Unsupervised Anomaly Detection in Brain MRI
Comparison Analysis between 3D AutoEncoder vs 3D Denoising Diffusion Probabilistic Model
Sora Owada
on 2026-03-22
with
No Comments
Unsupervised Anomaly Detection in Brain MRI
Comparison Analysis between 3D AutoEncoder vs 3D Denoising Diffusion Probabilistic Model
My name is Kenny Shema, and I am a class of 2025 student pursuing a major in Computer Science and Economics.
My project consists of a personalized music recommendation system that uses real-time heartbeat data to suggest songs matching the user’s current mood or energy level. Built with a focus on integrating wearable sensor data and machine learning, the project aims to enhance emotional connection and user experience through adaptive, data-driven music selection.
My name is Helena Aleluya José, and I’m an international student from Angola. I’m also a Computer Science and Theater double major, and an African and African-American Studies and Creative Writing double minor. As both a computer scientist and a playwright, I wanted to create a project that reflects the intersection of my passions. For my senior capstone, I developed a framework that applies topic modeling techniques (LDA) to a corpus of dramatic texts in order to study playwright originality
This capstone project aims to develop a novel approach for analyzing and comparing playwrights’ unique voices and styles by applying topic modeling techniques, specifically Latent Dirichlet Allocation (LDA), on a corpus of theater texts. By leveraging advanced natural language processing (NLP) methods, the project will preprocess and prepare a diverse collection of plays for topic modeling, implement custom algorithms tailored for dramatic literature, and analyze the discovered topics to identify recurring themes, character archetypes, and narrative structures prevalent across different playwrights’ works. Interactive visualization tools will be developed to facilitate the exploration and interpretation of these insights, enabling literary scholars and critics to understand the creative processes better and the influences that shape dramatists’ voices.
Keywords
Topic modeling techniques, textual analysis, LDA model, Digital Humanities
Pet identification is important for veterinary care, pet ownership,
and animal welfare and control. This proposal presents a solution
for identifying dog breeds using dog images. The proposed method
applies a deep learning approach to identify the dog breeds. The
starting point for this method is transfer learning by retraining
existing pre-trained convolutional neural networks on the Stanford
Dog database. Three classification architectures will be used. These
classifiers will take images as input and generate feature matrices
based on their architecture. The stages these classifiers will undergo
to create feature vectors are 1) Convolution to generate feature
maps and 2) Max Pooling: highlight features are extracted from
the feature maps. Data augmentation is applied to the database to
improve classification performance.
The new version is the one used for the project but ver 5 was the last version to still include the sources for pitch A.
Abstract:
This paper presents the structure and design of a novel open-source textual database named the Brick Database for Minecraft settlements. Aimed at addressing the current lack of comprehensive datasets for model training in the Generative Design in Minecraft Competition (GDMC), this study explores the methodologies and potential challenges in creating a textual database and automatically detecting buildings and rooms.
Paper:
Software demonstration:
Poster:

Data diagram:
This project aims to build a system that uses machine learning algorithms to generate original music compositions based on original ones. This project will be studying machine learning techniques for pattern recognition.
The feedback I received from this seems to be more approachable than my first pitch, but I haven’t been able to receive more feedback because nobody has experience with this matter.
However, Doug questioned if there are Machine learning packages that I could use to build my project. Because in my project I aim to produce a new product from already existing ones. So, do we have packages to generate a new thing? It is possible to configure a train to produce something new.
I am currently getting in contact with the music department because there is a professor who teaches a class, “Making Music with Computer.”
I learned about software for music composition called “Max” which is a visual programming language for music and multimedia. I also learn about authors as David Cope, who he has a lot of work regarding artificial intelligence in music. I also investigated different types of music algorithms for composition and am currently looking for a specific problem or field to explore in this area.
Figure out because off all the complexity of this keep things simple.
Nowadays, it is very easy to get access to a lot of content online, including music, articles, games, videos, and movies. In the last couple of years, the use of video platforms such as YouTube has become very important for education, entertainment, hobbies, etc. However, YouTube is a platform where anyone can upload content, and not all content is appropriate to everyone. It can be because they may include sensitive content or bad words. This project will aim to use deep learning and machine learning for video analysis. It will require image processing to process video clips. It can also work with pattern recognition. This project aims to detect images and audio from the videos.
Challenge: video processing,
Data set of video file tag if they are not appropriate for children.
Potential dataset:
https://zenodo.org/record/3632781 (Restricted)
https://figshare.com/articles/dataset/The_Image_and_video_dataset_for_adult_content_detection_in_image_and_video/14495367/1 (adult content detention)
Youtube Data API (meta data)
Good Resources
This project aims to use machine learning to accurately translate real-time sign language to text by capturing sign language gestures using a camera (more likely from a computer’s web camera) to text. This system should be able to recognize various signs. I would like to study computer vision techniques.
From the input I received from Doug, this is a very ambitious project. We thought about what would be more convenient. Translate from moves gestures to text or from text to moves gestures. The first option seems to be more complicated because computer vision techniques can be a vast area. More than understanding computer vision techniques, but will also be required to recognize sign language and the context. To be able to train machine learning, I will require a lot of data that may not be easy to obtain.
This project will aim to have a friendly user interface. So it will be easy for the user to navigate through the translator.
Stroke is a cerebrovascular disease and is a significant causes of death. It causes significant health and financial burdens for the individual and the system. There are many machine-learning models built to predict the risk of stroke or to automatically diagnose stroke using predictors such as life factors or images. However, there has not been an algorithm that can predict using lab tests.
Idea #1
My research question:
What algorithms can be used to simulate policy making?
Public policy should obviously be for all citizens, but people often feel that their voices and real needs are not reflected in policy. In my home country of Japan, I have witnessed many voices on Twitter (now called X) about the policies they want from the government. I would like to create software that can use government data to simulate and predict what the impact would be if the government actually implemented those policies. Such a tool would help in better evidence-based policy making.
Idea #2
My research question:
How can we combine speech recognition, AI, and data extraction to automatically and instantly display the data mentioned in public discussions?
In Japan, when public policies are made, they have to be discussed in the Council or the Diet (Japanese national congress) in order to be approved. However, these discussions are often not easy to understand for the citizens for the following two reasons.
If the data (graphs and numbers) are automatically displayed when politicians refer to data by recognising the voice, policy-making will be more evidence-based and discussions will be easier for citizens to understand.
Idea #3 Computational Modeling of National Budget
My research question:
What algorithms can be used to better allocate the national budget?
What I realized while working with the government agencies in Japan last summer was that the policy-making process focuses heavily on the rationale of policies, and after they are approved, the evaluation is not as important as it should be. This could lead to a situation where the national budget continues to be allocated to policies that are not effective. If we can create a system to quantify the impact of each policy and also get comments from citizens, and use an algorithm to allocate the national budget, I think we could have a better cycle of public policy.
Facial Expression Recognition: This pitch will focus on facial expression recognition (FER) using convolutional neural networks (CNNs), which helps people with difficulties in communication, analyzes human’s emotion, and helps with development of AI in supporting humans during their daily life. Dataset: CK+ : 48×48 pixels images in grayscale format; face cropped; emotions includes anger (45 samples), disgust (59 samples), fear (25 samples), happiness (69 samples), sadness (28 samples), surprise (83 samples), neutral (593 samples), contempt (18 samples). Tufts Face Database: multi-modal face image images with more than 100,000 images, 74 females and 38 males from different age groups.
Kai Wang, Xiaojiang Peng, Jianfei Yang, Shijian Lu, and Yu Qiao. 2020. Suppressing uncertainties for large-scale facial expression recognition. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (2020), 6897–6906. https://openaccess.thecvf.com/content_CVPR_2020/html/Wang_Suppressing_Uncertainties_for_Large-Scale_Facial_Expression_Recognition_CVPR_2020_paper.html
This paper addressed a specific problem in large-scale FER, which is “uncertainties caused by ambiguous facial expression, low-quality facial images, and the subjective of the annotators” by using the Self-Cure Network. Because it focuses on a problem in FER, it is a good example if we want the purpose of our proposal to be about addressing a problem in the domain. It also mentions a lot of good dataset for FER along with works on FER using algorithms in the citation, which are good resources for our proposal. Related works in the field are also provided and went into detail to showcase the problem that the paper is focusing on. The methods that were proposed in the paper are based on the observation that CNNs can be uncertain about their predictions.
Shervin Minaee, Mehdi Minaei, and Amirali Abdolrashidi. 2021.Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Network. Sensors 21, 9, 3046. https://www.mdpi.com/1424-8220/21/9/3046
This paper is about FER using attentional CNNs. It discusses the challenges of FER and how attentional CNNs can be used to address them. The author proposed a new attentional CNN architecture that is able to focus on important facial regions for emotion detection. Because I decided to use CNN as the main method for processing the data in my paper, I can consider using the proposed attention CNNs from this paper. The proposed attentional CNN architecture consists of 2 main components: a feature extraction network and an attention network. The feature extraction network extracts features from the input image, while the attention network learns to focus on the most important facial regions for emotion detection.
Yunxin Huang, Fei Chen, Shaohe Lv, and Xiaodong Wang. 2019. Facial expression recognition: A survey. Symmetry 11, 10, 1189. MDPI. https://www.mdpi.com/2073-8994/11/10/1189
This paper is a survey for FER of visible facial expressions, which provides a lot of necessary background knowledge like terminologies and difficulties in the field. It also provided a throughout FER approach from beginning to end process including Image processing, feature extraction, gabor feature extraction, and expression classification. CNNs, Deep Belief Network, Long Short-Term Memory, Generative Adversarial Network are introduced and cited with current works related to them.
M. A. H. Akhand, Shuvendu Roy, Nazmul Siddique, Md Abdus Samad Kamal, Testuya Shimamura. 2021. Facial emotion recognition using transfer learning in the deep CNN. Electronics 10, 9, 1036. MDPI. https://www.mdpi.com/2079-9292/10/9/1036
This paper focuses on Deep CNN and Transfer Learning (TL). CNN is a popular technique used for FER and it is one that I’m considering moving forward with. This paper also focuses on using these techniques to reduce the development efforts, which is an understanding problem that all of the previous ones haven’t touched on. FER systems need to be able to handle occlusion, noise, and other challenges. Deep CNNs have been shown to be effective for FER tasks. CNNs are able to learn complex features from images, which can be helpful for identifying FER. Transfer learning is a technique where a pre-trained model is used as a starting point for a new model. This can be useful for tasks where there is limited training data available. In the paper, they introduced the technique of adopting a pre-trained Deep CNN model and replacing its dense upper layer(s) compatible with FER, and then fine-tuning the model with facial emotional data. This approach has been shown to achieve remarkable accuracy on both the FDEF and JAFFE facial image datasets.
Roberto Pecoraro, Valerio Basile, and Viviana Bono. 2022. Local multi-head channel self-attention for facial expression recognition. Information 13, 9, 419. MDPI. https://www.mdpi.com/2078-2489/13/9/419
This paper proposed Local multi-head Channel self-attention (LHC) in the context of computer vision and in facial expression recognition. LHC is a very new approach in the field of FER. This paper will be useful because the LHC module is a type of self-attention module that can be integrated into CNNs, and it has been shown to improve the performance of CNNs on FER tasks. In a CNN, each layer learns to extract different features from the input image. The LHC module allows the CNN to learn long-range dependencies between features, which can be helpful for FER.
Peter Anderson, Basura Fernando, Mark Johnson, and Stephen Gould. 2016. Guided open vocabulary image captioning with constrained beam search. arXiv preprint arXiv:1612.00576. https://arxiv.org/abs/1612.00576
I read this paper for another class, and I think it is pretty interesting if I can incorporate this into my paper. The paper proposed a method for improving the performance of open vocabulary image captioning models. Open vocabulary image captioning models are able to generate captions that contain words that are not present in the training data. The author introduced a technique called constrained beam search to guide the generation of captions. Contrainsed beam search forces the generated captions to include certain words. FER uses words “happy”, “sad”, “angry”, and “neutral”, constrained beam search could be used to force the system to predict at least one of these words in each prediction.
Sentiment analysis of online food reviewWhen people buy products online, the one thing that they tend to look closely at are the reviews of the product. Having good reviews and understanding the needs of the customers through the review can help the business grow tremendously. A review usually comes in two parts: the rating and the reviews. While the text-review system can be easy to interpret the customers’ overall experiences without any biases, the star-rating system tends to be less informative and it is up to the viewer to interpret the rating. This project aims to perform sentiment analysis on the reviews dataset, so it provides more accurate feedback on the products. Another aspect that this project can develop toward is that it can perform analysis on the negative languages on the recent reviews to let the businesses know what they should focus on improving. Amazon Fine Food Reviews dataset, which contains data over a 10 year period (1999 to 2012). Another plan to replace this dataset is using DoorDashAPI to collect reviews from the restaurants on DoorDash.
Yi Luo, and Xiaowei Xu. 2021. Comparative study of deep learning models for analyzing online restaurant reviews in the era of the COVID-19 pandemic. International Journal of Hospitality Management 94, 102849. Elsevier. https://www.sciencedirect.com/science/article/pii/S0278431920304011
The paper performs analysis on four features of 112,412 restaurants on Yelp and shows outcome comparison between algorithms. The data are collected by using a web scraper, which is a method that we proposed for our paper if we can’t find a more recent dataset. They also mentioned the process of data cleaning, which includes 2 procedures: tokenization and stopwords removal. They provided 2 deep learning and machine learning algorithms: gradient boosting decision tree classifier, random forest classifier, bidirectional LSTM, and simple word-embedding model. They also proposed both theoretical and practical implications for future work, which is a good place to find motivation for our paper.
Mayur Wankhade, Annavarapu Chandra Sekhara Rao, and Chaitanya Kulkarni. 2022. A survey on sentiment analysis methods, applications, and challenges. Artificial Intelligence Review 55, 7, 5731-5780. https://link.springer.com/article/10.1007/s10462-022-10144-1
This paper provided a background on sentiment analysis like the survey for FER, which also gives us a good start to understanding how to approach sentiment analysis. It provides a throughout beginning-to-end process of a sentiment analysis. I find it useful when reading about the 3 main approaches, which are Lexicon Based Approach, Machine Learning Approach, and Hybrid Approach. It also introduced some common machine learning algorithms for sentiment analysis: Naive Bayes, support vector machines, and deep learning. Naive Bayes is easy to implement and can be trained on a relatively small dataset. Support vector machines can be trained to achieve high accuracy, but they can be more difficult to implement and require a larger dataset than Naive Bayes. Deep learning algorithms like recurrent neural networks and CNNs are more difficult to implement and require a large dataset to train.
M. Govindarajan. 2014. Sentiment analysis of restaurant reviews using hybrid classification method. Sentiment analysis of restaurant reviews using hybrid classification method 2, 1, 17-23. https://www.digitalxplore.org/up_proc/pdf/46-1393322636127-133.pdf
This paper compared the effectiveness of different methods made for classifying restaurant reviews and whether it is beneficial to use ensemble techniques. It includes methods like Naive Bayes, Support Vector Machine and Genetic Algorithm. I think they provide a broad look at what methods are available for classification and that can be helpful for our paper, but I am not sure if it will be useful for our paper since we are not planning to explore classification in restaurant reviews but more about the sentimental analysis of it. However, the amount of paper available on the topic that I proposed is quite limited. If we can get access to one of the paper I listed below, they can be a good resource since it is more related to the direction I want to develop my proposal.
