistraining due to human error and also input from someone that doesn’t have enough experience and/or knowledge about the field. In my work I could explore ways of ridding this method of human input and potentially make different AI models work with each other to provide feedback for continuous learning.
Source #8:
Tang, A. Tam, R. Cadrin-Chênevert, A. Guest, W. Chong, J. Barfett, J. Chepelev, L. Cairns, R. Mitchell, J. R. Cicero, M. D. Poudrette, M. G. Jaremko, J. L. Reinhold, C. Gallix, B. Gray, B. Geis, R. 2018. Canadian Association of Radiologists White Paper on Artificial Intelligence in Radiology. In Canadian Association of Radiologists Journal, 69(2). 120–135.
This paper doesn’t actually build any Artificial Intelligence program and therefore there aren’t any datasets or results that can be helpful. However, the paper includes a vast insight into Artificial Intelligence and its role in modern radiology. Many helpful topics are included such as different Artificial Intelligence learning methods, their different applications in the radiology world, different imaging techniques, the role of radiologists in AI field and even the terminology needed to understand and communicate to others about the concept. Even though there is not implementation of software in this paper and no datasets are used as a result, datasets are discussed as length. What a dataset requires to be useful and how large should a dataset be are included with actual examples of these datasets (such as the ChestX-ray8 with more than 100 thousand x-ray images.
Source #9:
Ha, R. Chang, P. Karcich, J. et al. 2018. Axillary Lymph Node Evaluation Utilizing Convolutional Neural Networks Using MRI Dataset. In Journal of Digital Imaging 31. 851–856.
Axillary lymph nodes are a set of lymph nodes in the armpit area and due to their proximity to the breasts they are the first set of lymph nodes that breast cancer spreads to. Detecting even smallest amount of microscopic cancer cells in the axillary lymph nodes is critical to determining the stage of breast cancer and the proper treatment methods. For that reason this paper focuses on using MRI scans to detect the spread of cancer to these nodes as opposed to the normal tumor detection in breast mammographs in sources #1, #5 and #6. The other major difference between this source and others is the pre-processing of the 3d datasets. Interestingly this paper also leaves pooling out and downsizes the data with a different method. I believe I can use and even optimize many of the methods in this paper to get better results in my work. Metastasis detection is a very interesting field which doesn’t have the same amount of AI work done compared to tumor detection and for that reason I believe there is more room for improvement in the field.
Source #10:
Rodríguez-Ruiz, A. Krupinski, E. Mordang, J.J. Schilling, K. Heywang-Köbrunner, S.H. Sechopoulos, I. Mann, R.M. 2018. Detection of Breast Cancer with Mammography: Effect of an Artificial Intelligence Support System.
This paper is likely what encouraged the creating of Rodríguez-Ruiz et al. (source #6). The difference between the two papers is small yet substantial. In this paper Rodríguez-Ruiz et al. compare how radiologists perform with and without the help AI powered systems as opposed to their newer paper (source #6) which takes the AI systems out and makes the radiologists compete against what was used to help them in this paper. Interestingly enough the results of the paper in which radiologists compete against AI are better compared to when AI is used as an aid to the radiologists. The data in this paper is not as extensive as the newer paper (source #6), however, as long as good data is available (such as in source #6), there is a lot for me to explore in the world of comparisons between different methods of AI and different kinds of radiologists (perhaps in a different field than mammography).
Source #11:
Hirasawa, T., Aoyama, K., Tanimoto, T. et al. 2018. Application of artificial intelligence using a convolutional neural network for detecting gastric cancer in endoscopic images. In Gastric Cancer 21. 653–660.
With most of my sources focused on either Breast and Brain tumor detection I thought it would be helpful to expand the range of possibilities by including more applications of AI in radiology fields. This paper uses similar CNN approaches for endoscopy imaging for gastric cancer detection. Going into fields such as gastric cancer detection where the amount of previous work is not as much as breast and brain tumor detection has advantages and disadvantages. Main advantage is that I am more likely to be able to get better improved results than the most recent work and the main disadvantage is the less amount of datasets available in such a field. This paper however uses good datasets acquired from different hospitals and clinics. Perhaps acquiring data from local clinics and hospitals is something I can look into for my work as well.
After finish the annotated, I narrowed down to 1 idea to write the literature review. All 3 of my ideas related to machine learning, however I would choose the idea that I feel excited the most and feel motivate the most which is Idea 1: Mask Face Detection.
Covid-19 is a really hot topic right now, and I really hope that I can contribute a little bit in the community health.
Now I am moving on to the literature review.
Idea 1: Masked Face Detection:
Introduction: Due to the fact that the virus that causes COVID-19 is spread mainly from person to person through respiratory droplets produced when an infected person coughs, sneezes, or talks, it is important that people should wear masks in public places. However, it would be difficult to keep track of a large number of people at the same time. Hence, my idea is to utilize machine learning to detect if a person is wearing a mask or not. Hopefully, this idea can help reduce the spread of the coronavirus.
Citation 1: Detecting Masked Faces in the Wild with LLE-CNNs
The paper introduces a new dataset for masked face detection as well as a model named LLE-CNNs that the authors claimed to have outperformed 6 state-of-the-arts by at least 15.6%. Fortunately, the dataset is publicly available and is exactly what we are looking for for the problem that we are proposing.
Citation 2: FDDB: A Benchmark for Face Detection in Unconstrained Settings
The link Github contains the MAFA dataset that has the images of people divided into three main factors: face with mask, face without mask, face without mask but getting blocked by phone, hand, people. This dataset exactly fits with the goal of the research.
