A Real Time Fall Detection System to Assist the Elderly Using Deep Neural
Networks
- What
research topic/question your project is going to address?
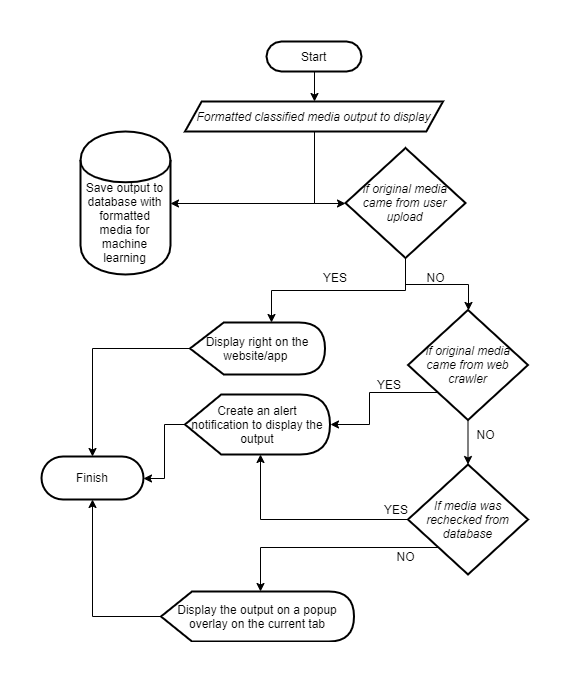
The elderly have a high chance of falling and get injured or faint. This
might put them to danger if they are alone. One way that can help the elder
people is having a system that can monitor their actions, detect the falling
action and other behaviors after falling down, classify the levels of severity
and send an alert to their emergency contacts or the emergency room if the
level is serious.
- What
technology will be used in your project?
Deep learning, pattern recognition, image processing
- What
software and hardware will be needed for your project?
Python, PyTorch (or Keras)
I might also need a CCTV camera if I decide to build the actual
device.
- How
are you planning to implement?
First I will apply some image processing techniques to enhance the images
and videos quality. If the dataset is small, I will use of image data
augmentation techniques to produce more data. Then train the model that detect
the person falling in the photo frame using deep neural networks, then use the
people falling photos and videos to train a model that classify the level of
severity. When the index of severity passes a threshold, send out the alert.
- How
is your project different from others? What’s new in your project?
There are several projects that work on the similar problem. Most of them
work on detecting the falling action only. In this project, I hope to build a
system that is more detail and can decide whether it is an emergency case.
- What’s
the difficulties of your project? What problems you might encounter during your
project?
I might not be able to find a big enough dataset to train
the model.