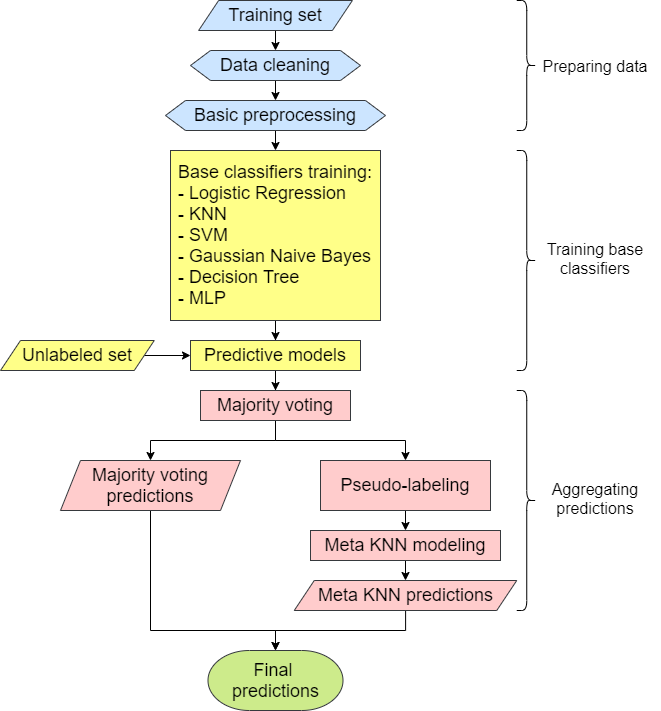
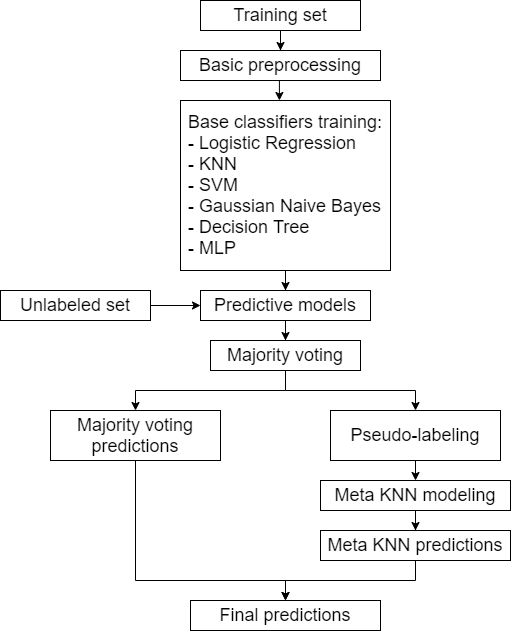
A new voting ensemble scheme
- Voting is a popular technique in Machine Learning to aggregate the predictions of multiple models and produce a more robust prediction. Some of the most widely used voting schemes are majority voting, rank voting, etc. I hope to propose a new voting system that particularly focuses on solving the issue of overfitting by using the non-conflict data points to inform the prediction of data points where conflict does arise.
- Evaluation:
- Compare its overall performance with that of the popular voting schemes
- Examine ties → see if it’s better than flipping a coin
- Apply statistical hypothesis testing to these analyses
- Possible datasets to work with:
- Any dataset whose target is categorical (i.e. it’s a classification problem). Preferably, the features are numerical and continuous.
Comparing the performance of the different Hyperparameter Tuning methods
Hyperparameter Tuning is an important step in building a strong Machine Learning model. However, that the hyperparameter space grows exponentially and the interaction among the hyperparameters is often nonlinear limits the number of feasible methods to come up with a more optimal set of hyperparameters. I plan to examine some of the most common methods that are often used to tackle this problem and compare their performance:
- Grid Search
- Random
- Sobol (hybrid of the two aforementioned methods)
- Bayesian Optimization
To many people’s surprise, the Random brute-force technique sometimes outperforms the Grid Search method. My project aims to verify this claim by applying the techniques above to a range of benchmark datasets and prediction algorithms.
The referee classifier
This is another Voting ensemble scheme. We pick out the classifier that performs the best under conflict and give it the role of the referee to solve “dispute” among the classifiers. The same principle can be used for breaking ties but we can also try removing the classifier that performs the worst under conflict.
We can try out a diverse set of classification algorithms like Decision Tree, Support Vector Machine, KNN, Naive Bayes, Logistic Regression, etc. and run them on the benchmark datasets from UCI. This proposed voting scheme can then be compared against the more common Simple Majority Voting Ensemble approach in terms of accuracy and other performance metrics.