Citation 3: Object-oriented Image Classification of Individual Trees Using Erdas Imagine Objective: Case Study of Wanjohi Area, Lake Naivasha Basin, Kenya
Although this research target is focusing all about object classification, however it brings up a good background when it comes to image classification.
Citation 4: Joint Face Detection and Alignment using Multi-task Cascaded Convolution Network
This paper provides a model to help detect people’s face and alignment in difficult environments due to various poses, illuminations and occlusions. Throughout this paper we can have a bigger picture about what face detection is, what is the difference and how this method can help in detecting a person’s face
Citation 5: RefintFace: Refinement Neural Network for High Performance Face Detection
The paper provides a model that can detect faces with extreme poses or possess small sizes. This can be helpful to us since the first step of our problem is to detect faces.
Citation 6: Very Deep Convolutional Neural Networks for Large-Scale Image Recognition
The architecture can be used for our problem as well if we train the model on our own training set and training loss.
Idea 2: Speaker Recognition:
Introduction: BookTubeSpeech is a newly released dataset for speech analysis problems. The dataset contains 8,450 YouTube videos (7.74 min per video on average) that each contains a single unique speaker. Not much work on speaker recognition has been done using this dataset. My work is to provide one of the first baselines on this dataset for speaker recognition / speaker verification.
Citation 1: Deep Speaker: an End-to-End Neural Speaker Embedding System
The paper presents a novel end-to-end speaker embedding model named Deep Speaker. Although the paper is not new, it is definitely something we can use for our problem since the authors do publish their codes, which are readable and runnable.
Citation 2: Voxceleb: Large-scale speaker verification in the wild
This research contains a various dataset with a CNN architecture and CNN based facial recognition method used to identify the speaker voice. These methods would be beneficial for the research since BookTubeSpeech also a type of data set from Youtube, which also contains imagination and voice. Also this method might help in solving different cases such as the voices of the speaker getting affected by some others sound such as sound, other human voices.
Citation 3: X-Vectors: Robust DNN Embeddings For Speaker Recognition
The authors of the paper propose a DNN-based speaker embedding model that is currently state-of-the-art for speaker recognition and speaker verification problems. Hence, it goes without saying that we should use this as one of our models to report results on the BookTubeSpeech dataset.
Citation 4: Generalized End-to-End Loss for Speaker Verification
The paper proposes a new loss function that the authors claim to yield competitive performance but fast to train.
Citation 5: Toward Better Speaker Embeddings: Automated Collection of Speech Samples From Unknown Distinct Speakers
The paper proposes a pipeline for large-scale data collection to train speaker embedding models. They also contributed a dataset named BookTubeSpeech that we are mainly going to use for our experiments.
Citation 6: Probabilistic Linear Discriminant Analysis
The author proposes Probabilistic LDA, a generative probability model with which we can both extract the features and combine them for recognition. We can use PLDA on top of our models’ outputs to gain an increase in performance.
Idea 3: Sport players prediction result using machine learning:
Introduction: “How many yards will an NFL player gain after receiving a handoff?” I will be attending a competition on Kaggle. During the process, Kaggle would provide a dataset of players from different teams, the team, plays, players’ stats including position and speed to analyze and generalize a model of how far an NFL player can run after receiving the ball.
Citation 1: A machine learning framework for sport result prediction
The paper provides not only a critical survey of the literature on Machine Learning for sport result prediction but also a framework that we can apply to our problem. While the survey can help us get a sense of which method works best, the framework will let us know what to do next after we have picked our model.
Citation 2: Scikit-learn: Machine Learning in Python
Citation 3: Using machine learning to predict sport scores — a Rugby World Cup example
Although this is not an official research, however it contains the step-by-step to do research related to this topic detailly. It also listed all of the tools that are necessary and fit with the topic of the research.
Citation 4: Long Short-Term Memory
For our problem, we will definitely try different deep learning architectures. LSTM is one of the architectures that we are going to try.
Citation 5: XGBoost: A Scalable Tree Boosting System
Not every problem requires deep learning models, we should try traditional Machine Learning techniques as well. Hence, we should try XGBoost.
Citation 6: Principal component analysis
The PCA features can also be used as new features that we can feed into our machine learning models.
Idea 1: Masked Face Detection:
Citation 1: Detecting Masked Faces in the Wild with LLE-CNNs
The paper introduces a new dataset for masked face detection as well as a model named LLE-CNNs that the authors claimed to have outperformed 6 state-of-the-arts by at least 15.6%. Fortunately, the dataset is publicly available and is exactly what we are looking for for the problem that we are proposing.
Idea 2: Speaker Recognition:
Citation 1: Deep Speaker: an End-to-End Neural Speaker Embedding System
The paper presents a novel end-to-end speaker embedding model named Deep Speaker. Although the paper is not new, it is definitely something we can use for our problem since the authors do publish their codes, which are readable and runnable.
Citation 2: FDDB: A Benchmark for Face Detection in Unconstrained Settings
The link Github contains the MAFA dataset that has the images of people divided into three main factors: face with mask, face without mask, face without mask but getting blocked by phone, hand, people. This dataset exactly fits with the goal of the research.
Idea 3: Sport players prediction result using machine learning:
Citation 1: A machine learning framework for sport result prediction
The paper provides not only a critical survey of the literature on Machine Learning for sport result prediction but also a framework that we can apply to our problem. While the survey can help us get a sense of which method works best, the framework will let us know what to do next after we have picked our model.
We need to uploaded and finish 18 annotated, however this is my way to write annotated bibliography. I am still trying to finish 18 annotated as soon as I can.