Anirban Adak, Biswajeet Pradhan, and Nagesh Shukla. 2022. Sentiment analysis of customer reviews of food delivery services using deep learning and explainable artificial intelligence: Systematic review. Foods 11, 10, 1500. MDPI. https://www.mdpi.com/2304-8158/11/10/1500
This paper focuses on AI and DL for sentiment analysis. They explained more about how AI, DL, ML are developing within each other. I think this paper acts as an overall guide on the techniques that I should use for my paper. It includes information about different AI methods that are used in sentiment analysis of customer reviews for food delivery services and also challenges when using DL techniques on customer reviews.
Maria Kostromitina, Daniel Keller, Muhittin Cavusoglu, and Kyle Beloin. 2021. “His lack of a mask ruined everything.” Restaurant customer satisfaction during the COVID-19 outbreak: An analysis of Yelp review texts and star-ratings. International journal of hospitality management 98, 103048. Elsevier. https://www.sciencedirect.com/science/article/pii/S0278431921001912
This paper is similar to what I might want to do for my pitch: it includes background information about the review text in relation to the choice of star-ratings. It also provides an interesting aspect of how Covid-19 affected the reviews of the customers, and how, depending on the situations, the reviews that the customers read might not help them make the right decision of choosing a good restaurant.
Ruba Obiedat, Raneem Qaddoura, Al-Zoubi Ala’M, Laila Al-Qaisi, Osama Harfoushi, Mo’ath Alrefai, and Hossam Faris. 2022. Sentiment analysis of customers’ reviews using a hybrid evolutionary svm-based approach in an imbalanced data distribution. IEEE Access 10, 22260–22273. IEEE. https://ieeexplore.ieee.org/abstract/document/9706209/
This paper, other than proposing new techniques for sentiment analysis, addresses the problem of imbalance dataset, which is a common problem to encounter in data analysis. Even thought, the paper doesn’t perform the work on an English-based dataset, it is useful to see how they deal with imbalance data problems. They use Naive Bayes, SVM, and Genetic Algorithm on the dataset, then compare with their proposed hybrid model built with all three classification methods
Pitch 1: Reduce the encounter of local minima in heuristic search space. In the heuristic search space of heuristic algorithms, there are areas where the nodes appear to be closer to the goal state, but when the algorithm encounters these areas, they actually wasted more resources to reach the goal. These areas are called local minima. Local minima tends to arise more when using distance to go as the heuristic value instead of cost to go, which is an aspect that this project plans to explore. Avoiding local minima and understanding the behavior can help improve the performance of heuristic search algorithms. Overall, this project will explore the problem of local minima with beam search.
Risk: There is limited information on this topic and a lot of knowledge gaps that will need to be filled.
Pitch 2: Facial expression recognition: classify facial expression using machine learning. Problem: help people in communication, analyze human’s emotion, help with the development of AI in supporting humans during their daily life. Dataset: CK+ : 48×48 pixels images in grayscale format; face cropped; emotions includes anger (45 samples), disgust (59 samples), fear (25 samples), happiness (69 samples), sadness (28 samples), surprise (83 samples), neutral (593 samples), contempt (18 samples). Tufts Face Database: multi-modal face image images with more than 100,000 images, 74 females and 38 males from different age groups.
Risk: Finding a suitable machine learning algorithm, process image data.
Pitch 3: Sentiment analysis of online food review. When people buy products online, the one thing that they tend to look closely at are the reviews of the product. Having good reviews and understanding the needs of the customers through the review can help the business grow tremendously. A review usually comes in two parts: the rating and the reviews. Users, a lot of the time, mistakenly choose the wrong rating for the products, so the reviews are more reliable in most situations. This project aims to perform sentiment analysis on the reviews dataset, so it provides more accurate feedback on the products. Another aspect that this project can develop toward is that it can perform analysis on the negative languages on the recent reviews to let the businesses know what they should focus on improving. Amazon Fine Food Reviews dataset, which contains data over a 10 year period (1999 to 2012). Another plan to replace this dataset is using DoorDashAPI to collect reviews from the restaurants on DoorDash.
Risk: dataset is not recent and will keep looking for a more recent dataset.
In today’s digital world, where online content is easily accessible, my project aims to use deep learning and machine learning techniques, such as Neural Networks, to tackle the challenge of inappropriate content on video platforms like YouTube. Using advanced image processing and pattern recognition, my goal is to detect and flag unsuitable imagery and audio within videos. With a focus on creating a child-safe environment, I aim to build a comprehensive dataset of video file tags, making online platforms more secure for users of all ages and fostering a responsible and enjoyable digital experience.
Research question: To improve the accuracy and efficiency of content classification on YouTube, can I compare and evaluate the performance of different deep learning architectures, such as Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) versus human judgment, in the context of detecting inappropriate content? What are the trade-offs in terms of computational resources and real-time processing?
Datasets:
https://zenodo.org/record/3632781 (Restricted)
https://figshare.com/articles/dataset/The_Image_and_video_dataset_for_adult_content_detection_in_image_and_video/14495367/1 (adult content detention)
YouTube Data API (metadata)
Good Resources:
2. Pitch #2: Machine learning for music recognition:
This project aims to use machine learning for music genre recognition. In a world where music is everywhere, music recognition can be a bit of a challenge. I will use machine learning techniques to teach the system to recognize unique patterns and characteristic that defines the music genre. I may try to duplicate already well-known models for music recognition and compare two of them to see which one is more efficient.
Research question: To optimize music genre recognition using machine learning, can we compare and evaluate the performance of traditional machine learning classifiers, such as logistic regression and support vector machines (SVMs), with deep learning architectures like convolutional neural networks (CNNs) using a diverse dataset? How do these algorithms perform in terms of accuracy?
Data sets:
Saki Pitches
This is a test
This is a test
About Me:
I am Andex Nguyen, a Senior who’s majoring in Data Science.
Introduction:
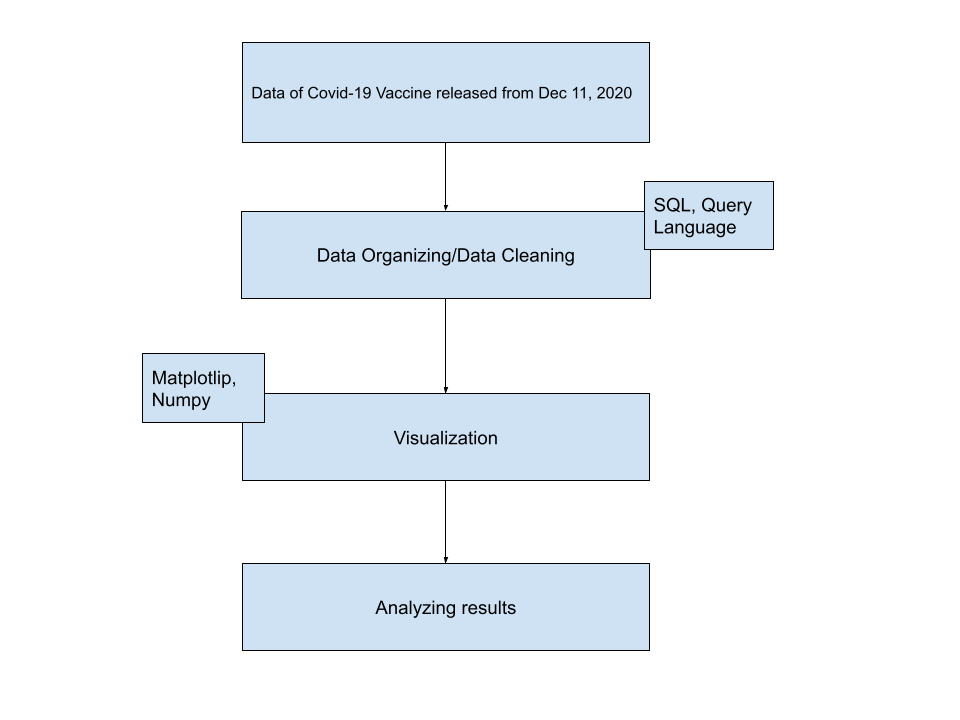
Since 2020 when the pandemic struck us for the first time, Covid-19 has always been a globally noteworthy issue. In this project, the questions that I am trying to find the answers for are how different countries in 1 region, specifically South-East Asian Countries, responded to the Vaccine, and what may be the reasons for that difference. A lot of the time, the matter of the people not having vaccinated stem from the political issues, economic and medical ability to acquire the vaccines, and the belief systems of those countries. My country, Vietnam, did very well in preventing Covid-19 by executing strong quarantine policies for our first step, and we proceeded to excellently secure an adequate amount of vaccines for our people. I want to see if the countries around the same area as my country also did a similarly good job. There would also be a case difference between fully vaccinated and those who are still waiting to complete their vaccination process.
Data Architecture Diagram:
GitLab link:


Uprisings are an act of resistance/rebellion. Uprisings could be the general population rising against the government (such as the protests in Zimbabwe as people protest over the poor economic conditions) or it could be people with morally questionable intentions against the general populace such as the Boko Haram in Nigeria. It is important to predict when uprisings are going to occur for the sake of peace and safety of everyone. This leads to the question of how we can possibly know before a social upheaval begins. Currently there is no official way to predict social unrest or a protest; people only know when a protest has already started. For this research, I will focus on using machine learning to study the effects of economic trends causing social uprisings. I use the trained machine learning model to predict when social upheaval’s are likely to happen. This model will be continually improved by doing exploratory data analysis to see which financial metrics are more reflective of the economy at any given time and using those metrics as input into the model. Continuously improving the accuracy of the model means we get closer to accurately predicting social unrest consequently ensuring the peace and safety of the public in the event of a protest
Hi, my name is Overpower Gore but everyone calls me OPG. I am a senior Data Science student at Earlham College with a passion for information technology. I have held multiple internships impacting positive organizational outcomes through software development, data analysis, and data visualization.
1)
I am interested in completing research related to the use of machine learning to generate decision trees which control non-player character behavior in video games. Decision trees are relatively interpretable and have a high-level correspondence to behavior trees, which are used in the most common approach to AI for video games (Świechowski, 2022). I also enjoyed working with them when I took Artificial Intelligence and Machine Learning. The two environments I would propose using for testing is the Micro-Game Karting template in the Unity Asset Store, which is available for free and was used for testing by Mas’udi (2021).
Annotated Bibliography
Chan, M. T., Chan, C. W., & Gelowitz, C. (2015). Development of a Car Racing Simulator Game Using Artificial Intelligence Techniques. International Journal of Computer Games Technology, 2015.
This paper argues that Unity, as a development platform for a racing game, has advantages over the use of traditional AI search techniques for implementation of path-finding. These points could help to justify a decision to utilize Unity as an environment for testing.
Fairclough, C., Fagan, M., Mac Namee, B., & Cunningham, P. (2001). Research Directions for AI in Computer Games. Department of Computer Science, Trinity College, Dublin.
This article gives a number of reasons for the simplicity of AI used by game developers in comparison to that used in academic research and industrial applications, and mentions a number of well-understood techniques in wide use at the time of its publication, including FSMs and A*. It also offers a number of reasons why research into AI for computer games is a worthwhile endeavor.
French, K., Wu, S., Pan, T., Zhou, Z., & Jenkins, O. C. (2019, May). Learning Behavior Trees from Demonstration. In 2019 International Conference on Robotics and Automation (ICRA) (pp. 7791-7797). IEEE.
This article gives advantages of behavior trees and describes two methods by which a decision tree can be converted to a behavior tree. This could be helpful in understanding the relationship between the decision trees which I intend to work with and the behavior trees that are prevalent in video game AI.
Guo, X., Singh, S., Lee, H., Lewis, R. L., & Wang, X. (2014). Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning. Advances in Neural Information Processing Systems, 27.
This paper presents results from game-playing agents whose performance was tested on the ALE, an environment which includes a variety of games for the Atari 2600 and thus would allow for testing the performance of decision trees on a range of different games, as well as permitting straightforward evaluation of the agent’s performance through scores achieved on the seven games used to evaluate Deep Q-Network. It also offers an example of the use of a method that would be infeasible for real-time play to generate training data for a faster agent, which, similar to the use of machine learning to generate a decision tree, uses a time-intensive process to create a classifier which can make decisions in real time.
Mas’udi, N. A., Jonemaro, E. M. A., Akbar, M. A., & Afirianto, T. (2021). Development of Non-Player Character for 3D Kart Racing Game Using Decision Tree. Fountain of Informatics Journal, 6(2), 51-60.
This article offers an example of the use of decision trees to control NPC behavior. The environment it uses, Micro-Game Karting, which is now known as Karting Microgame, also offers an accessible environment for testing the performance of decision trees.
Van Lent, M., Fisher, W., & Mancuso, M. (2004, July). An Explainable Artificial Intelligence System for Small-Unit Tactical Behavior. In Proceedings of the national conference on artificial intelligence (pp. 900-907). Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999.
This paper offers an example of one approach to transparency of video game AI, that of creating a distinct system to explain its action in retrospect, as well as a different context in which explainability is relevant. It could be compared with the use of behavior trees and decision trees to allow for transparency in video games.
2)
I wish to complete research related to the use of databases in video games to improve the efficiency of computations by increasing data locality and taking advantage of the optimizations of database management systems. While the article and dissertation by O’Grady (2019, 2021) which are referenced below both appear to focus on the feasibility of that approach, it seems likely that additional exploration is warranted regarding demonstrable advantages. For this exploration, I would propose focusing on the execution of path-finding through a database management system, one of the main areas examined by O’Grady (2021). Specifically, I wish to focus on sub-optimal path-finding, since optimality is generally not essential in the context of video games (Botea, 2013), despite the widespread use of A* (Kapi, 2020).
Annotated Bibliography
Abd Algfoor, Z., Sunar, M. S., & Kolivand, H. (2015). A Comprehensive Study on Pathfinding Techniques for Robotics and Video Games. International Journal of Computer Games Technology, 2015.
This article offers an overview of the various pathfinding techniques used for video games and robotics. It is organized by environment representation and could be helpful in comparing and evaluating path-finding algorithms in order to determine which to use with a specific representation. It might also assist in deciding on an environment representation.
Bendre, M., Sun, B., Zhang, D., Zhou, X., Chang, K. C., & Parameswaran, A. (2015, August). Dataspread: Unifying databases and spreadsheets. In Proceedings of the VLDB Endowment International Conference on Very Large Data Bases (Vol. 8, No. 12, p. 2000). NIH Public Access.
This paper describes a system created by unifying relational databases and spreadsheets, with the goal of retaining the advantages of spreadsheets while taking advantage of the power, expressivity, and efficiency of relational databases. The objective and approach of this research bear significant resemblances to those of O’Grady’s 2021 dissertation, in that both seek to increase the efficiency of a system by handling costly computations in a relational database. However, this article differs from O’Grady’s work in that it is based on a spreadsheet interface and an underlying database, rather than focusing on the implementation of specific components of a system within a database management system.
Botea, A., Bouzy, B., Buro, M., Bauckhage, C., & Nau, D. (2013). Pathfinding in games. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik.
This paper explains the logic and advantages of various approaches to path-finding in video games. It also recognizes that in video game contexts, suboptimal paths are acceptable
O’Grady, D. (2019). Database-Supported Video Game Engines: Data-Driven Map Generation. BTW 2019.
This paper provides a demonstration of how a portion of a game’s internals can be moved to a database system. Its goal is to show that the benefits of moving expensive computations to a database system can be obtained while still allowing straightforward modification of the process by game developers.
O’Grady, D. (2021). Bringing Database Management Systems and Video Game Engines Together (Doctoral dissertation, Eberhard Karls Universität Tübingen).
