This week I accomplished these tasks:
-found the rest of my 15 sources for my paper
-Met with Xunfei to discuss my design outline
-wrote my project proposal
-Did a second pass of a few of my papers
This week I accomplished these tasks:
-found the rest of my 15 sources for my paper
-Met with Xunfei to discuss my design outline
-wrote my project proposal
-Did a second pass of a few of my papers
Worked on my final paper some more, as well as familiarizing myself with my two-node blockchain set-up. I’m still working out how to integrate my other modules into the system, particularly how to pass a function from one server to another through the chain, but I am making progress and anticipate that I will be finished with that tomorrow at the latest. I’ve taken a glance at how my poster will be set-up, but it’s been a tertiary concern for the past few days.
This week I just worked on writing the first draft of my proposal. Found several additional papers to bring myself up to the requirement and fleshed out my idea for what I want to do in a bit more detail. The new papers provided insight on several other computer vision algorithms that I might be able to use, time allowing. Got notes and incorporated those changes into my draft. Built a diagram for my proposal.
This past week, I did my literature review presentation and got caught up with class assignments. I also created a framework for my project and obtained the Arduino air pollution sensor I will use so I can start testing that. I did I third pass on some of my most important sources and I am 85% ready for the proposal.
For the first half of the last week, I was working on the first draft of the paper. Since then, I have been working on getting the exhaustive search working. It has been a struggle. I was trying to implement a pipeline between the classifier and feature extraction tools. However, this seems to be incompatible with data structures I have been using. As a result, I have decided to not use the pipeline, but rather do the exhaustive searches separately for the classifiers.
On the other hand, I have started working with the Open American National Corpus. I should have labeled data in the next two weeks at a maximum.
Finally, I started working on an outline for the poster.
At this point, since I’m still having issues with DrawString, I decided to start looking into alternative options. My adviser recommended that I look into Tkinter again, but after some playing around with it and digging into it, I learned that Tkinter is fundamentally incompatible with NVDA because it does not produce accessible content. wxPython is often used to make NVDA-related GUIs, so I looked into that some but I don’t think it will let me make quite what I want to, so I’ve decided to back up and change plans slightly. I’m going back to the idea of just creating a clean-as-possible transcript of what information NVDA is able to gather when it’s running and developing a script completely outside of NVDA that can take that transcript and create a visual representation from it. I’ve started working on the transcription script and will hopefully have that done by the end of the week so that over the weekend I’ll be able to get a visualization together and ready to present.
Worked on completing the frontend. I have decided to use my local machine for hosting flask and have made progress on the backend. I still need to fix Database issues but progress this week has been significant. I have just received feedback from Xunfei on my project and will be working on it this week. A look at my front end:
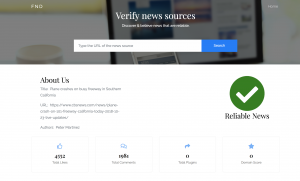
I have decided to go with the Database Akumuli. My reasoning behind this is both because of the index structure it uses along with it’s documentation. This data base clearly states in the README that it uses a combination of an LSM tree and B+ tree. These also happen to be trees that are very well researched and it is easy to become well informed about these trees. Other databases I’ve looked at, for example InfluxDB, while very well documented, uses it’s very own specific tree that was created specifically for this database. Therefore, it is more difficult to learn about it. Akumuli also has a page where it describes it’s index structure, https://akumuli.org/akumuli/2017/04/29/nbplustree/. Furthermore, I have cloned the repository and looked at the index source code. It is in C plus plus, a language I am not as familiar with, but I have used it once or twice. This code was well organized and well commented. For the index the programmers used a boost property tree. While I couldn’t find very much documentation about the property on boost, Akumuli is good at explaining the functionality of the tree. On Thursday I met with Xunfei, who gave me some helpful advice as to where to focus my efforts to be prepared for the proposal. One of these areas includes preliminary testing of the database. At this point I do not have that time at my disposal, seeing as I have just spent a lot of time and effort finding and choosing this database. This requires learning how to use the database and figuring out a testing environment along with finding datasets. Often ingesting datasets into a database can be very time consuming. However, the documentation of Akumuli does include some details and figures about it’s performance. I am in a good spot. I have a solid direction to go in. While there are still some things I need to do, I am only at the first draft stage of the proposal, so there is still time to do things and include them in my final proposal.
I reviewed more papers over the week to get a better sense of what I would need to address in my proposal. I also met with Xunfei and discussed the structure of my project as well as how to work with some of the shortcomings of an RFID system
Worked on the front end component of the project. With the sys admin telling me that they cannot host flask for my project. I started to look for alternatives. Heroku could not be used as it did not provide support for sci-kit the way I needed. Worked with Ajit to edit my first draft paper. Mades some figures of the architectures.