Artificial Neural Networks in Image Processing for Early Detection of Breast Cancer
MEHDY, M. M., P. Y. NG, E. F. SHAIR, N. I. SALEH, CHANDIMA GOMES.2017. Artificial neural networks in image processing for early detection of breast cancer. Computational and mathematical methods in medicine.
The paper examines four different approaches to breast cancer in medicine ( MRI, IR< Mammography and ultrasound). For the classification, the paper looks at three different techniques: Support Vector Machine, Method based on rule ( decision tree and rough sets), Artificial Neural Network. The paper also divided the types of data that need to be classified: calcification and non calcification, benign and malignant, dense and normal breast, tumorous and non tumorous. The paper addressed different types of Neural networks that exist and have been used in related works in Breast Cancer Detection : Feed-forward backpropagation, Convolution Neural Networks.
NOTES:
Breast Cancer detection using deep convolutional neural networks and support vector machines
RAGAB, DINA A., MAHA SHARKAS, STEPHEN MARSHALL, JINCHANG REN.2019.Breast cancer detection using deep convolutional neural networks and support vector machines. PeerJ ,7(e6201).
This paper, for breast cancer detection, is using CAD (Computer Aided Detection) classifier to differentiate benign and malignant mass tumors in breast mammography. It touches upon two techniques used in CAD – manual determination of the region of interest and technique of threshold based on the region. For the feature extract, the paper is using DCNN (Deep Convolutional Neural Network), allowing accuracy of 71.01%. Look up AlexNet for more reference and background on DCNN. Another classifier that the paper explores includes Support Vector Machine(which appears to be very useful in fake news detection as well and is very common in cancer detection techniques). This paper, in contrast to other papers in this field, focuses on getting a better image segmentation by increasing the contrast, suppressing noise to reach higher accuracy of breast cancer detection. Look up other image enhancement techniques that are referenced in this paper (E.g. Adaptive COntrast Enhancement, Contrast-limited Adaptive Histogram Equalization).
NOTES:
ASWATHY, M. A., M. JAGANNATH. 2017.Detection of breast cancer on digital histopathology images: Present status and future possibilities. Informatics in Medicine Unlocked, 8 : 74-79.
For the breast cancer detection idea, this paper references Spanhol et al. as the source of the data (over 7000 images) used in the training of the algorithm. The steps of the image processing from histopathology are: preprocessing of the images, then segmentation, extraction of the feature and classification. The paper is reviewing convolutional neural networks as an image processing method. Compared to the previous paper, this paper is focusing on the importance of biopsy methods of cancer detection as well as reviews other methods that are common in cancer detection. For future development, the paper is suggesting to explore spectral imaging as well as create more powerful tools to achieve higher image resolution.
Notes:
Look up: Spanhol et al. for the data – used over 7000 images
The steps involved in the algorithm for histopathology image processing include preprocessing of the images, then segmentation, extraction of the feature and classification.
The paper is observing the convolution neural network as an architecture for image analysis
This paper, compared to the previous one, is mainly focusing on the importance of biopsy in cancer detection, as well as reviews other methods that have been used in the sphere of cancer detection.
The paper has also suggestions for the future possibilities such as exploring spectral imaging. Another issue that the article mentions that can be solved is the creation of more powerful tools for the image resolution for digital pathology
Prediction Crime Using Spatial Features
BAPPEE, FATEHA KHANAM, AMILCAR SOARES JUNIOR, STAN MATWIN. 2018.Predicting crime using spatial features.In Canadian Conference on Artificial Intelligence,367-373. Springer, Cham.
This paper approaches crime detection from the perspective of geospatial features and shortest distance to a hotpoint. The end product of this paper is the creation of OSM (Open Street Map). The search of crime hotspots and spatial distance feature is done with the help of hierarchical density-based spatial clustering of Application with Noise (HDBSCAN). For crime patterns of alcohol-related crime the paper references Bromley and Nelson. Some other related works are also using KDE (Kernel Density Estimation) for hospoint prediction. The crime data is categorized into four groups: alcohol-related, assault, property damage and motor vehicle . The type of classifiers that the paper is using are: Logistic Regression, Support Vector Machine (SVM), and Random FOrest . Future improvement is suggested in the sphere of data discrimination.
NOTES:
Big Data Analytics and Mining for Effective visualization and Trends forecasting of crime data
FENG, MINGCHEN, JIANGBIN ZHENG, JINCHANG REN, AMIR HUSSAIN, XIUXIU LIM YUE XI, AND QIAOYUAN LIU.. 2019. Big data analytics and mining for effective visualization and trends forecasting of crime data. IEEE Access, 7: 106111-106123.
This paper is implementing data mining with the help of various algorithms: Prophet model, Keras stateful LSTM, neural network models. After using these models for prediction, the results are compared. For further data mining algorithms and application, we can look up Wu et al. and Vineeth et al. as these were references in the paper. Three datasets were used from three different cities: San-Francisco, Chicago and Philadelphia. The data from the following countries included the following features: Incident number, dates, category, description, day of the week, Police department District ID, Resolution, address, location ( longitude and latitude), coordinates, weather the crime id was domestic or not, and weather there was an arrest or no. For data visualization, Interactive Google Map was used in this paper. Market cluster algorithm was used with the aim of managing multiple markets for spatial scales and resolution.
NOTES:
Crime prediction using decision tree classification algorithm
IVAN NIYONZIMA, EMMANUEL AHISHAKIYE, ELISHA OPIYO OMULO, AND DANISON TAREMWA.2017. Crime Prediction Using Decision Tree (J48) Classification Algorithm.