This dissertation is the main work which I intend to build on in my thesis. Specifically, I wish to further explore the advantages of implementing path-finding in a database management system, as covered in Chapter 4.
Kapi, A. Y., Sunar, M. S., & Zamri, M. N. (2020). A review on informed search algorithms for video games pathfinding. International Journal, 9(3).
This paper provides an overview of various ways of optimizing informed search algorithms for path-finding in video games, presenting various factors which influence memory and time usage. It would be useful for considering potential consequences of different experiment designs, given its focus on approaches to improving the efficiency of path-finding which do not rely on the optimizations of a database management system.
1)
I am interested in completing research related to the use of machine learning to generate decision trees which control non-player character behavior in video games. Decision trees are relatively interpretable and have a high-level correspondence to behavior trees, which are used in the most common approach to AI for video games (Świechowski, 2022). I also enjoyed working with them when I took Artificial Intelligence and Machine Learning. The environment I would propose using for testing is the Micro-Game Karting template in the Unity Asset Store, which is available for free and was used for testing by Mas’udi (2021).
References
Chan, M. T., Chan, C. W., & Gelowitz, C. (2015). Development of a Car Racing Simulator Game Using Artificial Intelligence Techniques. International Journal of Computer Games Technology, 2015.
Guo, X., Singh, S., Lee, H., Lewis, R. L., & Wang, X. (2014). Deep Learning for Real-Time Atari Game Play Using Offline Monte-Carlo Tree Search Planning. Advances in Neural Information Processing Systems, 27.
Mas’udi, N. A., Jonemaro, E. M. A., Akbar, M. A., & Afirianto, T. (2021). Development of Non-Player Character for 3D Kart Racing Game Using Decision Tree. Fountain of Informatics Journal, 6(2), 51-60.
Świechowski, Maciej and Ślęzak, Dominik, Monte Carlo Tree Search as an Offline Training Data Generator for Decision-Tree Based Game Agents (2022). BDR-D-22-00241, Available at SSRN: https://ssrn.com/abstract=4152772 or http://dx.doi.org/10.2139/ssrn.4152772
2)
I am considering completing research related to the use of databases in video games for purposes apart from data storage. While the article and dissertation by O’Grady (2019, 2021) which are referenced below both appear to focus on the feasibility of that approach, it seems likely that additional exploration is warranted regarding demonstrable advantages. For this exploration, I would propose focusing on the execution of path-finding through a database management system, one of the main areas examined by O’Grady (2021).
References
Muhammad, Y. (2011). Evaluation and Implementation of Distributed NoSQL Database for MMO Gaming Environment (Dissertation, Uppsala University).
O’Grady, D. (2021). Bringing Database Management Systems and Video Game Engines Together (Doctoral dissertation, Eberhard Karls Universität Tübingen).
O’Grady, D. (2019). Database-Supported Video Game Engines: Data-Driven Map Generation. BTW 2019.
Jovanovic, R. (2013). Database Driven Multi-agent Behaviour Module (Thesis, York University).
3)
I am also considering completing research related to the use of machine learning for recognition of Kuzushiji, an old style of Japanese cursive writing. Kuzushiji mainly appear in works from the Edo period of Japanese history and are difficult to identify correctly due to their lack of standardization (Ueki, 2020). Another difficulty comes from the Chirashigaki writing style, in which text is not written in straight columns (Lamb, 2020). The Center for Open Data in the Humanities has released a dataset of them (Ueki, 2020), which is available at http://codh.rois.ac.jp/char-shape/.
References
Clanuwat, T., Bober-Irizar, M., Kitamoto, A., Lamb, A., Yamamoto, K., & Ha, D. (2018). Deep Learning for Classical Japanese Literature. arXiv preprint arXiv:1812.01718.
Clanuwat, T., Lamb, A., & Kitamoto, A. (2019). KuroNet: Pre-Modern Japanese Kuzushiji Character Recognition with Deep Learning. arXiv preprint arXiv:1910.09433.
Lamb, A., Clanuwat, T., & Kitamoto, A. (2020). KuroNet: Regularized Residual U-Nets for End-to-End Kuzushiji Character Recognition. SN Computer Science, 1(3), 1-15.
Ueki, K., & Kojima, T. (2020). Feasibility Study of Deep Learning Based Japanese Cursive Character Recognition. IIEEJ Transactions on Image Electronics and Visual Computing, 8(1), 10-16.
Machine Learning and Dueling:
A fighters skill comes from their training, their learned experience through failure, and thousands of reps. This is also exactly how reinforcement learning agents gain their skills– I propose a mutli-agent learning experiment where we attempt to teach two agents how to fight with swords and shields.
There are a couple common issues that hinder how AI’s learn in a 3D space. First, multi-agent learning (learning with two or more agents) is notoriously challenging. This is made difficult because an agent not only must learn how to move in general, but also move around another agent. As of 2017, a recent algorithm called MAD-DPG has proposed a solution to this problem, but it’s still buggy and could present issues. Additionally, without proper motion capture data, the agents will learn incorrectly, most commonly seen in issues like body parts artifacting through the ground. Finally, while I have motion capture data for individual fighting movements, such as slashing a sword or blocking with a shield, it is much more difficult to find motion capture data that of two humans sword fighting. Finally, swords and shields will be weighted, throwing off the model’s sense of balance, which will take lots of training to get used to.
Using Unity 3D machine learning agents made possible through PyTorch, CUDA and the unity facing engine, ML-agents, I propose I propose creating a deep reinforcement learning agent. Our control strategy would have 2 parts, a pretraining stage (a deep learning model used to create a neural network to solve problem) and a Transfer learning stage, which uses a prebuilt neural network from our pretraining stage to solve a problem.
Steps of pretraining:
Steps of Transfer Learning:
Social Simulation of Scaricity:
Scarcity–how do we divide resources fairly when their isn’t enough for everyone? The entire subject of Economics boils down to this question, and has caused many conflicts throughout history. Sometimes, we have to make tough decisions because of scarcity.
I propose an experiment in a simulated world, with two “tribes” of agents. The agents must eat once a day, which is done by collecting food blocks. Each agent has the ability to move, eat, collect food for their village, ask others to share, and kill eachother. Each agent’s main priority is to eat for as many days as possible. If they go a full day without eating, they starve to death.
Then, we test these tribes under different levels of scarcity:
If the agents have plenty, will they remain peaceful? If there’s a moderate distribution, will the tribes share with eachother and lose the same number of members? Will they fight the other tribes for resources? If the resources are scare, will a tribe sacrifice members of their own tribe, or steal from the other tribe? Is fighting inevitable with an unfair disruption?
In order to do this experiment, we must allow for a level of teamwork. Each tribe has their own Competive Learning Policy which builds a nueral network, judging its success by how many tribe members are left after a given period of days. These networks may give tasks such as move, attack or collect food to any tribe member.
Usually, two agents learning against eachother means slower learning, but because the neural network are essentially playing a simple strategy game against eachother, they’re learning might be accelerated due to the competition.
Creating Unique Architecture with Machine Learning:
Necessity, the mother of invention. From the water carrying aqueducts of Rome to the houses stacked across the mountains of Tibet, people have made unique and intricate structures out of necessity. Typically, neural networks are trained with data sets, which they then attempt to imitate according to a metric of success. However, what they produce isn’t truely unique, it’s an imitation of what a researcher asks them to create. I propose an experiment to create entirely unique, AI generated 3D architecture by providing the necessity to build.
First, we must make environment simple enough for an neural network to learn to create in, but succifciently complex enough to cultivate interesting innovation. Unity 3D is ideal to create this enviroment, as it already has a well-developed physics engine, adding additional enviromental conditions is simple, allows for easy map creation, has many free assets to use, and supports machine learning.
Second, we must create necessity. Two agents will be created, a Creature and a Creator agent. The Creature is a simple bot, who’s only goal is to keep his three needs satisfied. The creature wants to stay warm, dry, and well fed. Warmth is decreased when “wind” comes in contact with our agent, dryness is decreased when rain comes in contact with our agent, and hunger is decreased by collecting food blocks.
The Creator agent has a simple goal, keep the Creature as warm, fed, and dry as possible. The Creator is a neural network with the ability to build, under the conditions of the physics engine. This neural network has permission to use a limited amount of two different resources: Wood and stone. Stone is much stronger then wood, but also much heavier. Wood is weaker, so it breaks under weight, but also lighter and more accessible. Wood and stone come in blocks, and wood also comes in plank form, which is worse for walls but better for roofs. The Creator has the ability to “nail” materials together, which means the materials may be connected together through touching vectors, unless the weight of materials attached to it is too heavy to hold.
Beyond coming with a well developed and well tested physics engine, the beauty of the Unity engine is it’s ease of customimability. Because it’s a game engine, adding new conditions is made easy. Once our Creator network has learned to build basic structures, we can up the complexity of the structures by adding more needs. Possibilities include:
The goal is to create unique and interesting structures, and a simulation made too simple will lead to uninteresting building. Unity 3D’s easy ability to add and remove these conditions will be vital to this experiment, as these new conditions may create innovate, or break and confuse our neural network.
My name is Hang “Hailee” Dang. I am a senior majoring in Data Science with interest in Finance, Data and Business Analytics.
Hello! My name is Tamara and I am a senior Computer Science Major at Earlham College and this is my capstone project. I am interested in applying machine learning and other computational techniques for better understanding of social issues. Here is the abstract of my capstone project proposal.
Unmanned Aerial Vehicles (UAVs) have only recently been applied
in the detection of clandestine graves. With the growing technical
abilities of UAVs, more opportunities are available in methods
for recording data. This opened many doors for detecting hidden
graves because now many different sensing devices can be used
in remote areas that were inaccessible to humans. This study will
compare the use of hyperspectral and RGB images taken by drones
to detect hidden graves. It is aiming to compare how accurately
the graves can be detected post-image processing using the same
technique. The primary motivation is to help future researchers
more easily decide which data collection technique they should use.
The processing technique used on both data sets is a model with
an edge detection algorithm.
Hello! My name is Tamara and I am a senior Computer Science Major at Earlham College and this is my capstone project. I am interested in applying machine learning and other computational techniques for better understanding of social issues. Here is the abstract of my capstone project proposal.
Unmanned Aerial Vehicles (UAVs) have only recently been applied
in the detection of clandestine graves. With the growing technical
abilities of UAVs, more opportunities are available in methods
for recording data. This opened many doors for detecting hidden
graves because now many different sensing devices can be used
in remote areas that were inaccessible to humans. This study will
compare the use of hyperspectral and RGB images taken by drones
to detect hidden graves. It is aiming to compare how accurately
the graves can be detected post-image processing using the same
technique. The primary motivation is to help future researchers
more easily decide which data collection technique they should use.
The processing technique used on both data sets is a model with
an edge detection algorithm.
My name is Khoa, and I am a senior, double-major in Quantitative Economics and Data Science. My tentative project focuses on the application of Machine Learning to study the physical-chemical properties of different molecule structures, which has been proven useful in many fields like drug discovery, materials science, biology, etc.
Hi everyone, I am Devin. I’m a Data Science major and a senior.
For my project, I am creating a win probability model for the National Hockey League. Hockey has been one of my favorite sports since I was a little kid and applying statistical concepts to one of my favorite sports excites me. Ultimately, I would like to compare the model that I build to other win probabilities for the NHL. The model accuracy would be assessed by how well it can predict which team wins the game.
I am Tra-Vaughn James, a Computer Science major, and Junior:
Today, Bioinformatics is an evolving field, in which computing resources have become more powerful, readily available and workflows have increased in complexity. New workflow management tools (WMT) attempt to develop software that fully harnesses this computational power, creating intuitive implementations utilizing machine learning techniques. This streamlines the design of complex workflows. However, overarching problems still remain that newer workflow management tools do not fully address: they are too specific to particular use cases, and they present a great learning curve for users unfamiliar with computing environments. Many implementations require one to spend copious amounts of time understanding the tool and adjusting already existing frameworks to ones needs, creating frustration and inefficiency. This problem is experienced by both novice and experienced bioinformaticians alike. Using OpenWDL, a Workflow Description Language, as the basis, I seek to develop an open in use workflow management tool coupled with a GUI interface. As OpenWDL is a widely known WMT, its familiarity will aid in my implementations usability. Additionally, the GUI interface will present a more welcoming environment than that of a command line interface in which many WMT’s often employ. To assess the effectiveness of my implementation, I will then assess it to other WMT’s, comparing its usability and openness to other bioinformatic pipeline managers such as SnakeMake and NextFlow.
A low-cost portable sensor system allows users to monitor the different components of the air quality around them. There is a need for a sensor system like this because of the millions of deaths and diseases that occur every year due to air pollution worldwide. My planned contribution is for the prototype sensor system I design and build to be as DIY (do it yourself) and low-cost as possible while still being usable in a theoretical online network for large-scale pollution mapping in real time. I will program the sensors together and investigate the calibration of the sensors because they can fall out of calibration after extended periods of time. I will evaluate the results of my experiment of building and using the sensor system by: the robustness of the system indoors and outdoors, analyzing the repeatability of the experiment, accessing how the system could further be improved for ease-of-access to users financially, testing system portability, and the practicality of the theoretical network that could be made with multiple sensor-systems.
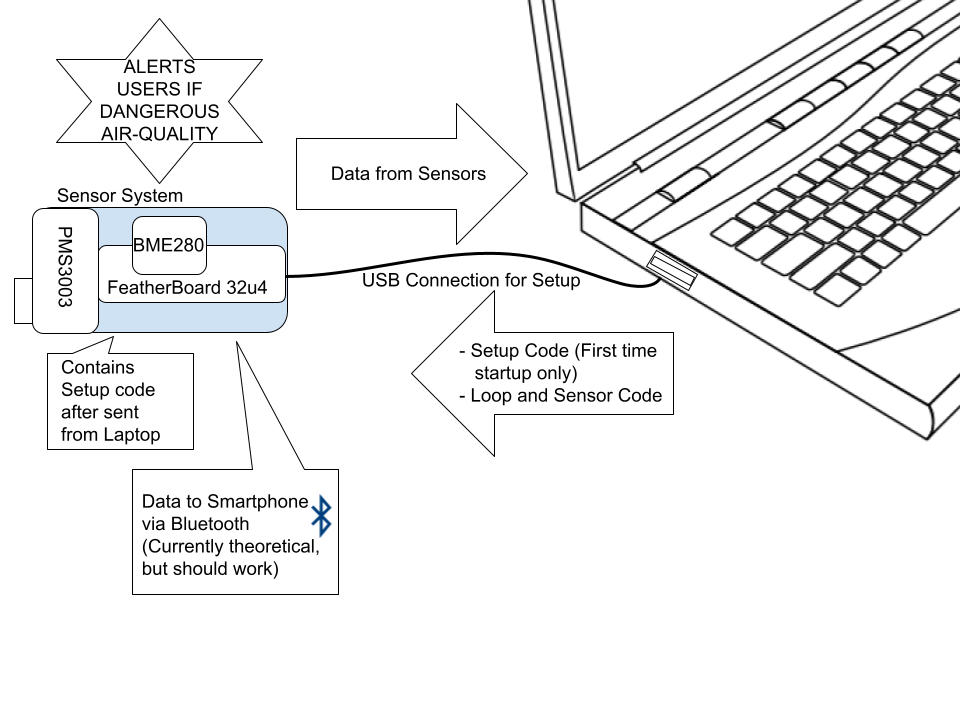
https://code.cs.earlham.edu/jccosta181/sensor-system-research
Final Proposal: https://drive.google.com/file/d/1G8MKPq0wwN7Z83wQYncKorOK_4xJpni6/view?usp=sharing
Presentation: https://drive.google.com/file/d/1UC4GmRP-SzGlXY010vyLMKU9AB8n6Y7C/view?usp=sharing
Pitch 1: Website that creates tangible, engaging visualizations of probabilities.