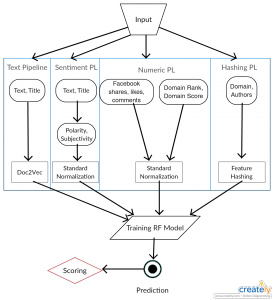
During the past week, I have mostly worked on the first draft of the paper. I did a quick review with Dave on Monday. Then, I reworked on the paper based on the suggestions from Dave.
I have also worked on the coding aspect. I am almost done with implementing the exhausting grid search for hyperparameter tuning for the classifier and the feature extraction tools. The results of the grid search should improve the overall performance of the system.
I am also close to deciding on the corpus that will be used for the experiments. Once I have that, getting the results should be relatively straightforward.
I have successfully set up a blockchain system, and run experiments to familiarize with how it works and the involved processes. My first draft of the paper is mostly complete and will be ready by the deadline tonight. It will not be a complete paper, as the evaluation and conclusion sections will be mostly empty. Advice and consultation from Ajit on the paper is making me restructure some things, and has given me a better reference point for what is required and expected. The paper right now also does not have direct citations to any of the references, as the documentation on how that part works is confusing me. I decided to move that part of the work to the second draft.
I found this function to create a font and played around with it until I had a version that was recognized by the GdipDrawString function. Now I have code that compiles without errors and causes no runtime errors, but the text is still not displaying (or maybe just not displaying how & where I thought it should). So I still need to play around with that problem, but at least I know that I have found a function that produces the right type of thing to pass to GdipDrawString.
I spent quite a bit of time this week drafting my paper and sent a rough draft to my adviser Friday. He responded quickly enough that I was able to make revisions before submitting a draft for grading. Overall I’m happy with the way the paper is shaping up.
I have been taking notes and learning about different tree indexing structures. I currently have 6 pages of notes and understand How R trees work and how X trees uses techniques from both R trees and B trees. I need to go further into detail and learn about R* tree and the X tree along with the LSW tree along with others. I have also started looking into which database to use for my project. I need a database that uses R or R* trees. I am doing this by downloading a database’s source from github and looking into the code using tools such as searches. I am starting by looking into the database InfluxDB. The documentation for this database seems adequate, so it is a good option.
After filtering through many different project ideas, I finally decided to create an aesthetically pleasing data visualization of pollution on Earlham’s campus. I have written a literature review of 15 sources on all of data visualizations, artistic factors that influence them, pollution health effects and awareness of them, as well as multiple projects that use Arduino to collect and display pollution data.
This week I finished writing the literature review and looking in depth into the literature available for my two topics: RFID in library and Sentiment analysis for stock prediction. I believe I will proceed with RFID technology and research more about the resources and different components of the system.
Finished the machine learning pipeline with actual experimentation. Having issues getting Flask setup and have been in touch with the SysAdmins. Halfway through the first draft of the paper. Made new design for the system architecture.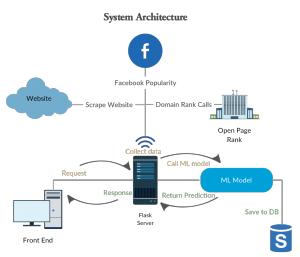
I am still in the process of writing my literary reviews. I have completed one and the second I am currently outlining. I am learning a lot of new information with my new sources. Since I know which of the two topics I will be choosing, I am using the second literary review, which is on a related topic to learn more background on the general area that these two topics are in. The most challenging feat I am facing currently is accessing book sources through the ACM website.
This week I filled out the quiz and started looking into what resources I’ll need for my project, image stitching. At the least I’ll need openCV, but probably imageMagick as well. Starting to think about how I should organize my project, and looking into how easy or hard parallelizing my procedure will be. A few of the papers I read referenced open image libraries they used and I’m thinking about looking into how hard it will be to get access to those.
For the past week, I have been looking at some available corpora found online. I was able to get one for free, namely the Open American National Corpus. It seems like it might be a better fit than the Blogs corpora. In the meantime, the TSVM is working and I have been getting some basic results. I have started working on implementing an exhaustive grid search to find the best parameters for the TSVM. I have also worked on the first draft of the paper, which is due next week. I am hoping to get the results from the grid search before Wednesday, so I can add those to the paper.
Last week I was able to set-up a two node blockchain on the Earlham Cluster, after working through technical issues with the help of Craig. However, I discovered several problems with this structure this week. I couldn’t re-access an already created chain, and getting nodes to connect to it was giving me errors. Unfortunately I had spent the Thursday and Friday of that week working on my draft and module designs, so by the time I encountered the problem I wasn’t able to meet and discuss with Craig until Monday. We talked about it and are working on solving the issue together, but he said he needs to poke around and look at things in the cluster. I tried experimenting with the issue on my end, using the program on my desktop and laptop computer, as well as ssh-ing into the servers, and have had little results to show for it.
This week I dedicated my time towards designing my proposal idea. After my literature review I decided I wanted to continue my audiovisual project. I read through the documentation for the jitter programming language to see what would be feasible to work on. Then I designed a basic architecture for how the synthesizer would convert MIDI note messages into visuals.