This paper approaches crime detection with decision tree and data mining algorithms. This paper, compared to the previous one, gives context on predictability of crimes. The algorithms used in classification that the paper references to are: Decision Tree Classifier, Multilayered Perception (MLP), Naive Bayes Classifiers, Support Vector Machines (SVM). For the system specification, design and implementation a spiral model was used. The training dataset was taken from UCI Machine Learning Repository. For the training purposes Waikato Environment for Knowledge analysis Tool Kit was used.
NOTES:
-uses decision tree and data mining
– Touches upon the context behind the predictability of crimes
– uses classification algorithm – Decision Tree Classifier (DT),Multilayered Perception (MLP) , Naive Bayes Classifiers, Support Vector Machines,
The paper performs analysis on these algorithms based on their performance on crime prediction
-Spiral Model was used to specify the system, design it and implement it
– the dataset was taken from UCI machine learning repository
Waikato Environment for Knowledge analysis Tool Kit was used for the training of crime dataset
Beyond News Contents: the role of Social Context for Fake News Detection
SHU, KAI, SUHANG WANG, AND HUAN LIU.2019. Beyond news contents: The role of social context for fake news detection. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining, 312-320.
This paper proposes a tri-relationship framework for fake news detection that analyzes publisher-news relations as well as user-news interactions. The algorithm behind news content embedding is based on nonnegative matrix factorization that projects the news-word matrix to the semantics factor. The evaluation of reported performance is the average of three training processes of TriFN (tri-relationship framework) performances. This paper, in addition, also checks if there is an existing relationship between the delay time of the news and detection of fake news. It also analyzes the importance of social engagement on the performance of fake news detection.
NOTES:
Fake News Detection on Social Media Using Geometric Deep Learning
MONTI, FEDERICO, FABRIZIO FRASCA, DAVIDE EYNARD, DAMON MANNION, AND MICHAEL M. BRONSTEIN. 2019. Fake news detection on social media using geometric deep learning.arXiv preprint arXiv:1902.06673.
This paper uses geometric deep learning for fake news detection on social media. The paper hsa a main focus of data extraction adn testing on Twitter platform. The paper discusses convolution neural networks as a classification method. This paper questions the correlation between the time of the news’ spread and the level of performance of the implemented detection method. The paper also mentions the use of non-profit organizations in the process of data collection, specifically the following journalist fact-checking organizations: Snopes, PolitiFact and Buzzfeed. It is also important to look up pioneering work of Vosoughi et al., as that work is referenced in this paper of great importance in data collection in the fake news detection sphere. All of the features that news were classified into were four: User profile, User activity, network and spreading, and content. It is important to note that this paper mentions that the advantage of deep learning is that it can learn task-specific features given data.
NOTES:
FAKEDETECTOR: Effective Fake News Detection with Deep Diffusive Neural Network
ZHANG, JIAWEI, BOWEN DONG, S. YU PHILIP. 2020. Fakedetector: Effective fake news detection with deep diffusive neural networks. In 2020 IEEE 36th International Conference on Data Engineering (ICDE), 1826-1829.
This paper focuses on a novel model for fake detection – Deep Diffusive Model called GDU that can simultaneously accept multiple inputs from various sources. The paper compares deep diffusive network’s performance with already existing other methods. As a baseline for the fact checking, the paper is using PolitiFact – seems to be a common and reliable source for fact checking. The two main components of deep diffusive network models are: representation feature learning and credibility label inference. For related works need to check Rubin et al. that focuses on unique features of fake news, as well as Singh et al. that focuses on text analysis. In addition Tacchini et al. proposes various classification methods for fake news detection
NOTES:
“Liar, Liar Pants on Fire”: A New Benchmark Dataset for Fake News Detection
WANG, WILLIAM YANG, 2017. Liar, liar pants on fire: A new benchmark dataset for fake news detection. arXiv preprint arXiv:1705.00648.
This paper uses a dataset of 12.8K that was manually labeled from PolitiFact.com. The dataset is used as a benchmark for fake checking. This paper is focusing on surface-level linguistic patterns for fake news detection purposes. For this it uses a hybrid convolutional neural network for metadata integration. This paper has a different approach to the fake news detection problem: its viewing the news from a 6-way multiclass text classification frame and combines meta-data with text to get a better fake news detection.
NOTES:
EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
WANG, YAQING, FENGLONG MA, ZHIWEI JIN, YE YUAN,GUANGXU XUN, KINSHLAY JHA, LU SU, JING GAO.2018. Eann: Event adversarial neural networks for multi-modal fake news detection. In Proceedings of the 24th acm sigkdd international conference on knowledge discovery & data mining, 849-857.
This paper is the basis of a fake news detection algorithm in three component-consisted Event Adversarial Neural Network framework: multi-modal feature extractor, fake news detector and event discriminator. For textual feature extraction, the paper is using convolutional neural networks (CNN), while for twitter dataset content evaluation, the paper is using MediaEval Verifying Multimedia. The paper also eliminates those tweets that do not have media attached to the tweets. To detect fake news, the paper is also using Weibo Dataset.
NOTES: Derives event invariant features (extractor) ~
Fake News Detection via NLP is Vulnerable to Adversarial Attacks
ZHIXUAN ZHOU,HUANKANG GUAN, MEGHANA MOORTHY BHAT, JUSTIN HSU.2019. Fake news detection via NLP is vulnerable to adversarial attacks. arXiv preprint arXiv:1901.09657.