Humans are poor at conceptualizing probability. I notice that one common reason anti-vaxxers use for refusing the vaccine is that they’d rather take their chances with catching covid than get the shot and come down with complications, which is far rarer than the chance of dying from covid. The objective of this project would be to create a website with high user engagement that would inform users of the odds of certain events happening using tangible, engaging visualizations. The user would be able to select from a list of events to compare. Visualizations that represent a dangerous event that is likely to occur will look visually more dangerous than those that are less likely to occur.
I have found some potentially useful datasets to use
Questions
Graphics
Some sources I found that may be useful/interesting:
Pitch 2: Formality indicator for Japanese text
Google translate and Deepl don’t really give users the option to indicate what context a user needs to use Japanese in. One key thing that distinguishes different styles of speech or written communication is the choice in vocabulary. On Jisho, an online Japanese dictionary, some words are marked with what context they are used in. i.e. colloquial, slang, sonkeigo,(Honorific or respectful language). My proposed project would use web scraping from online dictionaries to gather data about which words are used in which context and would tell the user what level of formality the text is in and who it would be appropriate to say/send to.
Ana sent me a list of tools that may be useful. Sudachipy seems promising
Other sources
Pitch 3: Visualization of cause of death
I feel like death statistics are inherently somewhat dehumanizing, and I want to use recent death statistics to create a more human representation. The user would be able to enter certain demographics, such as location, age, sex, etc. This would be pretty similar to pitch one, but I would want to represent each person with something that people would empathize with. Perhaps instead of using the data outright, I would gather patterns from the data to create a fake population. I’m not sure how I might do this
Questions
Problems
I have found several sources for cause of death data on kaggle, but not all are completely recent, which is ideally I am looking for. I did find recent data specifically for Brazil. The CDC has some data as well, I just need to figure out how to get at it.
Pitch #1
The use of computing resources allows the processing of biological data and computational analysis. However in order to conver this data into useful information requires the us of a large number oftools, parameters, and dynamically changing reference data. As a result workflow managers such asSnake and OpenWDL were created to make these workflow scalable, repeatable and shareable. However, many of these workflow managers offer ambiguity toward creating workflows often lacking the specificity many other workflows require. I plan on creating bioinformatics workflow in which can be specified to particular workflows.
Bioshake: A Haskell EDSL for Bioinformatics workflows
Justin Bedő. 2015. Experiences with workflows for automating data-intensive bioinformatics – biology direct. (August 2015). Retrieved January 9, 2022 from https://biologydirect.biomedcentral.com/articles/10.1186/s13062-015-0071-8
Reproducible, scalable, and shareable analysis pipelines with bioinformatics workflow managers
Laura Wratten, Andreas Wilm, and Jonathan Göke. 2021. Reproducible, scalable, and shareable analysis pipelines with bioinformatics workflow managers. (September 2021). Retrieved January 9, 2022 from https://www.nature.com/articles/s41592-021-01254-9
Paper highlights the key features of workflow manager and comapares commonly used approaches for bioinformatics workflows.
A versatile workflow to integrate RNA-seq genomic and transcriptomic data into mechanistic models of signaling pathways
Martín Garrido-Rodriguez et al. 2021. A versatile workflow to integrate RNA-seq genomic and transcriptomic data into mechanistic models of signaling pathways. (February 2021). Retrieved January 9, 2022 from
MIGNON is used for the analysis of RNA-Seq experiments. Moreover, it provides a framework for the integration of transcriptomic and genomic data based on a mechanistic model of signaling pathway activities that allows for a biological interpretation of the results, including profiling of cell activity. Entire pipeline was developed using the Workflow Descriptions Language (OpenWDL). All the steps of the pipeline were wrapped into WDL tasks that were designed to be executed on an independent unit of containerized software by using docker containers, which prevent deployment issues.Paper is an excellent source of seeing how WDL performs as workflow management language and the various problems that can occur from it.
Planning Bioinformatics workflows using an expert system.
Xiaoling Chen and Jeffrey T. Chang. 2017. Planning Bioinformatics workflows using an expert system. (January 2017). Retrieved January 9, 2022 from https://academic.oup.com/bioinformatics/article/33/8/1210/2801462?login=true
ACLIMATISE: Automated Generation of Tool Definitions for bioinformatics workflows.
Michael Milton and Natalie Thorne. 2020. ACLIMATISE: Automated Generation of Tool Definitions for bioinformatics workflows. (December 2020). Retrieved January 9, 2022 from https://academic.oup.com/bioinformatics/article/36/22-23/5556/6039117?login=true
Paper presents aCLImatise which is a utility for automatically generating tool definitions compatible with bioinformatics workflow languages, by parsing command-line help output. This utility can be used withing our workflow to create tool definitions.Workflow definitions must be customized according to the use-case, however tool definitions simply describe a piece of software, and are therefore not coupled to a single workflow or context this aCLImatise will not have a hindrance on workflow creations.
SciPipe: A workflow library for agile development of complex and dynamic bioinformatics pipelines.
Samuel Lampa, Martin Dahlö Jonathan Alvarsson, and Ola Spjuth. 2019. SciPipe: A workflow library for agile development of complex and dynamic bioinformatics pipelines. (April 2019). Retrieved January 9, 2022 from https://academic.oup.com/gigascience/article/8/5/giz044/5480570?login=true
Using rapid prototyping to choose a bioinformatics workflow management system
Michael J. Jackson, Edward Wallace, and Kostas Kavoussanakis. 2020. Using rapid prototyping to choose a bioinformatics Workflow Management System. (January 2020). Retrieved January 9, 2022, from https://www.biorxiv.org/content/10.1101/2020.08.04.236208v1.abstract
Pitch #2
New technologies have been evolving to aid life within the home. Video door bells, cameras and smart devices make many tasks much simpler than they use to be. However, the threat of security and ensuring that those with malicious intent are unable to hack and harm your home network has also increased, a failure in security could expose all of your personal information. As a result of this many organizations provide VPN services that have been developed as a means to protect people from the dangers of malicious hackers and malware. However, these same VPNS come with some faults such as higher cost and limitations as dictated by the provider , and the fact that paid services place you in the hands of the operator and its various cloud/network providers with no certainty that these providers will not snoop around in your data.
A VPN server that a user can host on there local machine solves all of these aforementioned problems with the added benefit of the user being able to securly access and maintain there home network.The server will be held in a virtual machine and will allow the user to be in complete control of it and its functions. This will increase efficiency of the VPN as the user no longer has to go through the network of the provider. My goal is to automate and open-source this process creating an easy launchable VPN server an average user can easily launch and use to maintain access to their home network.While at the same time being capable being edited and changed by the user for more robust security. I seek to compare this to similar paid services identifying which is more secure for the user.
What is a VPN?
Paul Ferguson and Geoff Huston . 1998. What is a VPN. (April 1998). Retrieved January 7, 2022 from https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.169.7689&rep=rep1&type=pdf
Paper defines what a VPN is. Further describes different types of VPN’s such as Network Layer VPN’s how they are constructed and the underlying protocols and techniques used create one. Breaks down the various VPN’s in accordance to the TCP/IP protocol. Describes VPN concepts such as Controlled route leading and Tunnelling. Overall this paper is a good source for understanding the basics of what a VPN is aswell aas the types, and procedures to setup one.
Implementation and analysis ipsec-vpn on cisco asa firewall using gns3 network simulator
Dwi Ely Kurniawan1, Hamdani Arif1, N. Nelmiawati1, Ahmad Hamim Tohari1, and Maidel Fani1. 2019. Implementation and analysis ipsec-vpn on cisco asa firewall using gns3 network simulator. (March 2019). Retrieved January 8, 2022 from https://iopscience.iop.org/article/10.1088/1742-6596/1175/1/012031/meta
This paper provides an example of constructing VPN and testing it using a virtual setting in which is a similar approach in which I am thinking of using. It is built using GNS3 network simulator software and virtual Cisco ASA Firewall. The result shows that VPN network connectivity is strongly influenced by the hardware used as well as depend on Internet bandwidth provided by Internet Service Provider (ISP). In addition to the security testing result shows that IPSec-based VPN can provide security against Man in the Middle (MitM) attacks. However, the VPN still has weaknesses against network attacks such as Denial of Service (DoS) that causes the VPN server can no longer serve VPN client and become crashes.
Enhancing security and privacy in local area network with TORVPN using Raspberry Pi as access point
Mohamad AfiqHakimi Rosli. 2019. Ehancing security and privacy in local area network with TORVPN using Raspberry Pi as access point . (October 2019). Retrieved January 8, 2022 from https://ir.uitm.edu.my/id/eprint/26068/
Provides another method of utilizing VPN servers to protect one’s local network.
Involves the Tor routing technique providing an extra layer of anonymity and encryption.
Although this approach requires the use of Rasberry pie for its implementation it would eliminate the need for installation and configuration of software while also making such services accessible to others.
A Remote Access Security Model based on Vulnerability Management
Samuel Ndichu, Sylvester McOyowo, and Henry Wekesa. 2020. A remote access security model based on … – MECS press. (October 2020). Retrieved January 11, 2022 from https://www.mecs-press.org/ijitcs/ijitcs-v12-n5/IJITCS-V12-N5-3.pdf
Client-Side Vulnerabilities in Commercial VPN’s
Bui Thanh, Rao Siddharth, Antikainen Markku, and Aura Tuomas. 2019. Client-side vulnerabilities in commercial vpns | springerlink. (November 2019). Retrieved January 11, 2022 from https://link.springer.com/chapter/10.1007/978-3-030-35055-0_7
Beyond the VPN: Practical Client Identity in an Internet with Widespread IP Address Sharing
Yu Liu and Craig A. Shue. 2021. Beyond the VPN: Practical client identity in an internet with widespread IP address sharing. (January 2021). Retrieved January 10, 2022 from https://ieeexplore.ieee.org/abstract/document/9314846
Research on network security of VPN technology
Zhiwei Xu and Jie Ni. 2021. Research on network security of VPN Technology. (May 2021). Retrieved January 11, 2022 from https://ieeexplore.ieee.org/abstract/document/9418865
Idea #1
Using machine learning to identify if a webpage is malicious, sometimes websites are blacklisted and that’s how they are identified as malicious but its cumbersome to do that for every website and constant new sites, use ML to identify malicious sites based on keyword density and improve upon existing methods. Other factors that could be used to identify the malicious website are URL length, website age, country of origin. Identifying the most important features to use for ML will be key to the project. A nuance I could add would be to identify the type of attack associated with the URL and rank its severity. Short URLs are a way that malicious attackers attempt to circumvent detection. Being able to expand short URLs in order to extract features could allow for current tools to be more effective.
Idea #2
Calculate expected goals of premier league soccer teams. Expected goals is commonly used as a predictor to help analysts identify skillful players and predict the winning team. There is a mass of datasets to use and techniques that could be analyzed for efficacy and improved upon. A possible nuance I could add is comparing expected goals of a player to their wages or expected goals to the teams’ total wage bill to find efficient teams.
Idea #3
Using machine learning to identify network attacks specifically DOS attacks. Most current methods use huge and cumbersome MIB databases. I would explore more efficient and less time and resource-consuming methods for classifying the data and identifying anomalies within network traffic. Data can be classified by where it comes from, to help determine if it may be malicious. There is less specific research on this topic as most of it is specific to a domain or the data is private.
Idea 1 : Maze Generation
I would like to examine maze generation algorithms for the purpose of generating more challenging domains for search algorithms to solve. Creating domains that challenge existing search algorithms can assist in the development of more robust search algorithms that can avoid certain pitfalls of existing algorithms. Additionally, mazes are widely understood and have efficient state changes, which can allow for more algorithm based examinations in the future. I would like to develop a system for rating the “hardness” of a given maze, as well as creating a maze generation algorithm that can generate mazes that have a higher or lower “hardness” rating.
Idea 2 : Cave Generation Using Cellular Automata
I would like to experiment with using cellular automata to generate cave structures. This has applications in procedural level generation for video games, artistic potential, and depending on the techniques used, it could also be useful in real world geological simulations. There has already been some work done in the area which gives ample room for extension and exploration. Most of the materials seem to be focused on 2D maze generation, so it may be fruitful to focus on generating 3D structures, or extending the existing techniques from 2D CA to 3D.
Idea 3 : Origami Crease Pattern Generation Tool
I would like to build an application that generates an origami crease pattern from a 3D model, with a stretch goal being to implement 3D scanning from a camera. Folding techniques used in origami are seeing more and more uses in engineering contexts. The new Webb telescope for instance used origami for its heat shield and mirrors. Being able to generate crease patterns based on a source model may allow for more widespread use of similar techniques. This project will involve image analysis and potentially machine learning.
Maze generation and solving:
Web application security:
Pitch #1
We all at some point have received that suspicious message stating that we are being watched or an annoying pop up in which insists that our devices are riddled with virus’s. I seek to find out how often and by what measure are people being trully attacked on there smart devices. As many smart devices do not offer robust cyber security systems they are more vulnerable to attack than other devices like computers. This software will provide an insight into the presence of hackers and malware on smart devices gathering data on the types of attacks to be wary of.
Pitch #2
New technologies have been evolving to aid life within the home. Video door bells, cameras and smart devices make many tasks much simpler than they use to be. However, the threat of security and ensuring that those with malicious intent are unable to hack and harm your home network has also increased, a failure in security could expose all of your personal information. As a result of this many organizations provide VPN services that have been developed as a means to protect people from the dangers of malicious hackers and malware. However, these same VPNS come with some faults such as higher cost and limitations as dictated by the provider , and the fact that paid services place you in the hands of the operator and its various cloud/network providers with no certainty that these providers will not snoop around in your data.
A VPN server that a user can host on there local machine solves all of these aforementioned problems with the added benefit of the user being able to securly access and maintain there home network.The server will be held in a virtual machine and will allow the user to be in complete control of it and its functions. This will increase efficiency of the VPN as the user no longer has to go through the network of the provider. My goal is to automate and open-source this process creating an easy launchable VPN server an average user can easily launch and use to maintain access to their home network.While at the same time being capable being edited and changed by the user for more robust security. I seek to compare this to similar paid services identifying which is more secure for the user.
Pitch #3
Many have been contacted by a scam caller and while most have the common sense to recognize the scam being played, thousands of Americans fall victim to such scams and end up paying a huge price for there mistake. While many assume these numbers mainly stem from the elderly, research has shown that people likey to fall for scams are broad in age group with the elderly being scammed for more money and the youth being scammed more frequently. To address this issue I seek to create a real time speech and text recognition answering bot that is capable of answering on phone calls from unknown numbers and through certain verbal ques will be able to deduce weather or not the person on the other end is scammer or not. With this bot I will be able to gather data on the most common types of scams and improve upon existing scam blocker software.