This week I’ve focused primarily on drafting my final paper. So far I have a general outline of my paper (abstract –> introduction –> related work –> framework and design –> implementation –> conclusions and future work), and I’ve fully drafted the abstract, introduction, and related work sections. I have a clear idea of what I want to go in each of the other sections, so I should be able to have those sections fully drafted by this time next week.
In terms of the software development component of the project, I almost have a complete (although not especially fancy or sophisticated) visualization tool, but I have spent most of the last week making lots of progress at getting nowhere. All I absolutely need at this point is to figure out how to make a call to the function GdipDrawText, but because gdip is the way python handles GDI+ — a component of .NET made to work for C, C++, and C#, the documentation on it is fuzzy and somewhat sparse. I still have a couple of ideas to try, though, and I’m trying to find people who have experience using it.
I did an experimentation with Sci-kit Learn. The run-time for the program was more than 2 hours. Testing the multiple dataset has been an issue lately.
Progress on the draft of the paper. Related works is almost completed.
This week I am writing my literary review for Indexing Time Series Databases. It is going well. Because this is an area that has been researched for over two decades there is a lot of background information I will be covering in this literary review. I have been focusing on Time Series Database Indexing as a whole rather than a specific database. Since I am feeling confident about going in this direction with my senior projects, my next steps after completing the literary review includes researching specific databases and looking at the road maps for these individual Time Series Databases to know at what development stage each database is at and if it fits the criteria for a database I am looking for.
This week I made good progress in my research. Here are some of the things I have done:
-Met with Forrest Tobey to discuss his past research involving motion tracking virtual instruments as well as visual capabilities of the Max/MSP/Jitter programming language
-Condensed my research papers that I will be using and selected 8 for each literature review
-worked extensively on writing my literature reviews
Making heavy headway into literature review, but still adjusting to overleaf. My final topics are predicting matches in the premier league, and making a software that combines several CV methods in a robust wrapper for easy use. Found eight sources for both topics. Found surprisingly little continuity in methods predicting futbol games.
Last week I was having a problem with a deprecation warning. I looked into that and I thought I fixed it. It seemed to be working fine, but I got the same error at a different point. So I am just ignoring the warning for now. This lead to getting the TSVMs working and getting some results. For the next step, I intend on getting bigger datasets and also looking at the available corpora. I am currently considering the Corpus of Contemporary American English.
Moreover, I reread my last year’s proposal and started to prepare to work on the first draft of the paper.
This week I started playing around with creating the visualization tool piece of my project. In doing that, I learned a lot of the more finicky details of NVDA. It uses an internal installation of Python, which makes sense for users because they don’t need to already have Python installed on their machine to use NVDA. However, this makes installing packages more difficult and requires basically copying and pasting the contents of the package into a directory within the NVDA set up so that its installation of python can use it. To test small changes I want to make, I’ve found the NVDA Python console to be really helpful, but it’s only accessible when NVDA is running which can sometimes slow down the testing process. Overall, I feel like this project has gotten me really into the weeds and I’ve begun identifying specific problems in the way NVDA tries to go about reading this type of content, but I’m not entirely sure of what solutions would best fit with the existing NVDA structure.
Worked on the first draft of the paper. Focusing on the related works and findings currently.
After talking to Ajit about the problems I have been running into with my virtual machines I’ve made the decision to switch to using the Earlham servers for the purpose of running my experiments and collecting data. There’s only one thing that still needs to be worked out and I intend to talk to Ajit about it. Due to poor sleep and bad time management over the last few days I am not as far as long as I should be, and I have not been able to run experiments yet. I will move correct this in the coming weeks and aim to catch back up to the work.
In the past week, I have been working on the related for my three project ideas. I wrote an annotated bibliography for each topic with five different sources. This week got rid of one of the ideas and decided to work on these two:
Prepared a presentation for class on my final two topics, image stitching and predicting premier league games. Started searching for additional topics so I can meet the 8 requirement for the imminent lit review.
I found some quirks and issues with the way NVDA works in different settings. I can now get a transcript with the appropriate details by using object review mode in Firefox, but not by navigating the objects normally or while in Chrome. This gets at the issue of “not knowing what you don’t know” and screen reader users needing to have significant experience and ideas of how to work around poorly designed web layouts. Because at this point I don’t believe there’s an easy way to generalize the automatic transcript making and restructuring process, I think identifying these issues and barriers and creating example demonstrations may be the best end result for my project at this point.
Continuing from last week, I was able to change the implementation of the Scikit-Learn wrapper for TSVM from Python2 to Python3. I am currently getting a new deprecation warning caused by TSVM. It seems like the code for TSVM assumes I am using an older version of Numpy. For this week, I plan to look more into that so I can figure out how to solve the issue.
I have randomly generated a sample from the Blogs corpora and during this week(as well as the next one) I will manually label it. Moreover, I plan on rereading my proposal to determine the parts which are going to be useful in my final paper.