This paper approaches the fake news detection from the linguist classification point of view and targets the weakness of this method. The paper uses Fakebox for experimenting reasons. It uses McIntire’s Fake-real-news-dataset which is open source. The paper focuses on the text content of these dataset (which are in, approximately, 1:1 proportion label fake and real). The paper also brings up a possible solution to the weakness of the linguist classification of datasets: adoption in conjunction with linguistic characteristics.
NOTES: Paper approaches to the issues if linguistic classification of news
Breast Cancer detection using image processing techniques
CAHOON, TOBIAS CHRISTIAN, MELANIE A. SUTTON, JAMES C. BEZDEK.2000. Breast cancer detection using image processing techniques.In Ninth IEEE International Conference on Fuzzy Systems. FUZZ-IEEE 2000 (Cat. No. 00CH37063), vol. 2, 973-976.
This paper uses K-nearest neighbor classification method for cancer detection. This paper focuses on image processing from the Mammography screenings taken from Digital Database for Screening Mammography. To get better accuracy in image segmentation, the paper adds window means and standard deviation. This paper, when compared to related work in this field, does not review further related methods and techniques used in related works and does not compare results with other authors’ results.
NOTES: The paper uses k-nearest neighbor classification technique
Detection of Breast Cancer using MRI: A Pictorial Essay of the Image Processing Techniques
JAGLAN, POONAM, RAJESHWAR DASS, MANOJ DUHAN. 2019.Detection of breast cancer using MRI: a pictorial essay of the image processing techniques. Int J Comput Eng Res Trends (IJCERT) 6, no. 1, 238-245.
This paper is unique with its discussion of the weaknesses of MRI images. Those are: poor image quality, contrast and blurriness. The paper reviews techniques of enhancing image quality. The paper compared various image enhancement filters(Median filter, Average filter, Wiener Filter, Gaussian filter) and compared the results of noise reduction and image quality. The paper uses various statistical parameters for the final performance evaluation: PSNR(Peak signal to noise ratio), Mean Square Error (MSE), Root MEan Square Error (RMSE), MEan Absolute Error (MAE). The paper also reviews the most common noises present in MRI images: Acoustic Noise and Visual NOise
NOTES: touches upon weaknesses of MRi images – suffer poor quality of image, contrast, blurry
DEEPIKA SINGH, ASHUTOSH KUMAR SINGH. 2020. Role of image thermography in early breast cancer detection-Past, present and future. Computer methods and programs in biomedicine 183. 105074.
The paper presents a survey that took into consideration the following cancer detection systems:Image acquisition protocols, segmentation techniques, feature extraction and classification methods. This paper highlights the importance of thermography in breast cancer detection as well as the need to improve the performance of thermographic techniques. The databases used in this paper are: PROENG (from University Hospital at the UFPE), Biotechnology-Tripura University-Jadavpur University database. The paper reviews the role of quality of image segmentation in the reduction of false positive and false negative values in thermography.
NOTES:
DeepCrime: Attentive Hierarchical Recurrent Networks for Crime Prediction
HUANG CHAO, JUNBO ZHANG, YU ZHENG, NITESH V. CHAWLA. 2018. DeepCrime: attentive hierarchical recurrent networks for crime prediction. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, 1423-1432.
This paper uses deep neural network architecture as a classification method. The paper uses DeepCrime algorithm to find the relevance between the time period and crime occurrence. It addresses the main technical challenges when working on crime prediction: temporal Dynamics of crime patterns, complex category dependencies, Inherent interrelations with Ubiquitous data, and unknown temporal relevance. The paper uses the New York City Open Data portal for the crime dataset. Related works view crime detection in different methods. For example, Wang et al. uses the points of interest information for the crime prediction while Zgao et al. approaches crime prediction from the spatial-temporal correlation point of view.
NOTES: Uses deep neural network architecture
Predicting Incidents of Crime through LSTM Neural Networks in Smart City
ULISES M. RAMIREZ-ALCOCER, EDGAR TELLO-LEAL, JONATHAN A. MATA-TORRES. 2019. Predicting Incidents of Crime through LSTM Neural Networks in Smart City. in The Eighth International Conference on Smart Cities, Systems, Devices and Technologies.
This paper uses a long short-term memory neural network for the prediction algorithms. This neural network allows the network to choose among the data which ones to remember and which ones to forget. The process of these methods follows these steps: data pre-processing, categorization and construction of the predictive model. The neural network of this method consists of three layers: input layer, hidden layer and output layer. This paper also references toe Catlet et al. and highlights the correlation of the future crime rate to the previous week’s trend set. For the further spatial analysis and auto-regressive models the paper references Catlet et al.
NOTES: Uses Long Short-term memory neural network for the prediction algorithms
Deep Convolutional Neural Networks for Spatiotemporal Crime Prediction
LIAN DUAN, TAO HU, EN CHENG, JIANFENG ZHUM CHAO GAO. 2017. Deep convolutional neural networks for spatiotemporal crime prediction. In Proceedings of the International Conference on Information and Knowledge Engineering (IKE), 61-67.
Tihs paper proposes a Spatiotemporal Crime Network using convolutional Neural Network. The paper uses New York City (2010 -2015) datasets. The paper compares the following models: Rolling Weight average, Support Vector Machines, Random Forests, Shallow fully connected neural networks. The paper uses TensorFlow1.01 and CUDA8.0 with the aim of building STCN and SFCNN. A limitation of this paper is that it does not take into account various data types for better prediction performance, accuracy.
NOTES:
Idea 1: Masked Face Detection:
Introduction: Due to the fact that the virus that causes COVID-19 is spread mainly from person to person through respiratory droplets produced when an infected person coughs, sneezes, or talks, it is important that people should wear masks in public places. However, it would be difficult to keep track of a large number of people at the same time. Hence, my idea is to utilize machine learning to detect if a person is wearing a mask or not. Hopefully, this idea can help reduce the spread of the coronavirus.