ABSTRACT:
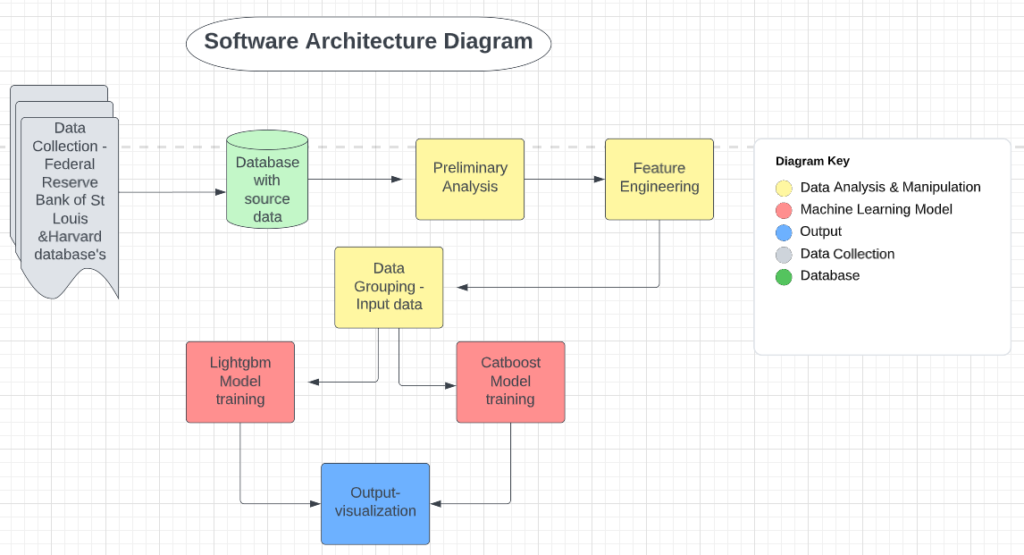
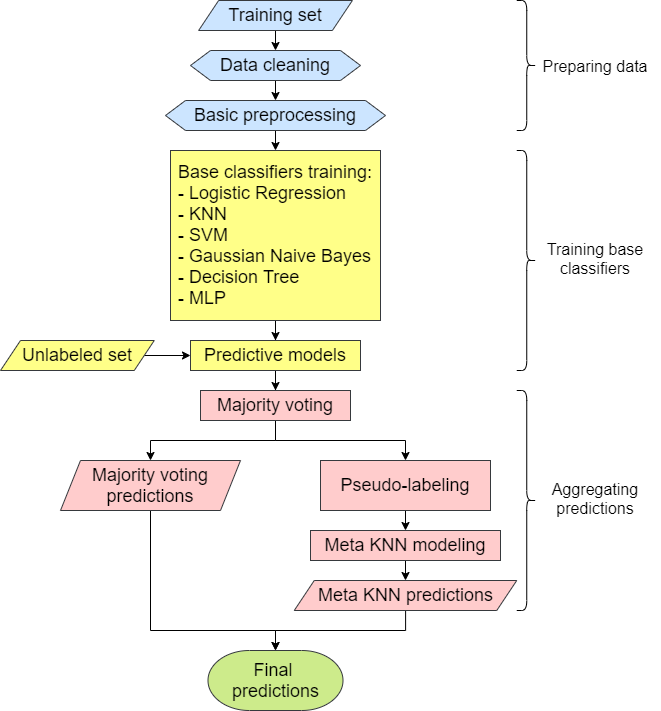
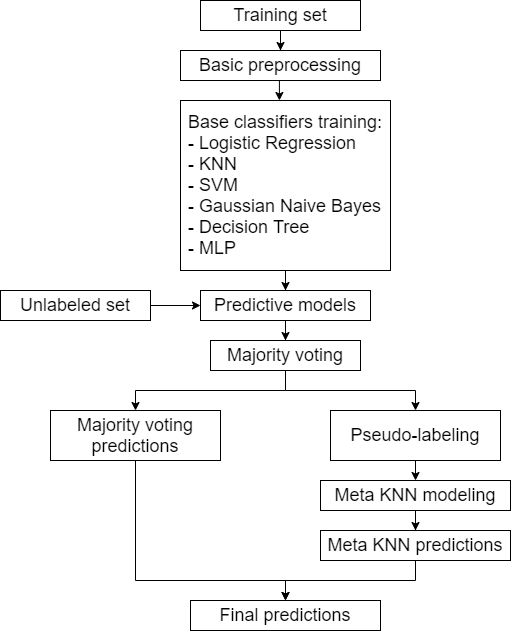
Voting is an important Ensemble Learning technique. However, there has not been much discussion about leveraging the base classifiers’ consensus on unlabeled data to better inform the final prediction. My proposed method identifies the data points where the ensemble reaches consensus and where conflict arises in the unlabeled space. A meta weighted KNN model is trained upon this half-labeled set with the labels of the consensus and the conflict points marked as “Unknown,” which is treated as a new, additional class. The predictions of the meta model are expected to better inform the decision of the ensemble in the case of conflict. This research project aims to implement my proposed method and evaluate it on a range of benchmark datasets.
SOFTWARE ARCHITECTURE DIAGRAM:
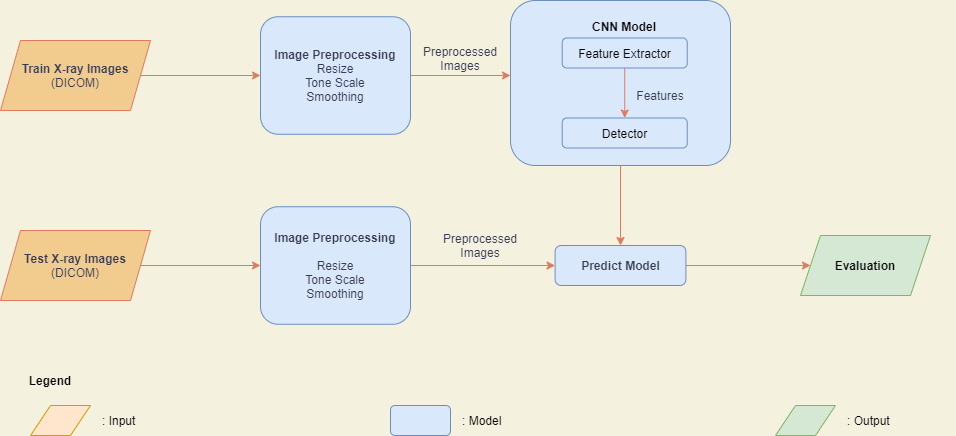
Navigating chest X-rays is an obligatory step to determine lung and heart diseases. Since many people now believe that Chest X-ray radiographs can detect COVID-19, the disease of the decade, the problem of Chest X-ray Abnormalities Detection has gained increasing attention from researchers. Numerous machine learning algorithms have been developed to address this problem to raise reading accuracy, improve efficiency, and save time for both doctors and patients. In this work, I propose a model to determine whether a Chest X-ray image has Infiltration and to detect the abnormalities in that image using YOLOv3. The model will be trained and tested with the VinBigData dataset. Overall, I will use the existing tool, YOLOv3, on a new problem of detecting Infiltration in Chest X-ray radiographs.
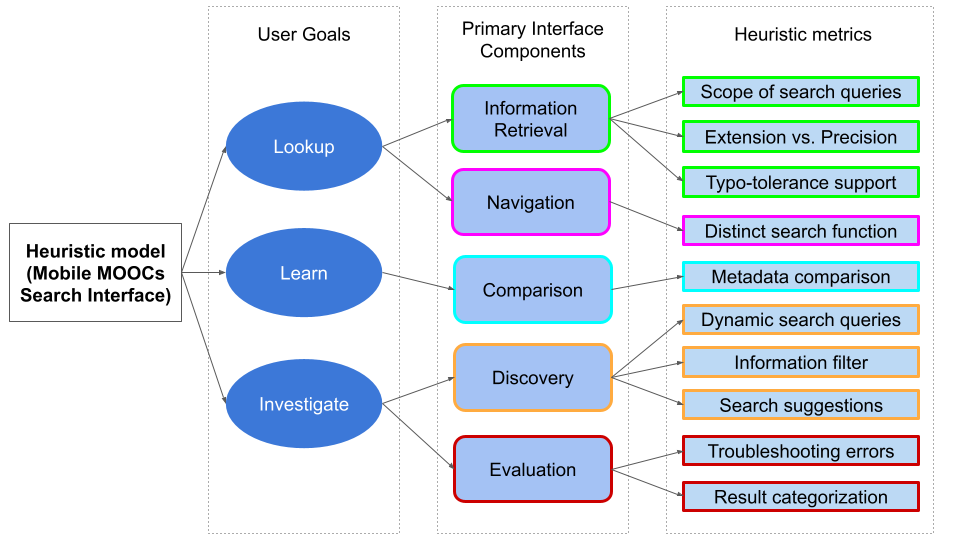
Heuristic evaluation is one of the most popular methods for usability evaluation in Human-Computer Interaction (HCI). However, most heuristic models only provide generic heuristic evaluation for the entire application as a whole, even though different parts of an application might serve users in different contexts, leading HCI practitioners to miss out on context-dependent usability issues. As a prime example, mobile search interfaces in e-learning applications have not received a lot of attention when it comes to usability evaluation. This paper addresses this problem by proposing a more domain-specific and context-dependent heuristic evaluation model for search interfaces in mobile e-learning applications. I will analyze studies on mobile evaluation heuristics, in combination with research in mobile search computing and e-learning heuristics, to generate a heuristic model for mobile e-learning search interfaces.
https://drive.google.com/file/d/17a4p9N_OzE-O7VrwpSl7a9cbAI4Lx_25/view?usp=sharing
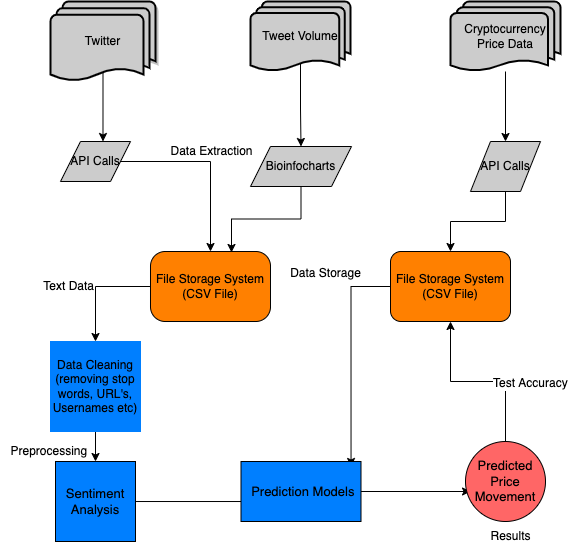
Predicting cryptocurrency price movements is a well-known problem of interest. In this modern age, social media represents the public sentiment about current events. Twitter especially has attracted a lot of attention from researchers who are studying the public sentiments. Recent studies in natural language processing develop automatic techniques in analyzing sentiment in social media information. This research is directed towards predicting volatile price movement of cryptocurrency by analyzing the sentiment on social media and finding the correlation between them. Machine learning algorithms including support vector machine and linear regression will be used to predict the prices. The most efficient combination of machine learning algorithms and the datasets being used will be determined.
Software Architecture Diagram
Link to video tutorial: https://youtu.be/ml4Tc-Xr7bc
Link to senior paper: https://drive.google.com/file/d/1S2TUrBGu8VMmVX1iES8osTWCS6J3PfOG/view?usp=sharing
Pitch 1 – Develop an API for Sensor
I was hoping to work with sensors to develop an interface/app that would be more useful for
individuals’ projects. Say there was this sensor that measured water quality that was inexpensive,
but pretty rudimentary and it doesn’t really have a good API already, I could make an app that
would work with that for individuals who are students or just wanting to do small experiments
with water qualities nearby their house or school. I would work with programming and
interfacing with the hardware sensor. I’m not entirely sure of the dataset I would use or need for
this. I could use one that is already present to work on different graphing techniques in the API.
Pitch 2 – Research into Feasibility and Practicality of Low-Cost Portable Air Quality Sensor and Network with Smartphone Connection
Similar to the sensor pitch I did before, this would be working with air sensors that could be put
into a compact container that would be attached to someone. The sensors would be built into an
Arduino, Charlie said he would show me some sensors and how to use the Arduino sometime
this week when he is back on campus. The air sensors would constantly read for different
dangerous compounds in the air and would notify the user through a smartphone app and track
different amounts in different places. The sensor would not track location, but the app on the
phone would because the sensor would probably be connected to the phone through Bluetooth or
some other possible wireless connection and therefore have to be near the phone to work. This
would be very useful for emergency responders and for maintenance people who work with
boilers and furnaces.
Pitch 3 – Land-Based Oil Spill Modeling
I was thinking about doing something within the realm of climate change simulations. Maybe
something along the lines of the damages of an oil pipeline bursting and then being carried
inland by a flood that was caused by excess rainfall due to climate change. Or perhaps a wildfire
simulation or smoke pollution simulation from said wildfires. This would just help to get an idea
of how we could mitigate these catastrophes while the risk is still present. It would require a lot
of machine learning and GIS information
Idea 1: Detect and predict mental health status using NLP
The objective of that research is to determine whether NLP (Natural Language Processing) is useful for mental health treatment. Data sources vary from traditional sources (EHRs/EMRs, clinical notes and records) to social sources (tweets and posts from social media platforms). The main subject for data will be the social media posts because they enable immediate detection of users’ possible mental illness. They are preprocessed by extracting the key words to form an artificial paragraph that contains only numbers and characters. Then, an NLP (Natural Processing Language) model, built on genuine and artificial data, will test the real (raw/original) data and compare with the artificial paragraph above. The outputs will be the correct mental health situation from the patients after the testing.
Libraries such as Scikit and Keras are frequently used in a lot of papers. The dataset I would like to experiment is the suicide and depression dataset from Reddit posts starting at \r.
Idea 2: Using Machine Learning Algorithms to predict air pollution
Machine Learning algorithms can predict air pollution based on the amount of air pollutant in the atmosphere, which is defined by the level of particulate matters (we will look at PM2.5 – the most dangerous air pollutant to human’s health – specifically). Given a data indicating PM 2.5 level in different areas, that data has to be preprocessed. Then, it will undergo several machine learning models, notably random forest and linear regression due to their simplicity and usage for regression and classification problems, to produce the best model for forecasting the presence of PM 2.5 level in the air.
Python and its library Scikit are the most common tools to train models. For this idea, I would like to select a dataset to measure air quality of 5 Chinese cities and it is available on Kaggle.
Idea 3: Machine Learning in music genre classification
Given an input (dataset) of thousands of songs from different genres such as pop, rock, hip hop/rap, country, etc, the audio will be processed by reducing/filtering noise and the soundwave. Then, the neural network model will take those audio inputs and images of their spectrograms to differentiate several objects as their neural network outputs. Eventually, the KNN method, due to its simplicity and robust with large noisy data, will test the music from the model outputs and classify the songs into their respective genres.
Python is mostly involved in the research due to the wide range of usage of its dynamic libraries such as Keras, Scikit, Tensorflow, and even Numpy that support the findings. This idea, I would like to choose Spotify dataset thanks to its rich collection of songs.
Pitch 1
Social media sentiments to predict mental health of people during the stages of pandemic in the United States
Pitch 2
Social media sentiments to predict the covid situation and vaccine rollout in different countries
Predicting the tourist volume and touristic behavior with search engine data
Resources:https://www.sciencedirect.com/science/article/abs/pii/S2211973617300570
Cryptocurrency price prediction
This would predict crypto currency prices using deep learning. As cryptocurrency popularity is increasing in the modern age and the money flow is increasing this is making cryptocurrencies more volatile and the patterns are changing. Some of the problems faced are as unlike the stock market cryptocurrencies are dependent on factors such as its technological progress and internal competition etc. I plan to get data from news agencies about specific tokens and also data of all the price changes in crypto from 2012 to predict the future prices. As per my research this would require the use of LSTM neural networks. Some of the many places this data can be found is on Cryptocompare API: XEM and IOT historical prices in hour frequency, Pytrends API: Google News search frequency of the phrase “cryptocurrency”, Scraping redditmetrics.com: Subreddit “CryptoCurrency,” “Nem,” and “Iota” subscription growth. We can predict the price by Identifying the Cointegrated Pair. This is a popular method used to stationarize time series. It can be used to remove trends and seasonality. Taking the difference of consecutive observations is used for this project.