Idea 2: Speaker Recognition:
Introduction: BookTubeSpeech is a newly released dataset for speech analysis problems. The dataset contains 8,450 YouTube videos (7.74 min per video on average) that each contains a single unique speaker. Not much work on speaker recognition has been done using this dataset. My work is to provide one of the first baselines on this dataset for speaker recognition / speaker verification.
Idea 3: Sport players prediction result using machine learning
Introduction: “How many yards will an NFL player gain after receiving a handoff?” I will be attending a competition on Kaggle. During the process, Kaggle would provide a dataset of players from different teams, the team, plays, players’ stats including position and speed to analyze and generalize a model of how far an NFL player can run after receiving the ball.
1. Fake news/unreliable source detection
Fake news detection algorithm would be an improved version of detecting unreliable sources. For this, I would need to come up with a database of credible data and identify the trustworthiness of the source based on that database.
Combination of multiple features will be required to identify to then evaluate the unreliability of the news/source. Some of those features are word combination, attached images, clickbait analysis, and checking whether the content is sponsored.
Machine learning would be used to create this algorithm ( some similar projects identified hybrid approaches that used user characteristics from a particular social media as well as the user’s social graph. The algorithm was based on node2vec that allowed extraction from social media followers/followers. )
My project would allow a user interface for interaction and manual news/source credibility check. This project would be unique with the accuracy of the source reliability and work on more than one medium.
2. Breast cancer detection
Various ways of cancer detection have been detected in recent years as technology and medicine start moving more hand in hand. Depending on the type of cancer, there are different ways of detecting cancer in medicine. For breast cancer, the most common methods of detecting are through MRI, breast ultrasound, mammograms.
Is there a way to get the hints of cancer early, before it has developed into its late stages?
I will be looking at previous work that has been done in integrating the medical records ( images from the methods mentioned above) into an algorithm of image processing and cancer detection.
I will be using image processing (from MRI, breast ultrasound, mammogram) to explore the historiography method. I will be looking at thermal body scan results as well and comparing these two approaches. For this, I will also explore the work done previously in this field.
I have searched and found various datasets present on Kaggle on mammogram scans.
3. Crime prediction/prevention
This project involves past crime analysis in a particular city (e.g., Boston or Indianapolis), takes the types of crime that happened in one of these locations, and uses machine learning neural networks to predict the possible crime location/hotspot. This project would rely on data mining through the records of crime.
This algorithm would also consider other features such as economic changes, news, and their impact on the crime rate. I consider taking into account the level of the crime and putting this into the analysis.
This app allows two(or more) people to instantly and directly connect with each other and exchange messages without any third party authorization. It operates completely on a peer-to-peer network, established among the users. This solves the privacy and tracking concerns of users who want to have a personal chat with others without worrying about their data being watched and sniffed. The mechanism is fairly simple: the user can create a meeting, and anyone with the url can join the meeting without any hassle of logging in/authorization.
Using the already existing IP address as identifier to build a peer-to-peer overlay network. But instead of naked requests to the server, I want to wrap the request with some layer of protection so that it ensures the data being safe and unsniffed. I want to build a software on the client side that handles data encapsulation and identification in order to join the network.
This is a AWS Lambda Serverless service that makes requests to Twitter tracking the frequency/occurrences of a stock name being mentioned and how it correlates to its movement in the stock market. The technology that could be used are a couple of Python scripts that make requests and analyze the data, possibly graphing or comparing with the closing price of a given stock. This does not attempt to predict a price in the future, but simply to see if there is correlation between a price movement versus the frequency of its name being mentioned in the social media.
UPDATE: After some talks with Charlie, the first two ideas can be combined as one. The first two would require more work and harder to iterate but a great source for acquiring the fundamentals of networks. The last one can be a great place to learn about AWS and their services, which is essential in its own right.
In the internship this summer, I had many good experience coding and dealing with webservers. But I had one bad experience: I had to web-scrape information for a week. It was a necessary job since we had to gather data for research purpose. But it was gnawing to say the least. At the time I just wish there was better web-scraping technology out there to help me deal with that nightmare.
I was able to write some software using some library but that did not make my life any less miserable. So I am thinking, maybe I want to make a web-scraper that is more general yet deal with information on a higher level. It can deal with almost any kind of information and any type of communication – whether it is static or ajax at load. And it can gather the common type of information that people search for: name, phone number, email, statistics, etc.
CS 388
David Barbella
Yujeong Lee
1) Sentiment Analysis on Popular Fiction Books (Data Science)
Research topic/question:
People have long discussed “formulas” for writing successful narrative fiction, such as the three-act structure or the hero’s journey, both models that follow a certain plot formula. I am interested in finding out whether a sentiment progression throughout a fiction book has a relationship to the popularity of the book.
Technology/data:
Python, pandas, Matplotlib. Sentiment analysis. Corpus from Project Gutenbeg.
General approach/method:
To find out whether there is a consistent pattern of sentiment, I will perform a sentiment analysis on each book, either by chapters, by n number of words (e.g. every 1000 words), or by n percentages (e.g. every 10% of the book). I will compare n books of high popularity, n books of medium popularity, and n books of low popularity, to observe whether certain patterns of sentiment correlates to popularity.
Difficulties/potential problems:
It will be difficult to quantify ‘popularity’. If determined by the number of books sold, an ancient book may have significantly more copies sold then a contemporary book of equal popularity. To select a corpus with reduced bias, I will consider limiting selections by a single genre, single author, and/or time (consider only books published between 1800-1900).
One other concern is that this project may yield no correlation.
2) COVID-19 in South Korea (Data Science)
Research topic/question:
Understanding COVID-19 in South Korea by approaching the comprehensive dataset with foundational questions, such as “How is the virus distributed among people of different age?”, “Which regions were most impacted by the virus?”, “Which specific location (certain bar, church) has been central in spreading the virus?”, “What pre-existing conditions have been the most detrimental to COVID patients?”, “Can the future number of cases be predicted through this data?”, “How does search trend relate to the magnitude of reported cases?”.
Technology/data:
Python, pandas, Matplotlib. South Korea COVID-19 dataset (https://www.kaggle.com/kimjihoo/coronavirusdataset)
General approach/method:
Cleaning the data, data visualization.
Difficulties/potential problems:
How can I use more creative methods to approach the data? Would it be possible to provide new insights when so many data analysis has been performed around the world already? Should I use a worldwide dataset, instead of one country?
3) Edge Detection for Scanned Images of Cuneiform Tablets (Machine Learning)
Research topic/question:
In collections that preserve ancient Mesopotamian cuneiform tablets, the tablets are digitized and uploaded to the database by scanning each edge of a tablet then combining each image into the shape of a ‘fat cross’, like a rectangular box net. This digitization of thousands of tablets is still done manually in some institutions (which was my internship last summer at the University of Chicago). I am interested in creating a specific edge detection algorithm that, when given a collection of tablet scans, correctly detects the edge of the tablet. Through research and experimentation/implementation, I will decide which edge detection algorithm is the most suitable for tablet scans.

Technology/data:
Python, NumPy, Matplotlib, edge detection methods (e.g. Canny edge detector, Sobel edge detector, Prewitt edge detector, Laplacian edge detector).
Raw images of cuneiform tablet scans (The Oriental Institute at the University of Chicago has made its digital collection available for the public. I can request high definition images for research here).
Difficulties/potential problems:
Evaluation metric: The edge detection method will need an evaluation metric. When processing manually, the standard is to leave a narrow border around the detected edge to prevent abrupt endings that potentially cut off inscriptions at the sides (see images below). I will have to quantify this.

Data: I will reach out to my previous supervisor at UChicago for more images of tablet scans. I can also reach out to a project manager at CDLI for images. However, there is a possibility they may not respond in time for the project.
Further possibilities, beyond this project:
Once I have the edge detection algorithm, I can further the project to completely automate the process of creating a ‘fat cross’ image. I can also create a web interface, which enables the user to dump a large number of tablet scans and retrieve a series of completed ‘fat crosses’.
Pitch #1
Style transfer and Image manipulation
Given any photo this project should be able to take any art movement such as Picasso’s Cubism and apply the style of the art movement to the photo. The neural network first needs to detect all the subjects and separate them from the background and also learn about the color schemes of the photo. Then the art movement datasets needs to be analyzed to find patterns in the style. The style will then need to be applied to the initial photo. The final rendering of the photo could get a little computationally expensive, if that is the case there will be need for GPU hardware. Imaging libraries such as pillow and scikit would be needed. It might be a little hard to find proper datasets since there are limited datasets available for each art movement. Contrarily I could rid myself of the need for readily-made datasets by training the network to detect style patterns by feeding it unlabeled paintings.
Pitch #2
Image manipulation detection
Neural network would be trained to detect image manipulation in a given photo. There are many ways to achieve this including but not limited to image noise analysis. Different algorithms can be compared to see which can do the best detection manipulation or which one was better automated with the training process.
Python libraries such as Keras and sklearn will be used for the Neural Network and the deep learning. Many previous research papers and datasets are available for this project or similar ones.
Pitch #3
Radiology disease detection
Trained neural networks for detecting radiology abnormalities and diseases have reached a level that can easily compete with a human radiologists. For this project I will be using neural network libraries to detect different abnormalities. There are very different field that this can apply to such as: Brain tumor detection, breast cancer detection, colonoscopy, CT/MRI, oncology, etc. I have already found many datasets for some of these applications. Again this is a very rich field with a lot of previous work and published papers to explore.
Link to project on GitLab: https://gitlab.cluster.earlham.edu/senior-capstones-2020/lmgray16-senior-capstone
Please refer to this link if the uploaded document is not working.

Here is the poster I created about my capstone project. I do plan to continue this project in the future so I will update the poster in the future.
Here is my paper for the Capstone Project that I turned in on May 3rd, 2020. Hopefully, in the future, I will have an updated version.
The repository for this software can be found at https://gitlab.cluster.earlham.edu/senior-capstones-2020/laurence-ruberl-capstone
I have been working on cleaning up and refining my code as well as the frontend. I also worked on the final poster as well as the final version of the paper.
This week I mostly worked on the final video, as well as making some small final touches to the paper based on Charlie’s suggestions.
I finished out some final kinks and have a fully functional version now.
I mostly worked on my poster during this week. There were a number of small issues with my original poster created using LaTeX, which I could not fix without delving into a lot of code, so I recreated it using power point and improved it based on Charlie’s feedback. Igor, my advisor, also pointed out a number of improvements that could be made to my paper, so I worked on an intermediate draft for additional feedback before I complete the final version.
In the past week, I worked on modifying my diagram and finished generating results. I also tried to draw meaningful insights from the validation results. After chatting with Xunfei, I finalized my poster and thought about elements to add to my paper.
This week I prepared my poster for the final submission, while editing also reworking my paper for the final submission next week. Last week I received feedback regarding user interaction and did research this week into what is the best way to build a GUI for my software.