Gender and age detection using deep learning
This would predict the age and gender of a person using a picture of a person or live view using a webcam. The predicted gender may be one of ‘Male’ and ‘Female’. It is very difficult to accurately guess an exact age from a single image because of factors like makeup, lighting, obstructions, and facial expressions.I will be using the Adience dataset; the dataset is available in the public domain. This dataset serves as a benchmark for face photos and is inclusive of various real-world imaging conditions like noise, lighting, pose, and appearance. As there are already multiple studies done on this topic, factors which affect the efficiency of the program can be worked on.
Forest fire detection using k-clustering
This model would detect forest fires using the Keras Deep Learning library. As seen recently around the world in places such as the Amazon rainforest and a prominent part of Australia, wildfires are increasing in this era. These disasters are damaging to the ecosystem like damaging habitat and releasing carbon dioxide. This project can be built using k-means clustering. This model would be able to identify any forest fires hotspots along with the intensity of the fire at that particular spot which would result in either the model detecting if it’s a wildfire or not. There is another way of making this using the neural network MobileNet-V2 or U-net which is more efficient and I will be researching more on this. There is a data set compiled with over 1300 images that would be used to detect wildfires. The data for this project can be found at https://drive.google.com/file/d/11KBgD_W2yOxhJnUMiyBkBzXDPXhVmvCt/view.
Hyperparameter Tuning is an important step in building a strong Machine Learning model. However, that the hyperparameter space grows exponentially and the interaction among the hyperparameters is often nonlinear limits the number of feasible methods to come up with a more optimal set of hyperparameters. I plan to examine some of the most common methods that are often used to tackle this problem and compare their performance:
To many people’s surprise, the Random brute-force technique sometimes outperforms the Grid Search method. My project aims to verify this claim by applying the techniques above to a range of benchmark datasets and prediction algorithms.
This is another Voting ensemble scheme. We pick out the classifier that performs the best under conflict and give it the role of the referee to solve “dispute” among the classifiers. The same principle can be used for breaking ties but we can also try removing the classifier that performs the worst under conflict.
We can try out a diverse set of classification algorithms like Decision Tree, Support Vector Machine, KNN, Naive Bayes, Logistic Regression, etc. and run them on the benchmark datasets from UCI. This proposed voting scheme can then be compared against the more common Simple Majority Voting Ensemble approach in terms of accuracy and other performance metrics.
Author/Researcher: Yujeong (Erin) Lee
Take a look at the project on Gitlab: https://code.cs.earlham.edu/elee17/capstone-cuneiform-image-processing.
Watch the software demonstration on Youtube: https://youtu.be/XKweV6jdfxs
Read the paper on Google Drive: https://drive.google.com/file/d/1FbfkI6wKPajhWrgkG2fCWU6BwHKeuqrM/view?usp=sharing
Ancient Near Eastern cuneiform tablets document one of the earliest writing systems known. Extensive collections of cuneiform tablets are in the process of being digitized by many institutions worldwide in an effort to make the digitized inscriptions available to remote researchers. With an increasing demand for digitization in the museum sector, this project addresses the ineffectiveness of manual image processing and aims to contribute to ancient Near Eastern studies with automated image processing of cuneiform tablets.
Manually, a six-sided tablet is scanned on each side on a flatbed scanner and sent for post-production, in which the images are digitally enhanced and stitched in the form of a “fatcross” using programs like Photoshop. Automation of such image processing will include 1) preparation of the image data, 2) image segmentation with methods like thresholding, and 3) accurate assembly of separate images. This research aims to identify a simple and effective edge detection method and its implementation parameters to automate building a fatcross.

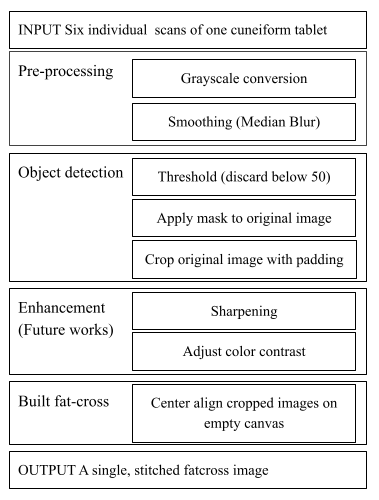
Abstract
For Twitter, a hashtag recommendation system is an important tool to organize similar content together for topic categorization. Much research has been carried out on figuring out a new technique for hashtag recommendation, and very little research has been done on evaluating the performance of different existing models
using the same dataset and the same evaluation metrics. This paper evaluates the performance of different content-based methods(Tweet similarity using hashtag frequency, Naïve Bayes model, and KNN-based cosine similarity) for hashtag recommendation using different evaluation metrics including Hit Ratio, a metric recently created for evaluating a hashtag recommendation system. The result shows that Naive Bayes outperforms other methods with an average accuracy score of 0.83.
Software Architecture Diagram
Pre-processing Framework
Evaluation Model
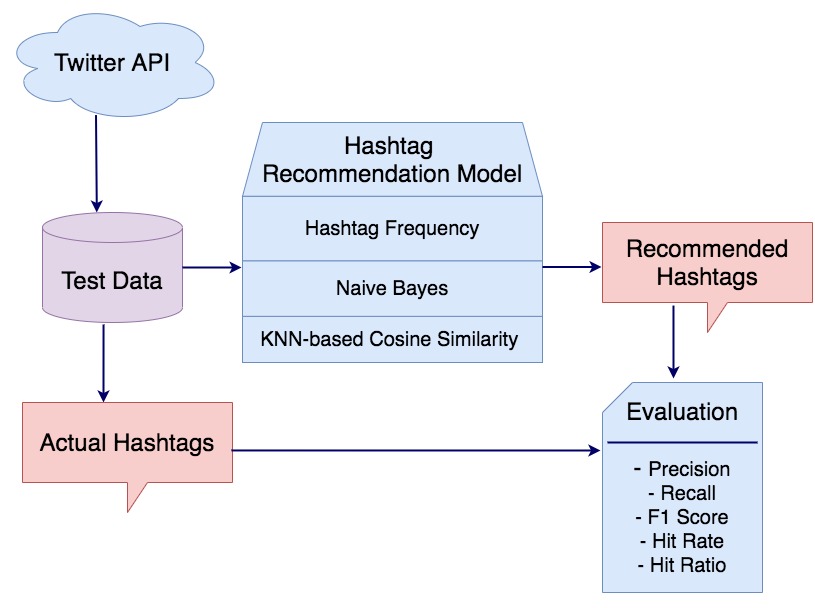
Evaluation Results
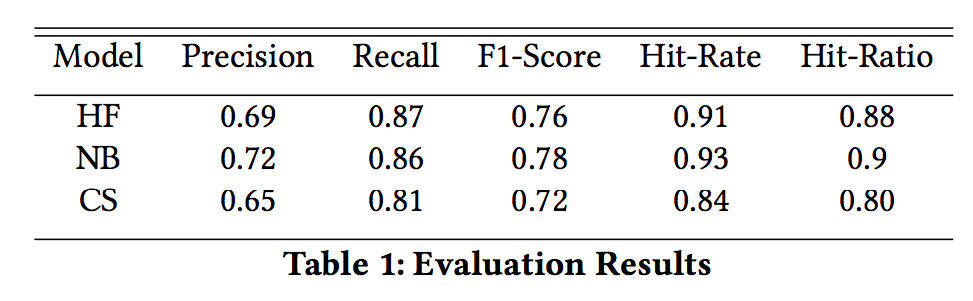
Design of the Web Application
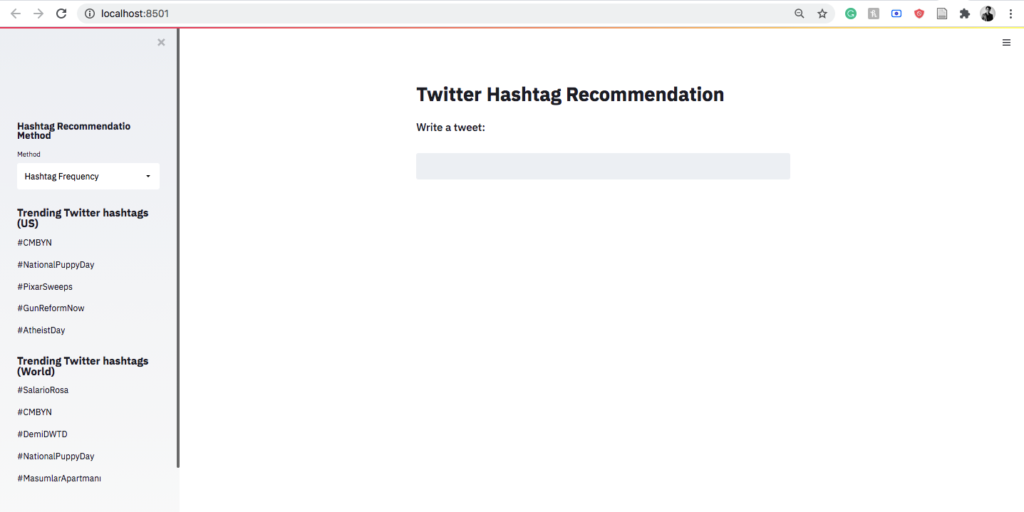
Abstract
Artificial Intelligence (AI) has been used extensively in the field of medicine. More recently, advanced machine learning algorithms have become a big part of oncology as they assist with detection and diagnosis of cancer. Convolutional Neural Networks (CNN) are common in image analysis and they offer great power for detection, diagnosis and staging of cancerous regions in radiology images. Convolutional Neural Networks get more accurate results, and more importantly, need less training data with transfer learning, which is the practice of using pre-trained models and fine-tuning them for specific problems. This paper proposes utilizing transfer learning along with CNNs for staging cancer diagnoses. Randomly initialized CNNs will be compared with CNNs that used transfer learning to determine the extent of improvement that transfer learning can offer with cancer staging and metastasis detection. Additionally, the model utilizing transfer learning will be trained with a smaller subset of the dataset to determine if using transfer learning reduced the need for a large dataset to get improved results.
Software architecture diagram
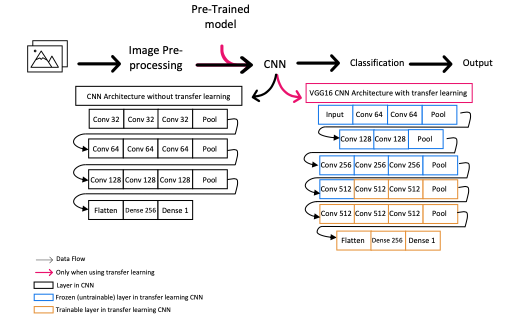
Links to project components
Link to complete paper:
Link to software on gitlab: https://code.cs.earlham.edu/afarah18/senior-cs-capstone
Link to video on youtube: https://www.youtube.com/watch?v=G01y0ZLKST4
Link to copy of poster:
Abstract
Writer identification based on handwriting plays an important role in forensic analysis of the documents. Convolutional Neural Networks have been successfully applied to this problem throughout the last decade. Most of the research that has been done in this area has concentrated on extracting local features from handwriting samples and then combining them into global descriptors for writer retrieval. Extracting local features from small patches of handwriting samples is a reasonable choice considering the lack of big training datasets. However, the methods for aggregating local features are not perfect and do not take into account the spatial relationship between small patches of handwriting. This research aims to train a CNN with triplet loss function to extract global feature vectors from images of handwritten text directly, eliminating the intermediate step involving local features. Extracting global features from handwriting samples is not a novel idea, but this approach has never been combined with triplet architecture. A data augmentation method is employed because training a CNN to learn the global descriptors requires a large amount of training data. The model is trained and tested on CVL handwriting dataset, using leave-one-out cross-validation method to test the soft top-N, hard top-N performance.
Software Architecture
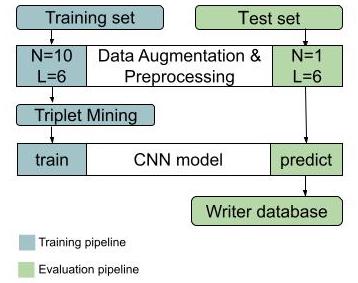
I’m using CVL writer database to train the model. All handwriting samples go through the data augmentation and pre-processing step to standardize the input for CNN. The samples in the training set get augmented, whereas only one page is produced per sample for the test set. The triplets of samples are chosen from each batch to train the CNN. The output of the CNN is a 256D vector. In order to evaluate the model, we build a writer database for samples in the test set.

Each handwriting sample goes through the same set of steps:
1. Original handwriting sample.
2. Sample is segmented into words.
3. The words from a single sample are randomly permuted into a line of handwriting. The words are centered vertically.
4. Step 2 is repeated L times to get L lines of handwriting. These lines are concatenated vertically to produce a page.
5. A page is then broken up into non-overlapping square patches. The remainder of the page is discarded. The resulting patches are resized to 224×224 pixels.
6. Steps (4) and (5) are repeated N times.
7. Finally we apply binarization. The patches are thresholded using adaptive Gaussian Thresholding with 37×37 kernel.
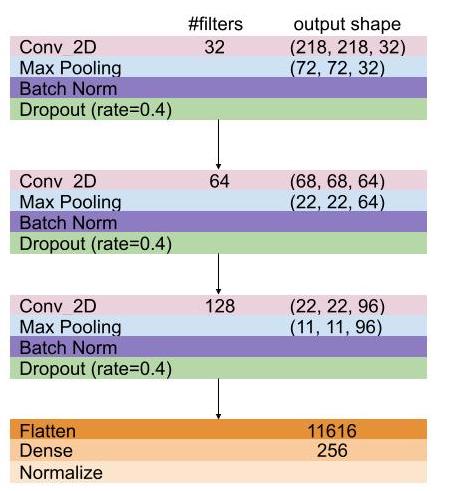
The CNN model consists of 3 convolutional blocks followed by a single fully connected layer. Each convolutional block includes a 2D convolutional, batch normalization, max pooling and dropout layers. The final final 256D output vector is normalized. I implemented this CNN framework in keras with tensorflow backend.
The model was trained for 15 epochs with batch gradient descend and Adam optimizer, with an initial learning rate of 3e-4. 10 epochs of training with semi-hard negative triplet mining was followed by 5 epochs of hard negative triplet mining.