I completed the second draft of my paper which required changes in the diagram, motivation for the project. The final draft shall have all the required and suggested materials. I am working on the final version of the poster which requires similar changes as the paper. Currently the application is in testing process. The QR code generation, scanning and the user login/logout process is all set. The aim is to improve the return books feature by adding an additional security layer to prevent book thefts. The librarian gets a list of books away from the library on the homepage and the student is charged a fine if its returned late.
I am working on distance calculation. I had to start from scratch since there are no tutorials online to follow so it is taking up time. The image model is still not working so I am going to make the user to input fruit name instead. I am going to wrap up the application development. Next week will be for accuracy testing.
I worked on the project poster. I also continued working on software demo v2 and finally submitted it. I discussed with Becky on scaling the accuracy testing, and the method I should use. I have found the food density data that I was planning to use is very limited so I am going to put some more data by manual calculation. I am focusing on fruits instead of foods.
I worked on integrating the camera into my application. I found the bug for image processing, but I am working on finding a way to install the CUDA toolkit on Google Cloud VM. I also worked on software demo version 2. I made some changes in my project to scale it down discuss those with Becky.
I was mainly in the process of transitioning.
I have been working on wrapping up my project and worked on finishing up the final paper and the poster. The obstacle remains the same where the model gives out very erratic outputs for sentences that are not in its vocabulary but works well with sentences that it has seen before. I will keep continuing to keep working on this and try to figure out a way to make it work, but this goal might be outside the scope of the project given the current workload and time.
During the past week, I have submitted the second version of my paper. After submission, I have continued working on the final parts of the paper. These parts include finishing the social engineering results and making the recommended changes to certain images to enhance my paper. With the given feedback, I have also started making changes to my senior poster which is due Sunday.
This week I submitted my second draft of the paper, which required lots of results production as well as time to write. I graphed prediction trends between different materials of foreign data with my model which also was demonstrating how my model was performing. I received great feedback from my advisor regarding the poster and paper and will look to improve these both this week for final submission.
This last week I tried to connect my C++ code with my Python code. I failed because I couldn’t convert from cv::Mat to Numpy Array. There were several problems with that. I will instead save the output of my C++ code as a jpg, and read the jpg in python. This is still considerably faster than using Python for the image processing part.
In the past week, I finished the coding part of my project and did some validation work. I revised my diagram and worked on my paper and poster. Next week, I will be focusing more on my paper and poster.
The second video was primarily focussed on the student application. As of now, a user can search for books based on categories like sports, academics, fiction, etc. They can issue books by scanning the QR code as well. The homepage of the student app needs some work, it will show which book is currently issued and give a brief history of the user and their activities in the library. In the coming week, I shall work on the 2nd draft of my poster, hope to complete the project and work on testing.
I worked on finishing the frontend and wrapping up my project and figuring out what metrics to use measure and compare my models with. I also worked on the poster for my project. This upcoming week I will work on wrapping up my final paper and add the description of my second model to the final paper.
I finished the first draft of the poster. While doing that, I needed to get the accuracies for my AI model and my image processing algorithm overall.
My AI accuracy was around 90% for the testing set. However, I realized my initial idea for measuring image processing accuracy was flawed. I have been working on some new, improved ideas.
This week we had the first draft of the poster due, which meant producing and visualizing a lot of results from my project. From this motivation, I compared my predictions across very different data (news articles, fictional novels, ect) and also was able to produce a convolution matrix that showed just how accurate my model was. This coming week I want to transfer these results into the next paper draft and continue with the user flow of the software.
I’ve mostly been working on making the poster and validating results. I found out that my original plan for validation would not work as nicely, so I will discuss with Xunfei to figure out what I can do. My diagram also needs to be tweaked.
I worked on the feedback I received from Igor concerning some of the difficult notation, and overall organization of my paper. I also removed some obvious lemmas and simplified the basic results for the second draft.
I downloaded some past posters to understand how to present my project idea through a poster. Working on the second draft of paper. Finishing up the admin app, in progress to complete all the features of the student app by the end of this week.
I couldn’t do much due to comps, but collected all information from participants to conduct the validation process. I also ran their results on my software and recorded the results. This week, I will work on extracting relevant reviews from Sephora to evaluate the efficiency of my method.
This week I further improved the pre-processing of sentences so that they are cleaner and easier to read on output. I then downloaded some previous year project posters to help with designing my own and have already completed half of it. It showed me that now I need to work further on results to present, on the accuracy of my model outside of its dataset.
I have finished the front end of the project, and am trying to wrap it up. One obstacle that I am facing is that my project proposed to have human testing, which will not be possible due to the current situation. I will be working on the poster in the next few days.
This past week I mainly worked on the first draft of my poster. It was much easier to complete since I have the majority of my project finished. In the coming week, I plan to continue my testing with my virtual servers, Kali and Metasploitable. Luckily, I have not encountered any obstacles when trying to use these two for testing. I also plan to continue work on the second draft of my paper.
I am having trouble with binding the C++ code to Python. Besides that pretty much everything is finished.
This week was (is going to) spent on working on the poster.
I worked on presenting the proof in the most succinct way possible for the poster. I worked on several iterations and finally narrowed down on what is the current first draft. I also received feedback on the first draft of my paper from Charlie, and discussed the paper as well as Charlie’s feedback with Igor.
I submitted the second software video. Finishing up the first version of the poster. I also received feedback on the first draft of my paper from Charlie, and discussed the paper and feedback with Charlie. Got valuable suggestion to work and improve in the second draft.