CS488: Senior Capstone Project
-Muskan Uprety
Stock Prediction, Sentiment Analysis, Stock Price Direction, Social Media Sentiment
Due to the current pandemic of the COVID-19, all the current models for investment strategies that were used to predict prices could become obsolete as the market is in a new territory that has not been observed before. It is essential to have some predictive and analytical ability even in times of a global pandemic as smart investments are crucial for securing the savings for people. Due to the recent nature of this crisis, there is limited research in tapping predictive power of market sentiment when a lot of people are deprived from extracurricular activities and thus have turned their focus in capital markets. This research finds that there is evidence of market sentiment influencing stock prices. Adding market sentiment to the classification improved the prediction power of the model as compared to just price and trend information. This shows that sentiment analysis can be used to make investment strategies as it has influence over the price movements in the stock market. This research also finds that looking at the sentiment of posts up to one hour into the past yields the best predictive abilities in price movements
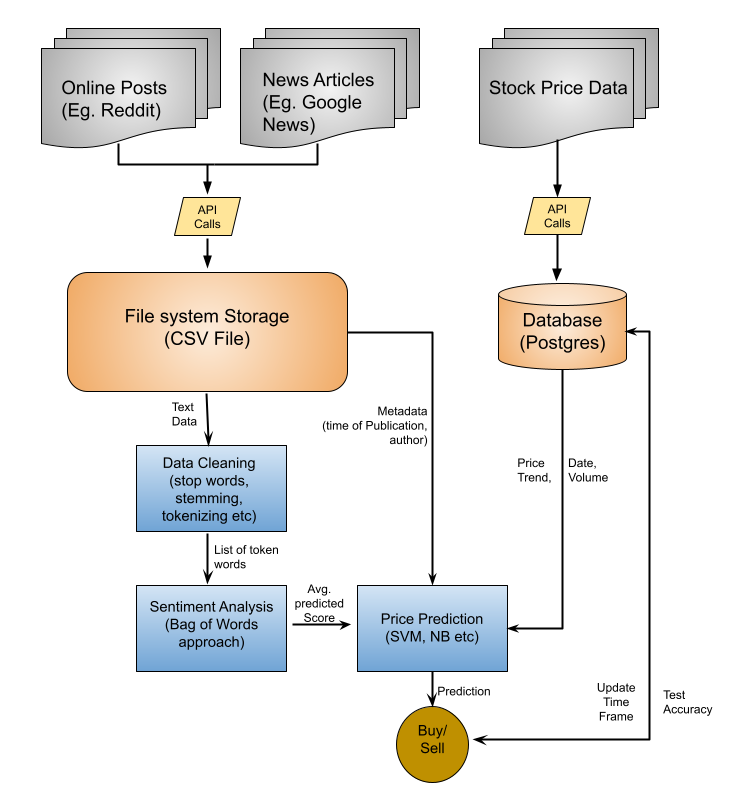
Figure 1. Software Architecture DiagramLink to Paper: Paper
Link to Source Code: GitLab
Link to Demonstration Video: YouTube
Link to Poster: Poster
Stock Price Prediction using Online Sentiment
Stock Price Prediction using Online Sentiment
Muskan Uprety Department of Computer Science Earlham College Richmond, Indiana, 47374 muprety17@earlham.edu
KEYWORDS
Stock prediction, sentiment analysis, price direction prediction
.
1 ABSTRACT
Due to the current pandemic of the COVID-19, all the current mod- els for investment strategies that were used to predict prices could become obsolete as the market is in a new territory that has not been observed before. It is essential to have some predictive and analytical ability even in times of a global pandemic as smart invest- ments are crucial for securing the existence of savings for people. Due to the recent nature of this crisis, there is limited research in tapping predictive power of various sectors in these unique times. This proposal aims to use texts from online media sources and analyze of these texts hold any predictive powers within them. The proposed research would gather the population sentiment from the online textual data during this pandemic and use the data gathered to train a price prediction model for various stocks. The goal of this research is to check if the prediction model can help make investment strategies that outperforms the market.
2 INTRODUCTION
The unpredictability of stock prices has been a challenge in the Finance industry for as long as stocks have been traded. The goal of beating the market by stockbrokers and experts of the industry have not been materialized, however, the availability of technological resources has certainly opened a lot of doors to experimenting different approaches to try and fully understand the drivers of stock prices. One of the approaches that have been used extensively to try and predict price movements is Sentiment Analysis. The use of this tool is predicated on the fact that stakeholder’s opinion is a major driving force and an indicator for future prices of stock prices. Indicators can be of two types: those derived from textual data (news articles, tweets etc.), and those derived from numerical data (stock prices) [5].
Our research would focus on the textual data derived from sources like Twitter and online news media outlet to analyze if the sentiments in those texts can be used to make price movement predictions in short or long term. It is very important to have some analytical capabilities, specially during and after the COVID-19 pandemic as the outbreak has caused the entire world to be in a shutdown closing businesses indefinitely and burning through peo- ple’s savings. Some panic among consumers and firms has distorted
,,
© 2021
usual consumption patterns and created market anomalies. Global financial markets have also been responsive to the changes and global stock indices have plunged [10].The effect of this disease has created a lot of shifts in the financial industry, along with in- crease in volatility and uncertainty. Due to the pandemic being so recent and ongoing, there is a lack of research on what factors are responsible for the high level of variance and fluctuations in the stock market. While there are papers that analyzes sentiment in text to predict price movements, the applicability of those models in context of a global pandemic is untested. It is vital to be able to have some predictive ability in the stock market as succumbing solely to speculation and fear could result in devastating loss of wealth for individual consumers and investors. The goal of this research is to :
• be able to predict human sentiment from social media posts, • use sentiment to predict changes in price in the stock market • recommend investors to buy, sell, or hold stocks based on
our model
• beat a traditional buy and hold investment strategy.
This paper will first discuss some of the related work that was analyzed in making decisions for algorithms and data to use. After brief discussions about the models to be used in the research, the paper discusses the entire framework of the paper in detail and also discusses the costs associated with conducting this research if any. Finally, the paper proposes a timeline in which the research will be conducted and ends with the references used for this proposal.
3 RELATED WORK
The entire process of using sentiment to predict stock price move- ment is divided into two parts. The first is to to extract the sentiment from the text source using various algorithms, and the second step is to use this information as an input variable to predict the move- ment and direction of the different stocks’ price. various researchers have used different algorithms and models for each of this process. The difference in model is based on the overall goal of the research, the type of text data used for analysis, input parameters used for classifier, and the type of classification problem considered.
3.1 Sentiment analysis
The process of conducting sentiment analysis requires some form of text data that is to be analyzed, and some labels associated with these textual data that allows the model to distinguish if a collection of text is positive or negative in nature. It is quite difficult to find a data set that has been labelled by a human to train the model to make future predictions. Various researchers have used different measures to label their text data in order to train a model to predict
, ,
Muskan Uprety
whether an article or tweet is positive or negative (or neutral but this is not very relevant).
There are a few approaches used by researchers to train their sentiment analysis model. Connor et al. uses a pre-determined bag of words approach to classify their texts [12]. They use a word list which consists of hundreds of words that are determined positive or negative. If any word in the positive word list exists in the text, the text is considered as positive and if any word in the negative word list exists in the text, it is considered negative sentiment. In this approach, an article or tweet can be considered both positive and negative sentiment.
Gelbukh also uses a similar approach of using a bag of words to analyze sentiment [4]. Instead of having pre-determined set of positive and negative word list, they look at the linguistic makeup of sentences like the position of opinion or aspect words in the sentence, part of speech of opinions and aspects and so on to deduce sentiment of the text article.
In the absence of a bag of words for comparison, Antweiler and Frank manually labelled a small subset of tweets into a positive (buy), negative (sell), or neutral (hold classification [1]. Using this as reference, they trained their model to predict the sentiment of each tweet they had into one of these three categories. The researchers also noted that the messages and articles posted in various messaging boards were notably coming from day traders. So although the market price of stocks may reflect the sentiment from entire market participants, the messaging boards most certainly aren’t.
While most researchers looked for either pre-determined bag of words or manually labelled data set, Makrehchi et al automated labelling the text documents [9]. If a company outperforms expec- tations or their stock prices goes higher compared to S&P 500, they assume that the public opinion would be positive and negative if prices go lower than S&P500 or under performs than expectations. Each tweet is turned into a vector of mood words where the column associated with the mood word becomes 1 if the word is mentioned in the tweet and 0 if it isn’t. This way, they train their sentiment analysis model with automated labels for tweets.
3.2 The Prediction Model
All the papers discussed in this proposal use the insights gained from text data collected from various sources. However, the ultimate goal is to check if there is a possibility to predict movement in stock market as a result of such news and tweets online. And researchers use different approaches to make an attempt at finding relationships between online sentiment and stock prices, and they are discussed in this section.
Markechi et. al. collected tweets from people just before and after a major event took place for a company [9]. They used this information to label the tweets as positive or negative. If there was a positive event, the tweets were assumed to be positive and negative if there was a significant negative event. The researchers use this information to train their model to predict the sentiment of future tweets. Aggregating the net sentiment of these predicted tweets, they make a decision on whether to buy, hold, or sell certain stocks. Accounting for weekends and other holidays, they used
Table 1: Papers and Algorithms Used
Papers
Makrehchi et al. [9] Nguyen and Shirai [11] Atkins et al. [2] Axel et al. [6] Gidofalvi [5]
Algorithm Discussed
time stamp analysis TSLDA
LDA
K mean clustering Naive Bayes
this classification model to predict the S&P 500 and were able to outperform the index by 20 percent in a period of 4 months.
Nguyen and Shirai proposed a modified version of Latent Dirich- let Allocation (LDA) model which captures topics and their senti- ments in texts simultaneously [11]. They use this model to assess the sentiments of people over the message boards. They also label each transaction as up or down based on previous date’s price and then use all these features to make prediction on whether the price of the stock in the future will rise or fall. For this classification problem, the researchers use the Support Vector Machine (SVM) classifier which has long been recognized as being able to efficiently handle high dimensional data and has been shown to perform well on many tasks such as text classification [4].
Atkins et. al. used data collected from financial news and used the traditional LDA to extract topic from each news article [2]. Their reasoning of using LDA is that the model effectively reduces features and produces a set of comprehensible topics. Naïve Bayes classifier model follows the LDA model to classify future stock price movements. The uniqueness of this research is that it aims to predict the volatility in prices for stocks instead of trying to predict closing stock prices or simply the movement. They limit their prediction to 60 minutes after an article gets published as the effect of news fades out as time passes.
Axel et. al. collected tweets from financial experts, who they de- fined as people who consistently tweet finance related material, and then used this set of data for their model [6]. After pre-processing the data and reducing dimensions of the data, they experimented with both supervised and unsupervised learning methods to model and classify tweets. They use K mean clustering method to find user clusters with shared tweet content. The researchers then used SVM to classify the tweets to make decisions on buying or selling a stock.
Gidófalvi labelled each transaction as up or down based on pre- vious day pricing [5]. They also labelled articles with the same time frame with similar labels. That is, if a stock price went up, articles that were published immediately before or after also were labelled as up. They then trained the Naïve Bayes text classifier to predict which movement class an article belonged to. Using this predicted article in the test dataset, they predicted the price movement of the corresponding stock. The researchers, through experimentation, found predictive power for the stock price movement in the inter- val starting 20 minutes before and ending 20 minutes after news articles become publicly available.
In terms of classifying text from online media, there was two typed of approaches generally used by researchers. [5] and [9] have used the approach of classifying a text as positive if the text
Stock Price Prediction using Online Sentiment
, ,
was published around a positive event, and classified it as negative sentiment if it was published around the time of some negative event. Their method doesn’t actually look at the contents of the text but rather the time the text was published in. On the other hand, [2] [6] and [11] ,as one would expect, looks inside the text and analyze the contents to classify on whether the authors of these texts intended a positive or negative sentiment. Although algorithms like the LDA or the modified version discussed in [11] are the more intuitive approaches, the fact that classifying texts based on time also yields good results makes me think if reading the text and using computational resources are actually necessary. In the other hand, researchers seem to consistently agree on using SVM as it is widely used in classification problems. Analyzing the various papers, we believe that SVM is the most effective classifier for this stock prediction problem. In the case of sentiment analysis, we believe that more experiments should be done to conduct a cost benefit analysis of actually reading the text for sentiment analysis versus the potential loss of accuracy by just analyzing the time stamp of an article’s publishing.
4 DESIGN
4.1 Framework
Figure 1: Prediction model framework
The framework of this project is shown in Figure 1. The entire project can be divided into two components. The first part is to use the text data collected from various news articles, messaging boards and tweets and create a sentiment analysis model that is able to extract the average sentiment for individual companies. After that, we use the information from this model to train a price prediction classifier which will predict the direction of the stocks prices. Based on this prediction, the overall output will be a recommendation of buy, sell or hold, which we will use to make investment decisions. The recommendation will be made based on predicted price, current price and purchase price. We will analyze the returns of investment strategies suggested my our model, and compare if our profitability would be better than simply investing and holding an index like the S&P 500.
4.2 Data Collection
In order to gather the sentiment from the entire market, we will diversify our sources of textual data. As Antweiler and Frank dis- covered, messaging board comments were heavily skewed towards day traders [1]; we assume the informal setting of Twitter suggests the input of more traditional and individual investors. We also want to include news articles to capture the sentiment of stakeholders that may have been omitted by the other platforms mentioned. In terms of stock prices, we are using Yahoo Finance which is being consistently used by other researchers to capture the stock prices across time. All of this data will be stored in a Postgres database management system
4.3 Capturing Sentiment
For the purpose of categorizing the text documents as positive and negative sentiments, we are going to compare the Rocchio Algo- rithm [13] and the Latent Dirichlect Allocation (LDA) model [3]. These are the two most discussed method and are the algorithms used by researchers to conduct binary classification of textual sen- timent.
After cleaning the data by eliminating non essential text data (filter texts using keywords), we will transform the data into the form needed by the models. Both these algorithms use a bag of word approach where we select a collection of words that are determined to be capturing sentiment in text. For Rocchio algorithm, each text is converted into a vector of words where we keep track of the frequency of words in the text and use this representation of text to predict sentiment. The basic idea of LDA, on the other hand, is that documents are represented as random mixtures over latent topics, where each topic is characterized by a distribution over words [3].
4.4 Price Prediction
Results generated from the Sentiment Analysis model will be used along with a few other input variables from text data to train a classifier which will allow us to make price prediction for individual stocks. For the price prediction model, decision tree [14], support vector machine (SVM) [7] and possibly the Naive Bias models [8] will be tested. We will compare these various models and analyze which model and algorithm produces the best outcome.
5 BUDGET
This project is primarily a python project with some integration of database management system. We intend to use Python pro- gramming, Postgres database management system, Django, and possibly some visualization tool like Tableau. All the computational resources and storage devices are available in Earlham. Since we do not require the purchase of any software, and we anticipate the data to be available online for no cost, there is no cost anticipated at this time.
6 TIMELINE
• week 1-3: finalize the data sources. Research the method/ process to extract data from sources.
• week4-5:ExtractthedatausingappropriateAPIandcreatea database to store the data. Request hardware resources from
, ,
Muskan Uprety
system admins. Have a clear idea of access and updating
database.
series. ICWSM 2010 – Proceedings of the 4th International AAAI Conference on
Weblogs and Social Media May (2010), 122–129.
[13] J. ROCCHIO. 1971. Relevance feedback in information retrieval. The Smart
Retrieval System-Experiments in Automatic Document Processing (1971), 313–323.
https://ci.nii.ac.jp/naid/10000074359/en/
[14] P.H.SwainandH.Hauska.1977.Thedecisiontreeclassifier:Designandpotential.
IEEE Transactions on Geoscience Electronics 15, 3 (1977), 142–147.
A final version of the paper can be found here.
A final version of the repository can be found here.
Demographic weighting was added, as was a file that turns Rhode Island into 3 districts. Unfortunately, Pennsylvania and Kentucky data was never added due to time constraints, and such has been noted. The paper has been updated to contain results and future work recommendations.
Detection of misinformation has become of great relevance and importance in the past few years. A significant amount of work has been done in the field of fake news detection using natural text processing tools combined with many other filtering algorithms. However, these studies lacked to observe any possible connection that might exist between the tone of the news and the validity of it. In order to research this field and find any existent correlation, my project addresses the potential role that sentiment associated with the news plays in identifying its validity. I perform sentiment analysis on tweets through natural language processing and use neural networks to train the model and test its accuracy.
With the increase in the number of forest fires worldwide, especially in the West of the United States, there is an urgent need to develop a reliable fire propagation model to aid fire fighting as well as save lives and resources. Wildfire spread simulation is used to predict possible fire behavior, which is essential in assisting fire management and training purposes. This paper proposed an agent-based model that simulates wildfire using a cellular automata approach. The proposed model incorporated a machine learning technique to automatically calculate the igniting probability without the need to manually adjust the input data for a specific location.
The program includes three large components: the input service, the simulation model, and the output service.
The input service processes users inputs. The input includes diffusion coefficient, ambient temperature, ignition temperature, burn temperature, matrix size, and a wood density data set. All of the inputs can be set to default values if users choose not to provide data. The wood density data set can also be auto-generated if a real-world data set is not provided.
The simulation model is the most important component of the program. This part consists of two main parts, fire temperature simulation service and the wood density simulation service. As the names suggest, the fire temperature simulation service is responsible for processing how fire temperature changes throughout the simulation process. The wood density simulation service is in charge of processing the changes in wood density of the locations described in the input when fire passes through.
The final component, the output service, creates a graph at each time step, and puts together the graphs into a gif file. By using the gif file, users can visualize how fire spreads given the initial inputs.
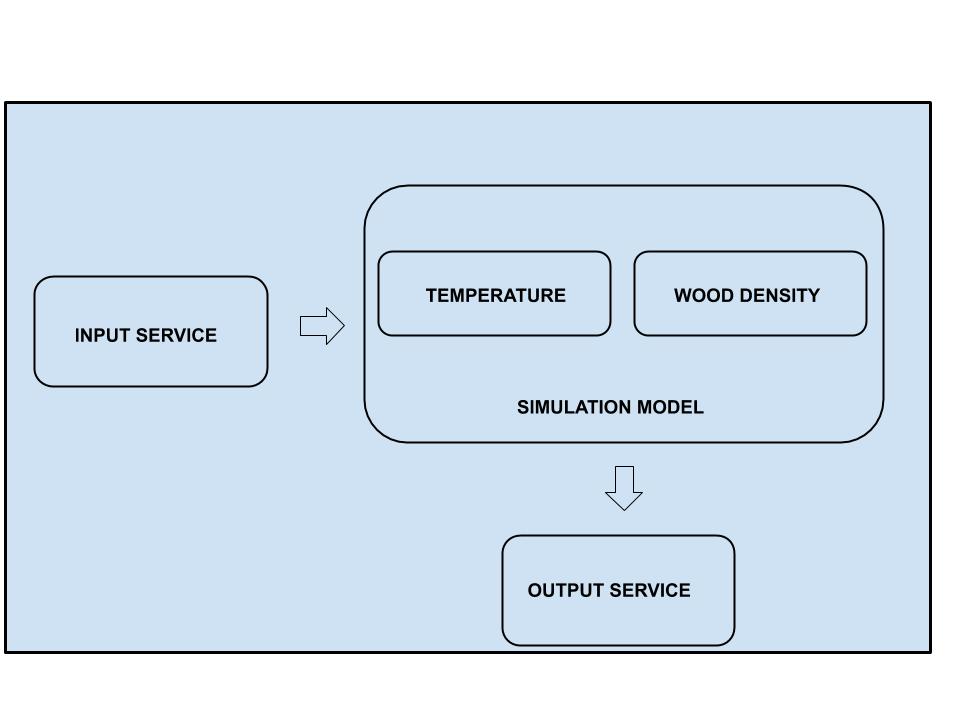
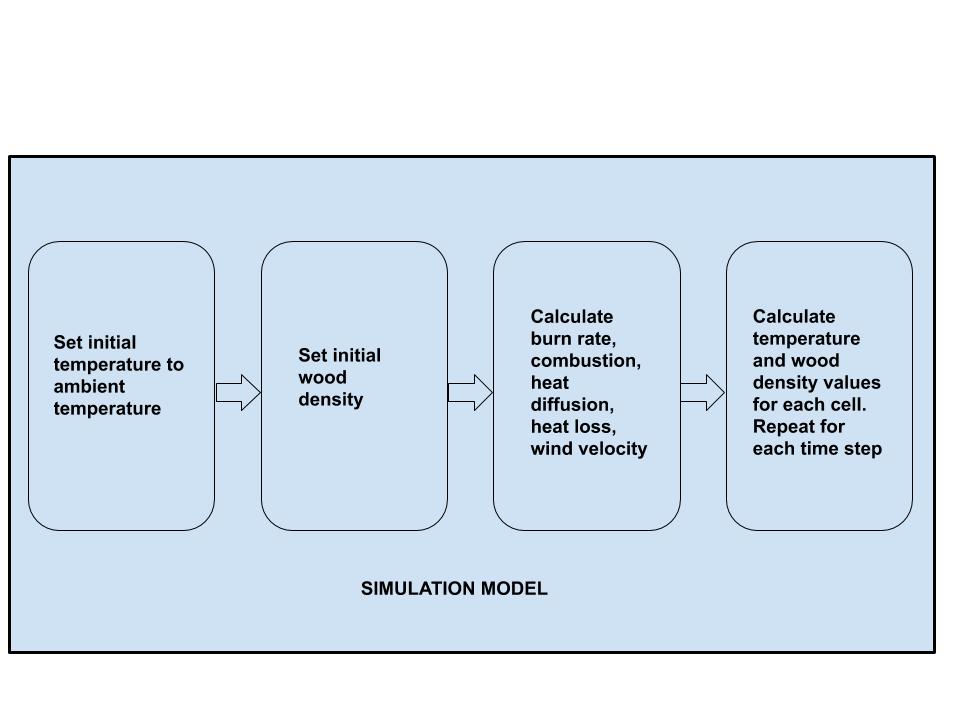
https://drive.google.com/file/d/1d4UQhkRWoYSxDWYb5SY-lca6QLaZFJMZ/view?usp=sharing
Over the last decade, researchers have come to realize that sarcasm detection is more than just another natural language task such as sentiment analysis. Problems like human error and longer processing times pertaining to sarcasm arise because previous researchers manually created features that would detect sarcasm. In an effort to limit these problems, researchers desisted from using the pre-crafted-feature-prediction models and turned to using neural networks to predict sarcasm. To understand sarcasm, one needs to have a bit of background information on the topic, common shared knowledge and also exist in the space in which the sarcastic statement exists. With this in mind, introducing visual aspects of a conversation would help improve the accuracy of a sarcasm prediction model.
Paper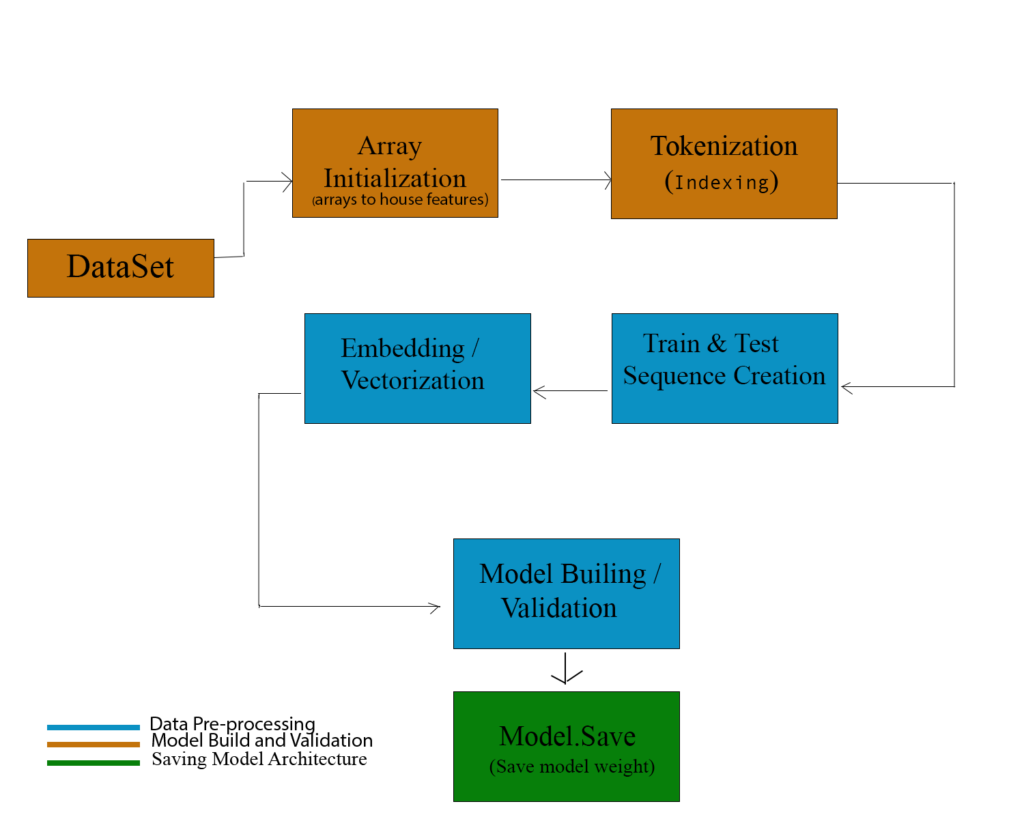
An ever-present problem in the world of politics and governance in the United States is that of unfairly political congressional redistricting, often referred to as gerrymandering. One method for removing gerrymandering that has been proposed is that of using software to create nonpartisan, unbiased congressional district maps, and there have been some researchers who have done work along these very same lines. This project seeks to be a tool with which one can create congressional maps while adjusting the weights of various factors that it takes into account, and further evaluate these maps using the Monte Carlo method to simulate thousands of elections to see how ‘fair’ the maps are.
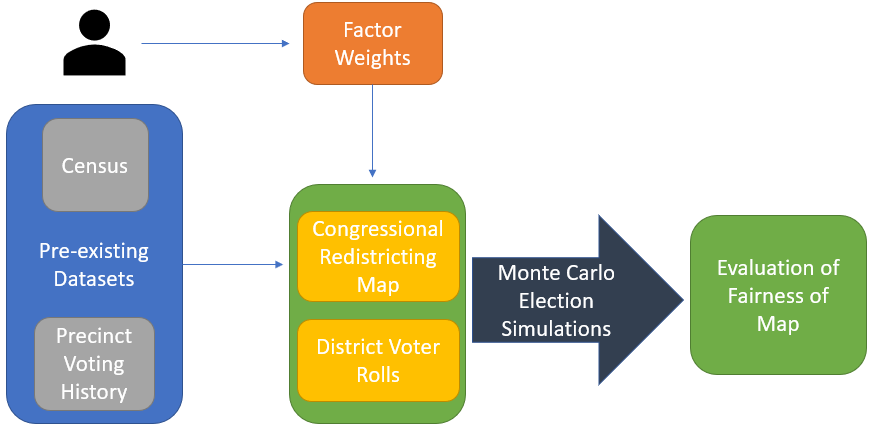
As shown in the figure above, this software will create a congressional district map based off of pre-existing datasets (census and voting history) as well as user-defined factor weighting, which then goes under a Monte Carlo method of simulating thousands of elections in order to evaluate the fairness of this new map. The census data is used both for the user-defined factor weighting and for determining the likelihood to vote for either party (Republican or Democrat), which includes race/ethnicity, income, age, gender, geographical location (urban, suburban, or rural), and educational attainment. The voting history is based on a precinct-by-precinct voting history in Congressional races, and has a heavy weight on the election simulation.
The current version of my research paper can be found here.
A demonstration of my software can be found here.
Abstract
Optical Character Recognition (OCR) is an important technology in computer vision and pattern recognition that recognizes text embedded in images. Although the OCR achieved high accuracy for languages with alphabet-based writing systems, its performance on handwritten Chinese text is poor due to the complexity of the Chinese writing system. In order to improve the accuracy rate, this paper proposes an integrated OCR model for Chinese handwriting that combines existing methods in the pre-processing phase, recognition phase, and post-processing phase.
Software Architecture Diagram
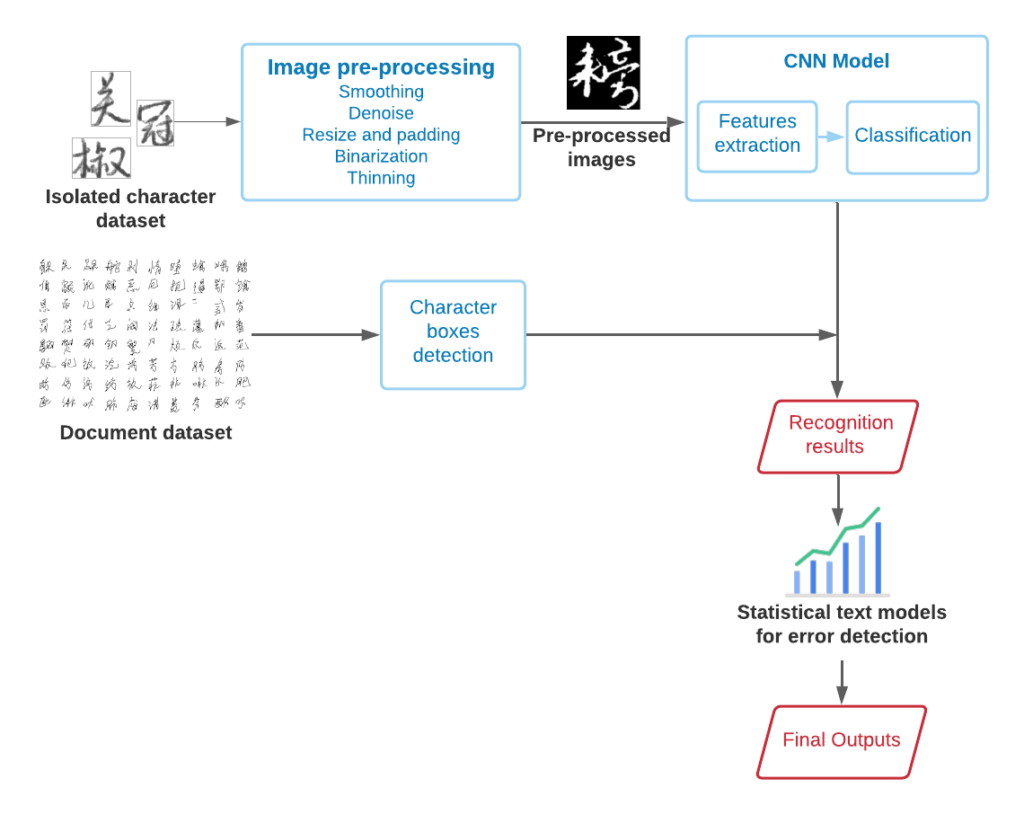
Abstract
Modern internet architecture faces the challenge of centralized services by big tech companies, which capitalizes on the users’ information. Most of the well-known chat services at the moment have to depend on a third party server which stores the users’ conversation. We also have to face the challenge of regulation, and government authorization. To solve this problem, we propose a peer to peer architecture for video chat that is private to the people involved in the conversation.
Link paper: https://drive.google.com/file/d/1RLIgvjrtHJrrZsttzxtxxppFCcdex85x/view?usp=sharing
Link demo: https://www.youtube.com/watch?v=9AcGwwbwukY
Optical Character Recognition (OCR) is an important technology in computer vision and pattern recognition that recognizes text embedded in images. Although the OCR achieved high accuracy for languages with alphabet-based writing systems, its performance on handwritten Chinese text is poor due to the complexity of the Chinese writing system. In order to improve the accuracy rate, this paper proposes an integrated OCR model for Chinese handwriting that combines existing methods in the pre-processing phase, recognition phase, and post-processing phase.